jeggers/crosswords
收藏Hugging Face2024-02-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/jeggers/crosswords
下载链接
链接失效反馈官方服务:
资源简介:
Cryptic Crossword Clues数据集由George Ho创建,最初是一个练习网络爬虫和数据处理的个人项目,后来发展成为全球填字游戏解谜者和构造者的资源。数据集包含已发布的填字游戏中的多个谜题线索,每条记录代表一个谜题线索,包含线索、答案、定义、谜题日期、谜题名称、来源URL和来源等字段。数据集遵循Open Database License,允许共享和改编,但要求在使用时注明来源。数据集定期更新,但不维护版本控制。
Cryptic Crossword Clues数据集由George Ho创建,最初是一个练习网络爬虫和数据处理的个人项目,后来发展成为全球填字游戏解谜者和构造者的资源。数据集包含已发布的填字游戏中的多个谜题线索,每条记录代表一个谜题线索,包含线索、答案、定义、谜题日期、谜题名称、来源URL和来源等字段。数据集遵循Open Database License,允许共享和改编,但要求在使用时注明来源。数据集定期更新,但不维护版本控制。
提供机构:
jeggers
原始信息汇总
数据集概述
数据集简介
该数据集包含多个已发布的填字游戏中的谜语线索。由George Ho创建,旨在帮助填字游戏解题者和构造者理解过去的线索和答案的使用情况。
数据集内容
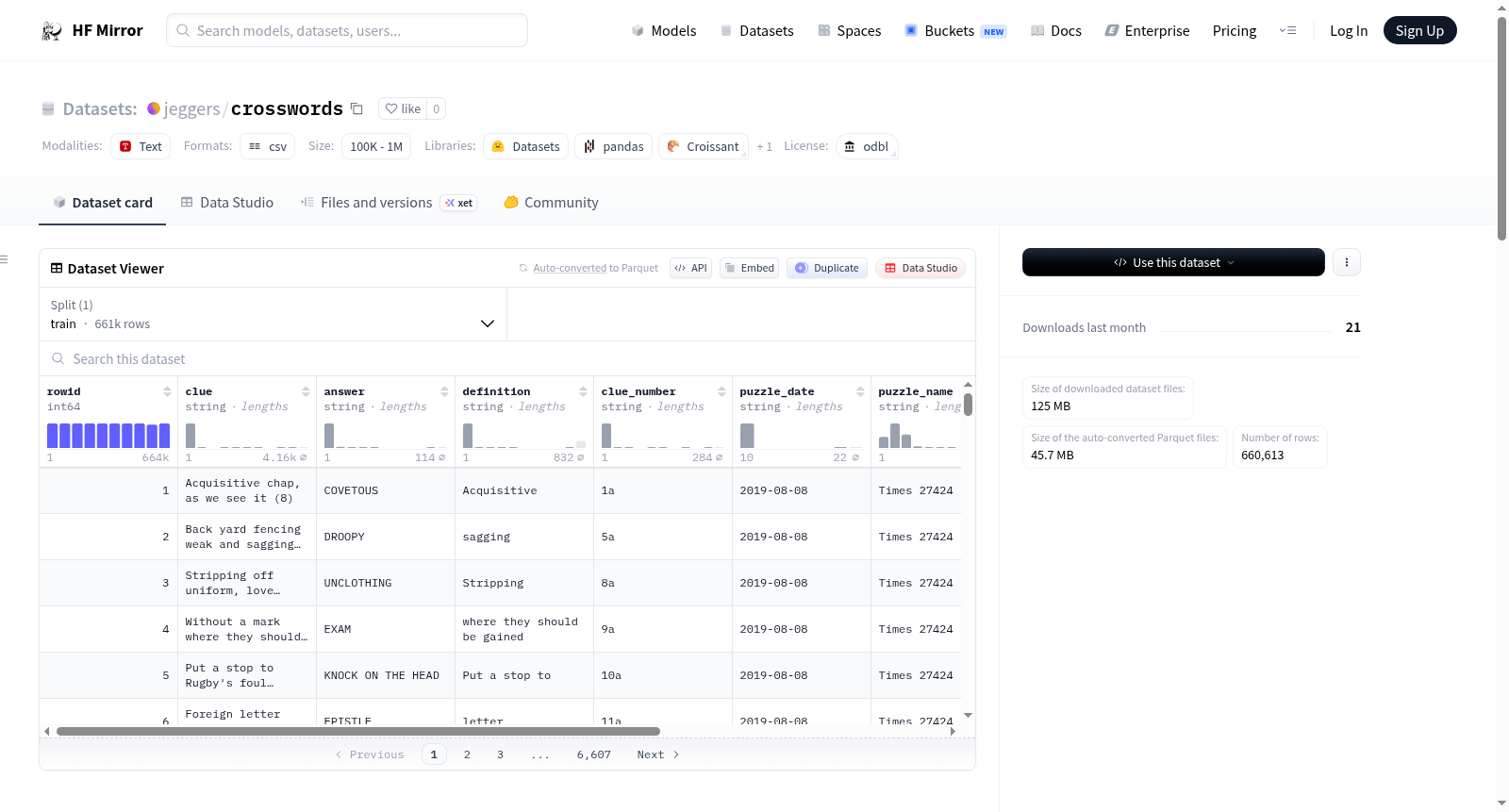
每行数据代表一个已发布的填字游戏中的谜语线索。数据集包括以下字段:
clue:谜语线索,例如:Labourers going around spotted tools (8)。answer:谜语答案,例如:HANDSAWS。definition:答案的定义,例如:tools。clue_number:线索在特定填字游戏中的编号,例如:17a。puzzle_date:谜题发布日期,格式为yyyy-mm-dd,例如:2017-08-25。puzzle_name:谜题的出版物和/或名称,例如:Quick Cryptic 904。source_url:线索来源的博客文章URL,例如:https://times-xwd-times.livejournal.com/1799231.html。source:线索来源的博客,例如:times_xwd_times。
数据集更新
数据集定期更新以包含新发布的博客文章和填字游戏,但更新过程是手动的,没有固定的时间表。
数据集许可
该数据集根据开放数据库许可(Open Database License)发布,允许共享和改编数据库,但要求用户在使用数据库或其衍生作品时注明出处。
搜集汇总
数据集介绍
构建方式
在自然语言处理与游戏智能交叉领域,jeggers/crosswords数据集通过系统性的网络爬取与数据清洗流程构建而成。该数据集源自公开的加密填字游戏博客与数字档案,采用手动与自动化相结合的方式,从多个权威来源持续采集已发布的谜题线索。每条数据记录代表一个独立的加密填字线索,涵盖线索文本、答案、定义及出版元数据,并通过定期更新机制纳入新发布的谜题内容,确保了数据集的时效性与覆盖面。
