webfaq-v2
收藏Hugging Face2026-02-13 更新2026-02-14 收录
下载链接:
https://huggingface.co/datasets/michaeldinzinger/webfaq-v2
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个多语言文本检索数据集,支持包括非洲语、阿拉伯语、中文、英语、法语、德语等在内的多种语言。数据集设计用于文本检索和文档检索任务,包含问题、答案、语义相似度评分等核心字段,部分语言配置还包含主题和问题类型等额外信息。每个语言配置提供了详细的统计数据,如字节大小和样本数量,适用于构建和评估多语言信息检索系统。
创建时间:
2026-02-12
原始信息汇总
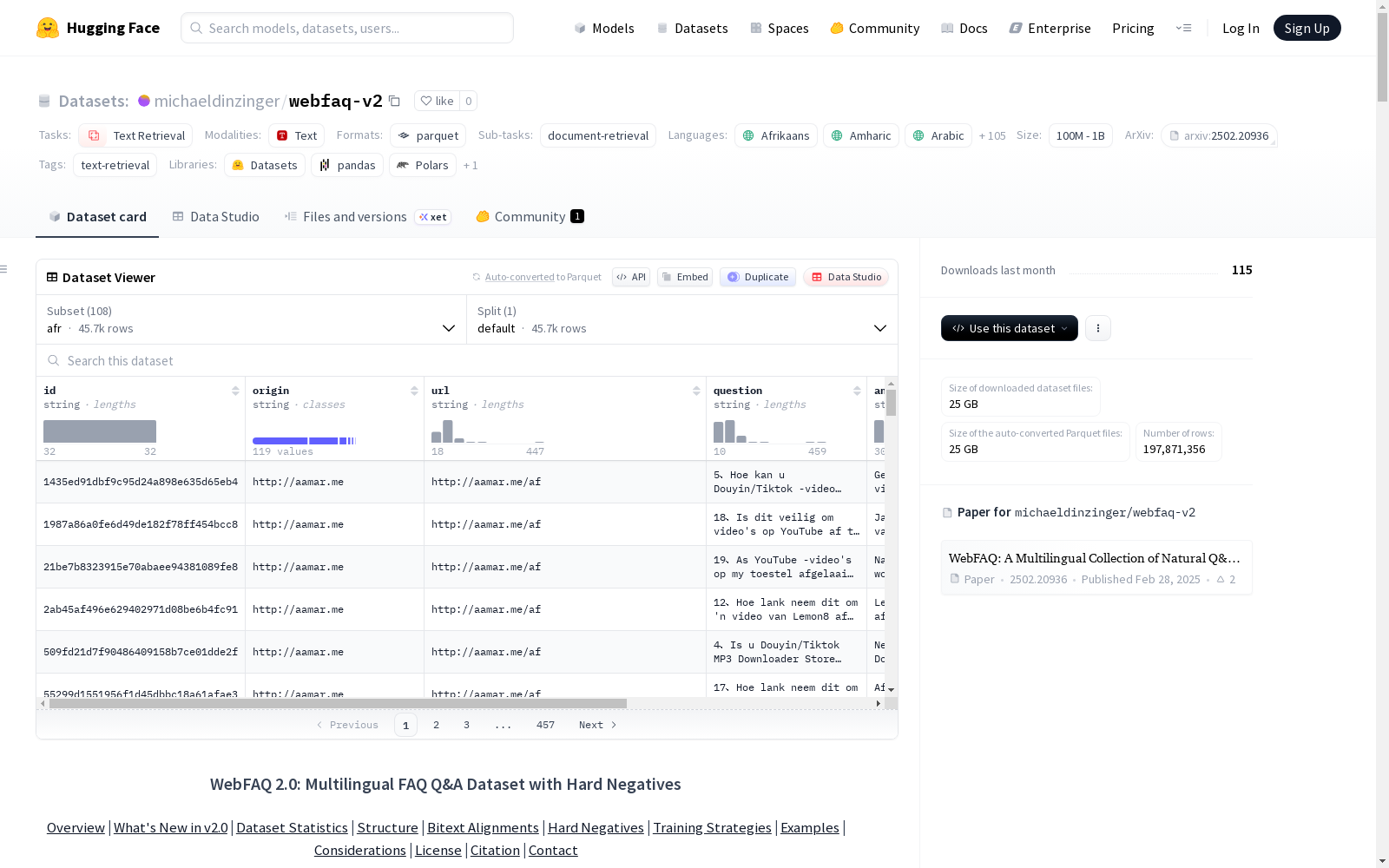
数据集概述:WebFAQ-v2
基本信息
- 数据集名称:WebFAQ-v2
- 托管地址:https://huggingface.co/datasets/michaeldinzinger/webfaq-v2
- 语言:多语言,涵盖超过100种语言,包括但不限于南非荷兰语、阿拉伯语、中文、英语、法语、德语、印地语、日语、俄语、西班牙语等。
- 多语言性:多语言
- 任务类别:文本检索
- 任务ID:文档检索
- 配置名称:语料库
- 标签:文本检索
数据结构与内容
数据集按语言分为多个配置,每个配置包含一个默认的数据分割。数据以问答对形式组织,核心字段包括问题、答案及相关元数据。
通用数据特征
大多数语言配置包含以下字段:
id:字符串类型,唯一标识符。origin:字符串类型,数据来源。url:字符串类型,原始网页地址。question:字符串类型,问题文本。answer:字符串类型,答案文本。semantic_similarity_score:浮点数类型,语义相似度分数。
扩展数据特征
部分语言配置额外包含以下字段:
topic:字符串类型,问题主题。question_type:字符串类型,问题类型。
数据规模统计(按语言示例)
以下是部分语言配置的数据规模示例:
| 语言代码 | 语言名称 | 数据量(示例数) | 数据大小(字节) |
|---|---|---|---|
| afr | 南非荷兰语 | 45,664 | 5,012,834 |
| amh | 阿姆哈拉语 | 52,694 | 6,103,497 |
| ara | 阿拉伯语 | 3,298,814 | 523,161,980 |
| arz | 埃及阿拉伯语 | 979 | 298,378 |
| asm | 阿萨姆语 | 12,239 | 1,625,907 |
| aze | 阿塞拜疆语 | 307,000 | 24,623,929 |
| bak | 巴什基尔语 | 185 | 28,339 |
| bel | 白俄罗斯语 | 23,476 | 3,395,301 |
| ben | 孟加拉语 | 106,979 | 23,903,697 |
| bos | 波斯尼亚语 | 50,300 | 5,160,832 |
| bre | 布列塔尼语 | 128 | 27,583 |
| bul | 保加利亚语 | 1,426,853 | 179,811,464 |
