ylacombe/cml-tts
收藏数据集卡片 CML-TTS
数据集描述
数据集摘要
CML-TTS 是一个多语言文本到语音(TTS)数据集,由联邦大学戈亚斯(UFG)的人工智能卓越中心(CEIA)开发。该数据集包含从古腾堡计划(Project Gutenberg)的公共领域书籍中提取的音频书籍,由 LibriVox 项目的志愿者朗读。数据集包括荷兰语、德语、法语、意大利语、波兰语、葡萄牙语和西班牙语的录音,所有录音的采样率为 24kHz。
支持的任务
text-to-speech,text-to-audio: 该数据集可用于训练文本到语音(TTS)模型。
语言
数据集包括荷兰语、德语、法语、意大利语、波兰语、葡萄牙语和西班牙语的录音,所有录音的采样率为 24kHz。
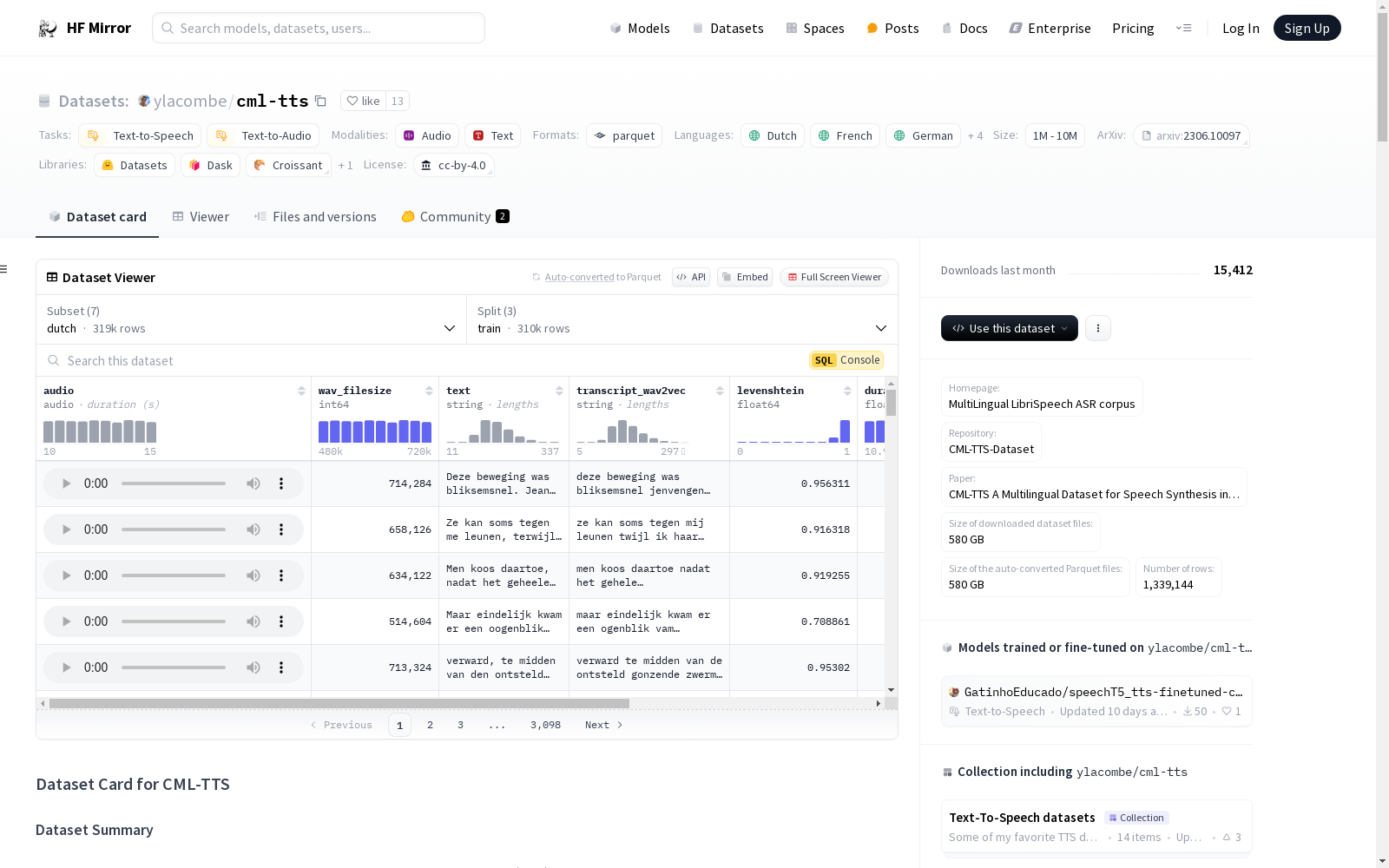
数据集结构
数据实例
一个典型的数据点包括音频文件的路径、转录文本、说话者信息和其他相关信息。
json { "audio": {"path": "6892_8912_000729.wav", "array": [...], "sampling_rate": 24000}, "wav_filesize": 601964, "text": "Proszę pana, tu pano... zdziwiony", "transcript_wav2vec": "proszę pana tu panow... zdziwiony", "levenshtein": 0.96045197740113, "duration": 13.648979591836737, "num_words": 29, "speaker_id": 6892 }
数据字段
audio: 包含音频文件名、解码后的音频数组和采样率的字典。text: 音频文件的转录文本。speaker_id: 说话者的唯一标识符。transcript_wav2vec: 使用 wav2vec 模型的音频文件转录文本。wav_filesize: 音频波形文件的大小。levenshtein: wav2vec 转录文本与原始转录文本之间的 Levenshtein 距离。duration: 音频的持续时间(秒)。num_words: 转录文本中的单词数量。
数据分割
| 语言 | 训练集样本数 | 开发集样本数 | 测试集样本数 |
|---|---|---|---|
| 荷兰语 | 309785 | 4834 | 4570 |
| 法语 | 107598 | 3739 | 3763 |
| 德语 | 608296 | 5314 | 5466 |
| 意大利语 | 50345 | 1765 | 1835 |
