Semantic Shift Benchmark (SSB)
收藏arXiv2024-08-30 更新2024-09-02 收录
下载链接:
https://www.robots.ox.ac.uk/~vgg/research/osr/
下载链接
链接失效反馈官方服务:
资源简介:
Semantic Shift Benchmark (SSB) 是一个用于评估机器学习模型在语义偏移(Semantic Shift)下性能的大规模数据集。该数据集由香港大学和牛津大学的研究团队创建,旨在通过将ImageNet-1K视为已见闭集数据,而从ImageNet-21KP中精心挑选未见数据来模拟语义偏移。SSB数据集的创建过程涉及对不同分布偏移的细致分离,特别是语义偏移和协变量偏移。该数据集主要应用于机器学习模型的开放集识别和分布外检测任务,旨在提高模型对未知类别的识别能力和对分布偏移的鲁棒性。
Semantic Shift Benchmark (SSB) is a large-scale dataset designed to evaluate the performance of machine learning models under semantic shift. Developed by a research team from The University of Hong Kong and the University of Oxford, the dataset takes ImageNet-1K as seen closed-set data and carefully selects unseen data from ImageNet-21KP to simulate semantic shift. The construction of SSB involves meticulous separation of different distribution shifts, specifically semantic shift and covariate shift. This dataset is primarily applied to open-set recognition and out-of-distribution detection tasks for machine learning models, aiming to enhance models' ability to recognize unknown categories and their robustness against distribution shifts.
提供机构:
香港大学,牛津大学
创建时间:
2024-08-30
搜集汇总
数据集介绍
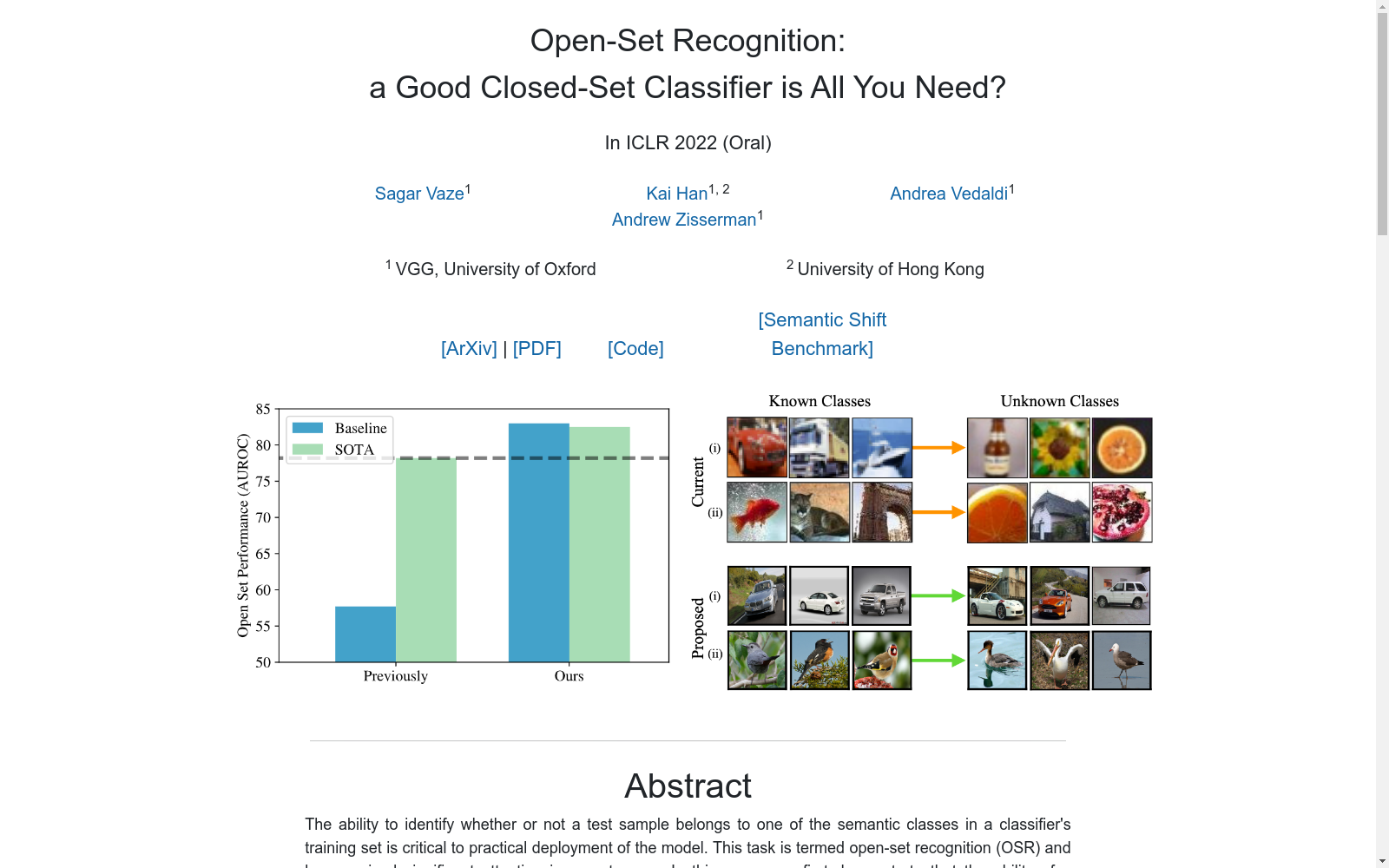
构建方式
Semantic Shift Benchmark (SSB) 的构建方式旨在隔离语义偏移,以便更好地理解和评估开放集识别 (OSR) 任务。该数据集基于 ImageNet-1K 数据集,将其中的一部分类别视为 'seen' 的闭合集数据,而 'unseen' 数据则精心挑选自 ImageNet-21KP 数据集的不同语义类别。这种设计使得 SSB 成为研究语义偏移的理想平台,因为它清晰地分离了语义偏移和协变量偏移,从而能够更准确地评估模型的性能。
特点