| cat | 加泰罗尼亚语 | 505,138 | 42,354,583 |
| ceb | 宿务语 | 20,292 | 2,073,237 |
| ces | 捷克语 | 3,026,405 | 323,621,713 |
| ckb | 库尔德语(索拉尼) | 12,372 | 1,383,270 |
| cym | 威尔士语 | 21,521 | 2,134,379 |
| dan | 丹麦语 | 3,512,676 | 486,144,873 |
| deu | 德语 | 14,460,734 | 2,006,719,868 |
| div | 迪维希语 | 12,205 | 1,540,538 |
| ell | 希腊语 | 1,845,571 | 220,268,305 |
| eng | 英语 | 55,264,290 | 7,047,493,542 |
| epo | 世界语 | 23,271 | 2,184,450 |
| est | 爱沙尼亚语 | 322,575 | 29,509,558 |
| eus | 巴斯克语 | 24,132 | 2,614,163 |
| fas | 波斯语 | 945,123 | 200,094,718 |
| fin | 芬兰语 | 1,754,586 | 192,893,815 |
| fra | 法语 | 12,840,362 | 1,601,326,911 |
| fry | 西弗里西亚语 | 20,534 | 2,014,308 |
| gla | 苏格兰盖尔语 | 18,677 | 1,897,864 |
| gle | 爱尔兰语 | 20,875 | 2,366,017 |
| glg | 加利西亚语 | 17,549 | 2,032,702 |
| gom | 孔卡尼语 | 10,810 | 1,401,160 |
| guj | 古吉拉特语 | 44,321 | 5,681,016 |
| hat | 海地克里奥尔语 | 14,845 | 1,461,573 |
| hbs | 塞尔维亚-克罗地亚语 | 30,712 | 3,834,862 |
| heb | 希伯来语 | 1,581,622 | 184,306,859 |
| hin | 印地语 | 2,583,369 | 325,941,081 |
| hrv | 克罗地亚语 | 1,339,654 | 125,098,814 |
| hun | 匈牙利语 | 2,024,130 | 204,356,519 |
| hye | 亚美尼亚语 | 44,771 | 5,339,705 |
| ilo | 伊洛卡诺语 | 12,244 | 1,091,598 |
| ind | 印度尼西亚语 | 2,847,090 | 301,002,400 |
| isl | 冰岛语 | 数据信息不完整 | 数据信息不完整 |
主要用途
本数据集适用于多语言文本检索任务,特别是文档检索,可用于训练和评估信息检索系统、问答系统及相关的自然语言处理模型。
搜集汇总
数据集介绍
构建方式
在跨语言信息检索领域,WebFAQ-v2数据集通过系统化的网络爬取与结构化处理构建而成。该数据集从全球范围内的常见问题解答页面中提取多语言问答对,涵盖超过一百种语言变体,每个条目均包含问题、答案、来源URL及语义相似度评分。构建过程中采用了自动化工具识别网页中的FAQ结构,并利用语义模型对问答内容进行质量评估,确保数据的多样性与可靠性,为多语言检索任务提供了丰富的训练资源。