| 波兰语 | 18719 | 853 | 814 |
| 葡萄牙语 | 34265 | 1134 | 1297 |
| 西班牙语 | 168524 | 3148 | 3080 |
数据统计
| 语言 | 训练集时长 (小时) | 测试集时长 (小时) | 开发集时长 (小时) | 训练集说话者数 | 测试集说话者数 | 开发集说话者数 |
|---|---|---|---|---|---|---|
| 荷兰语 | 482.82 | 2.46 | 2.24 | 8 | 3 | 2 |
| 法语 | 260.08 | 2.48 | 3.31 | 25 | 8 | 10 |
| 德语 | 1128.96 | 3.75 | 4.31 | 78 | 13 | 13 |
| 意大利语 | 73.78 | 1.47 | 0.40 | 23 | 5 | 4 |
| 波兰语 | 30.61 | 0.70 | 0.56 | 4 | 2 | 2 |
| 葡萄牙语 | 23.14 | 0.28 | 0.68 | 20 | 5 | 6 |
| 西班牙语 | 279.15 | 2.77 | 3.40 | 35 | 10 | 11 |
| 总计 | 3176.13 | 28.11 | 29.19 | 424 | 94 | 95 |
数据集创建
数据集来源
数据集的音频书籍来自古腾堡计划(Project Gutenberg)的公共领域书籍,由 LibriVox 项目的志愿者朗读。
个人和敏感信息
数据集包含在线捐赠语音的人。您同意不尝试确定此数据集中说话者的身份。
使用数据的注意事项
数据集的社会影响
[需要更多信息]
偏见的讨论
[需要更多信息]
其他已知限制
[需要更多信息]
附加信息
数据集许可信息
公共领域,Creative Commons Attribution 4.0 国际公共许可证(CC-BY-4.0)
引用信息
@misc{oliveira2023cmltts, title={CML-TTS A Multilingual Dataset for Speech Synthesis in Low-Resource Languages}, author={Frederico S. Oliveira and Edresson Casanova and Arnaldo Cândido Júnior and Anderson S. Soares and Arlindo R. Galvão Filho}, year={2023}, eprint={2306.10097}, archivePrefix={arXiv}, primaryClass={eess.AS} }