claude-sonnet-4.6-merged
收藏数据集概述
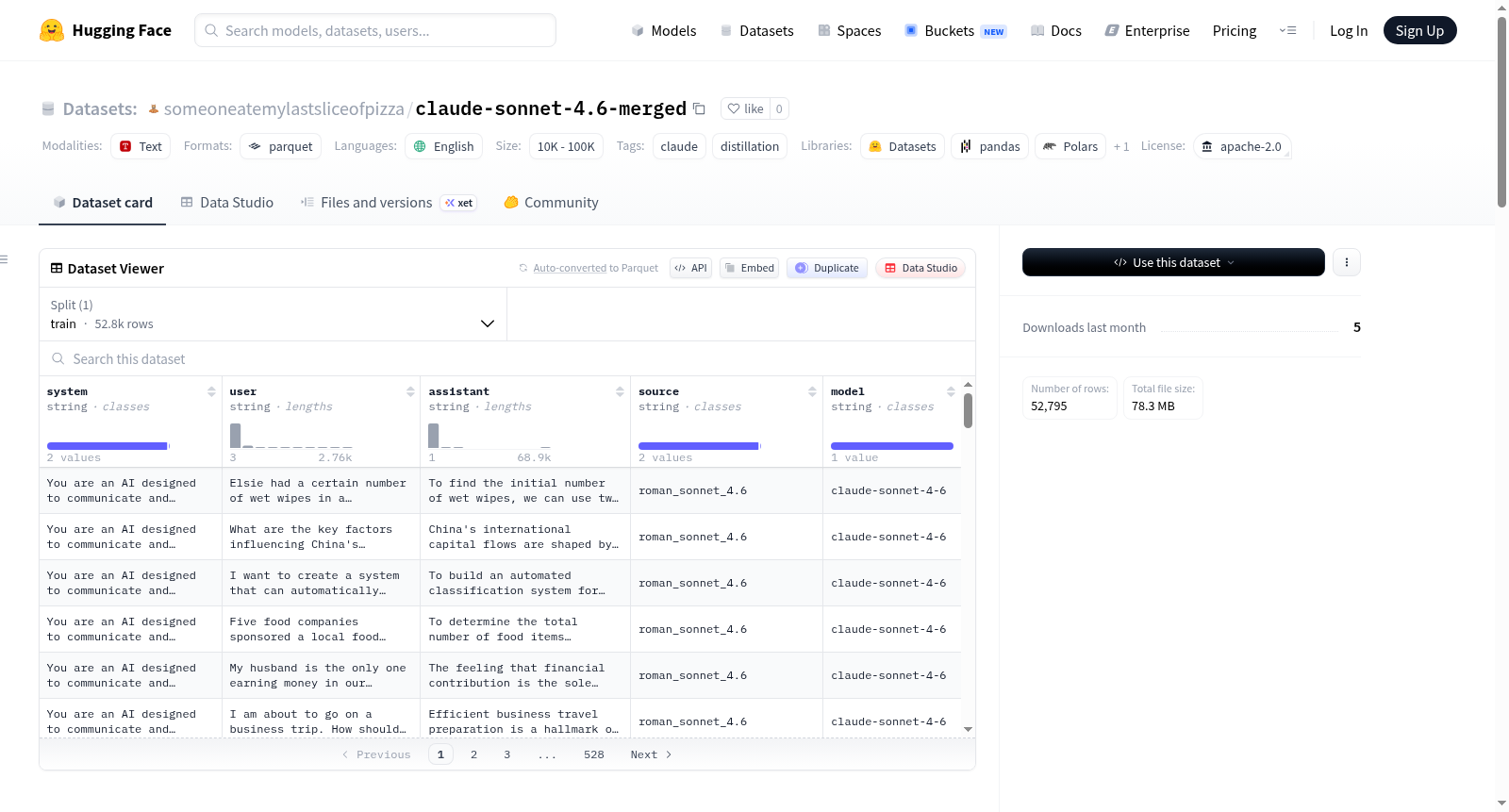
Claude Sonnet 4.6 — Merged SFT Dataset 是一个合并并去重后的蒸馏数据集,来源于两个社区数据集。该数据集旨在用于基于 OpenAI 聊天格式的监督微调(SFT),适用于 Qwen3 等模型。
数据集规模统计
| 阶段 | 数据行数 |
|---|---|
| 合并后(去重前) | 53,897 |
| 去重后 | 52,795 |
| 最终上传量 | 52,795 |
去重依据:基于首轮用户消息(小写化、空白规范化后)的 MD5 哈希值。
数据列说明
| 列名 | 类型 | 描述 |
|---|---|---|
system |
字符串 | 系统提示(若缺失则为空字符串) |
user |
字符串 | 首轮用户消息 |
assistant |
字符串 | 首轮助手回复(可能包含“<think>”块) |
source |
字符串 | 来源数据集标识标签 |
model |
字符串 | 生成回复的 Claude 模型(claude-sonnet-4-6) |
数据来源
| 来源数据集 | 加载行数 | 筛选后行数 | 最终行数 | 筛选条件/说明 |
|---|---|---|---|---|
| Roman1111111/claude-sonnet-4.6-100000X-filtered | 76,812 | 52,801 | 51,701 | 评分筛选:yes 等级,且评分 ≥ 8.5 / 10 |
| TeichAI/Claude-Sonnet-4.6-Reasoning-1100x | 1,096 | 1,096 | 1,094 | 推理过程以“<think>”块形式嵌入 |
质量筛选条件
- 移除空值或空回复
- 基于规范化后的首轮用户消息哈希进行去重
- 检查助手回复:去除“<think>”块后,回复内容必须非空
- 丢弃“<think>”占位符行(如“...”或“…”)
使用示例
python from datasets import load_dataset
ds = load_dataset("someoneatemylastsliceofpizza/claude-sonnet-4.6-merged", split="train") print(ds[0])
{system: ..., user: ..., assistant: ..., source: ..., model: claude-sonnet-4-6}
Qwen3 微调示例:
python import json from datasets import load_dataset from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-4B")
def format_row(row): msgs = [] if row["system"]: msgs.append({"role": "system", "content": row["system"]}) msgs.append( {"role": "user", "content": row["user"]}) msgs.append( {"role": "assistant", "content": row["assistant"]}) return {"text": tokenizer.apply_chat_template(msgs, tokenize=False, add_generation_prompt=False)}
dataset = ds.map(format_row)
许可证
Apache-2.0
标签
claude, distillation
语言
英语