使用方法
该数据集主要应用于多语言文本检索与问答系统开发,研究人员可通过HuggingFace平台按语言配置加载特定子集。典型使用场景包括训练跨语言检索模型、评估语义匹配算法,或分析不同语言间FAQ内容的分布特征。数据中的语义相似度分数可直接用于监督学习,而URL字段则支持溯源验证,为构建稳健的多语言信息检索系统提供了完整的数据基础。
背景与挑战
背景概述
在自然语言处理领域,多语言问答与检索系统的研究日益受到重视,WebFAQ-v2数据集应运而生。该数据集由研究社区于近年构建,旨在应对全球化背景下信息获取的语言壁垒问题。其核心研究聚焦于跨语言文档检索与问答任务,通过整合网络来源的常见问题对,覆盖了从阿非利卡语到中文等超过一百种语言,为多语言模型训练与评估提供了宝贵资源。这一大规模多语言语料库的建立,显著推动了跨语言信息检索技术的发展,使得模型能够更好地理解与响应不同语言用户的查询需求。
当前挑战
WebFAQ-v2数据集致力于解决多语言文档检索与问答任务中的核心挑战,即如何在不同语言间实现准确、高效的语义匹配与信息定位。构建过程中面临诸多困难,包括从多样化网络来源采集并清洗高质量问答对的复杂性,确保低资源语言数据量的充足性,以及跨语言语义相似性评分的标注一致性。此外,数据格式的统一与多语言文本的标准化处理亦需克服语言特性差异带来的技术障碍。这些挑战共同构成了数据集构建与应用的难点。
常用场景
经典使用场景
在信息检索与自然语言处理领域,webfaq-v2数据集以其涵盖逾百种语言的问答对结构,成为跨语言检索模型训练与评估的基石。该数据集通过整合网络常见问题与答案,为研究者提供了丰富的语义匹配实例,尤其适用于训练密集检索模型,以精准捕捉查询与文档间的语义关联。其多语言特性使得模型能够在全球范围内处理多样化的用户查询,推动了检索系统在复杂语言环境下的性能优化。
解决学术问题
该数据集有效应对了跨语言信息检索中数据稀缺与语义对齐的挑战,为低资源语言的研究提供了宝贵的数据支持。通过提供大规模、高质量的多语言问答对,它助力解决语义相似性计算、跨语言迁移学习以及多模态检索中的关键问题。其标注的语义相似度分数为评估检索模型的精确度提供了可靠基准,显著促进了多语言检索技术的理论进展与应用创新。
实际应用
在实际应用中,webfaq-v2数据集被广泛集成于智能客服系统、多语言搜索引擎以及在线教育平台,以提升问答匹配的准确性与响应效率。例如,企业可利用该数据集训练自动化客服机器人,实现跨语言用户咨询的即时解答;教育机构则能构建多语言知识库,为学生提供个性化的学习资源推荐。这些应用显著增强了全球信息服务的可及性与用户体验。
数据集最近研究
最新研究方向
在信息检索与自然语言处理领域,多语言问答数据集正成为推动跨语言智能系统发展的关键资源。WebFAQ-v2以其覆盖百余种语言的庞大规模,为研究多语言检索与语义匹配提供了丰富素材。当前前沿探索聚焦于利用该数据集训练跨语言稠密检索模型,以应对低资源语言的语义鸿沟挑战,同时结合预训练语言模型进行多语言问答生成与知识迁移。随着全球化数字服务的普及,这类研究助力构建包容性人工智能,促进语言多样性在技术应用中的平等体现,对提升多语言信息可及性具有深远意义。
以上内容由遇见数据集搜集并总结生成