SSB 数据集的主要特点是它专注于语义偏移,这与传统的协变量偏移(例如图像质量变化)不同。这种专注于语义偏移的设计使得 SSB 成为一个独特且具有挑战性的数据集,它能够帮助研究人员和从业者更好地理解开放集识别任务中语义偏移的影响。此外,SSB 还提供了一个大规模的评估环境,这使得它成为评估模型在实际应用中性能的理想选择。
使用方法
SSB 数据集的使用方法涉及在 'seen' 类别上进行模型训练,然后在 'unseen' 类别上进行评估。这种评估过程旨在测试模型识别 'unseen' 类别的能力,即模型的开放集识别能力。研究人员可以使用 SSB 数据集来评估和比较不同的 OSR 方法,以及研究语义偏移对模型性能的影响。此外,SSB 数据集还可以用于研究如何提高模型在开放集识别任务中的鲁棒性和准确性。
背景与挑战
背景概述
Semantic Shift Benchmark (SSB) 是由香港大学和牛津大学的研究人员于2022年提出的一个大规模基准数据集,旨在探索和评估机器学习模型在面临分布偏移时的鲁棒性和识别能力。该数据集将分布偏移问题细分为语义偏移和协变量偏移,并提出了新的评估指标 'Outlier-Aware Accuracy' (OAA) 来衡量模型在检测协变量偏移和鲁棒性之间的权衡。SSB 数据集的提出对于理解机器学习模型在现实世界应用中的性能和局限性具有重要意义,并为相关领域的研究提供了新的视角和工具。
当前挑战
SSB 数据集在构建过程中所遇到的挑战主要包括:1) 如何有效地分离和评估语义偏移和协变量偏移;2) 如何选择合适的辅助数据来提高模型在 OOD 检测和 OSR 任务上的性能;3) 如何设计新的评估指标来更全面地衡量模型在面临分布偏移时的鲁棒性和识别能力。此外,SSB 数据集也面临着一些研究挑战,例如:如何提高模型在大型数据集上的泛化能力;如何更好地理解模型在面对不同类型分布偏移时的内部机制;以及如何将 SSB 数据集的应用扩展到更广泛的领域。
常用场景
经典使用场景
在机器学习模型中,测试时样本与训练集差异显著的情况时有发生,即模型可能会遇到测试时分布偏移的问题。为了解决这个问题,研究者们提出了两种主要的方法:分布外(OOD)检测和开放集识别(OSR)。Semantic Shift Benchmark(SSB)数据集旨在更好地分离这两种任务,以便更准确地评估模型在语义偏移和协变量偏移方面的表现。该数据集通过对ImageNet-1K和ImageNet-21KP中未见过类别的精心选择,为语义偏移提供了明确的评估标准。
解决学术问题
SSB数据集解决了OOD检测和OSR领域中常见的学术研究问题,即如何准确地识别和评估模型在处理分布偏移时的性能。通过分离语义偏移和协变量偏移,SSB为研究者们提供了一个更清晰、更准确的评估框架,有助于他们更好地理解模型在不同类型分布偏移下的表现,并为未来的研究提供了有价值的参考。
衍生相关工作
SSB数据集的提出引发了大量相关研究,如ImageNet-A和ImageNet-O等数据集的提出,旨在评估模型对非语义分布偏移的鲁棒性。同时,SSB还推动了新的评估指标和方法的提出,如Outlier-Aware Accuracy(OAA)等,这些指标和方法有助于更准确地评估模型在处理分布偏移时的性能。此外,SSB还为研究者们提供了一个更清晰、更准确的评估框架,有助于他们更好地理解模型在不同类型分布偏移下的表现,并为未来的研究提供了有价值的参考。
以上内容由遇见数据集搜集并总结生成