特点
该数据集以其在加密填字游戏领域的专业性与结构性著称,每条记录均包含线索、答案、定义及详尽的出版元数据,如谜题日期、名称与来源链接。其设计兼顾了语言学特征与游戏逻辑,为分析加密填字中的语义双关、词汇构造与谜题模式提供了多维视角。尽管部分字段可能存在缺失,但数据集整体覆盖了广泛的历史与当代谜题来源,为研究者与爱好者提供了近乎完备的参考资源。
使用方法
在应用层面,该数据集适用于自然语言理解、谜题生成与游戏人工智能等研究方向。用户可通过解析线索与答案的对应关系,训练模型识别加密填字中的隐喻与双关结构;亦可利用出版元数据进行时序或来源分析,探索谜题设计的演变趋势。数据集以标准表格格式提供,支持通过Datasette平台直接访问,并鼓励在遵守开放数据库许可的前提下,将其用于非商业学术研究或创意项目开发。
背景与挑战
背景概述
在自然语言处理与计算语言学领域,谜题解析任务长期被视为评估模型语义理解与创造性推理能力的重要基准。jeggers/crosswords数据集由George Ho于个人项目中创建,最初旨在练习网络爬虫与数据处理技能,随后演变为全球密码填字游戏解谜者与构建者的关键资源。该数据集汇集了已发布密码填字游戏中的大量线索,覆盖广泛的博客与数字档案,为核心研究问题——即如何通过历史线索模式辅助解谜与构造——提供了实证基础,对语言游戏、人工智能推理及文化遗产数字化等领域产生了深远影响。
当前挑战
该数据集致力于解决密码填字游戏自动解析与生成的领域挑战,其核心在于模型需同时处理语言的双关、隐喻及结构暗示等多重语义层次。构建过程中,由于数据源自分散的网络博客,面临版权限制与字段缺失的困扰,导致部分信息不完整或存在噪声;同时,手动更新机制缺乏版本控制,可能影响数据的持续可追溯性与一致性。
常用场景
经典使用场景
在自然语言处理领域,该数据集为研究语义解析和词义消歧提供了宝贵的实验资源。通过分析谜面与答案之间的复杂映射关系,学者们能够深入探索自然语言中隐含的语义结构和逻辑关联,从而推动语言理解模型的发展。
衍生相关工作
基于该数据集,学术界衍生出了一系列关于自动谜题生成和语义推理的经典研究。这些工作不仅探索了如何利用机器学习算法模拟人类解谜过程,还进一步推动了在创意写作和认知计算领域的交叉应用,为人工智能在创造性任务中的表现提供了新的视角。
数据集最近研究
最新研究方向
在自然语言处理领域,jeggers/crosswords数据集作为加密填字游戏线索的集合,正推动着语言理解与生成模型的前沿探索。当前研究聚焦于利用该数据集训练模型解析双关语、隐喻及文化典故,以提升人工智能在复杂语义推理和创造性问题解决方面的能力。热点事件包括将此类数据集应用于大型语言模型的微调,以增强其逻辑推理和上下文关联性,这在人机交互和智能教育系统中具有显著意义。该数据集不仅为语言学分析提供了丰富语料,还促进了跨领域研究,如认知科学中人类谜题解决机制的模拟,对推动自然语言处理向更深层次理解迈进产生了深远影响。
以上内容由遇见数据集搜集并总结生成


