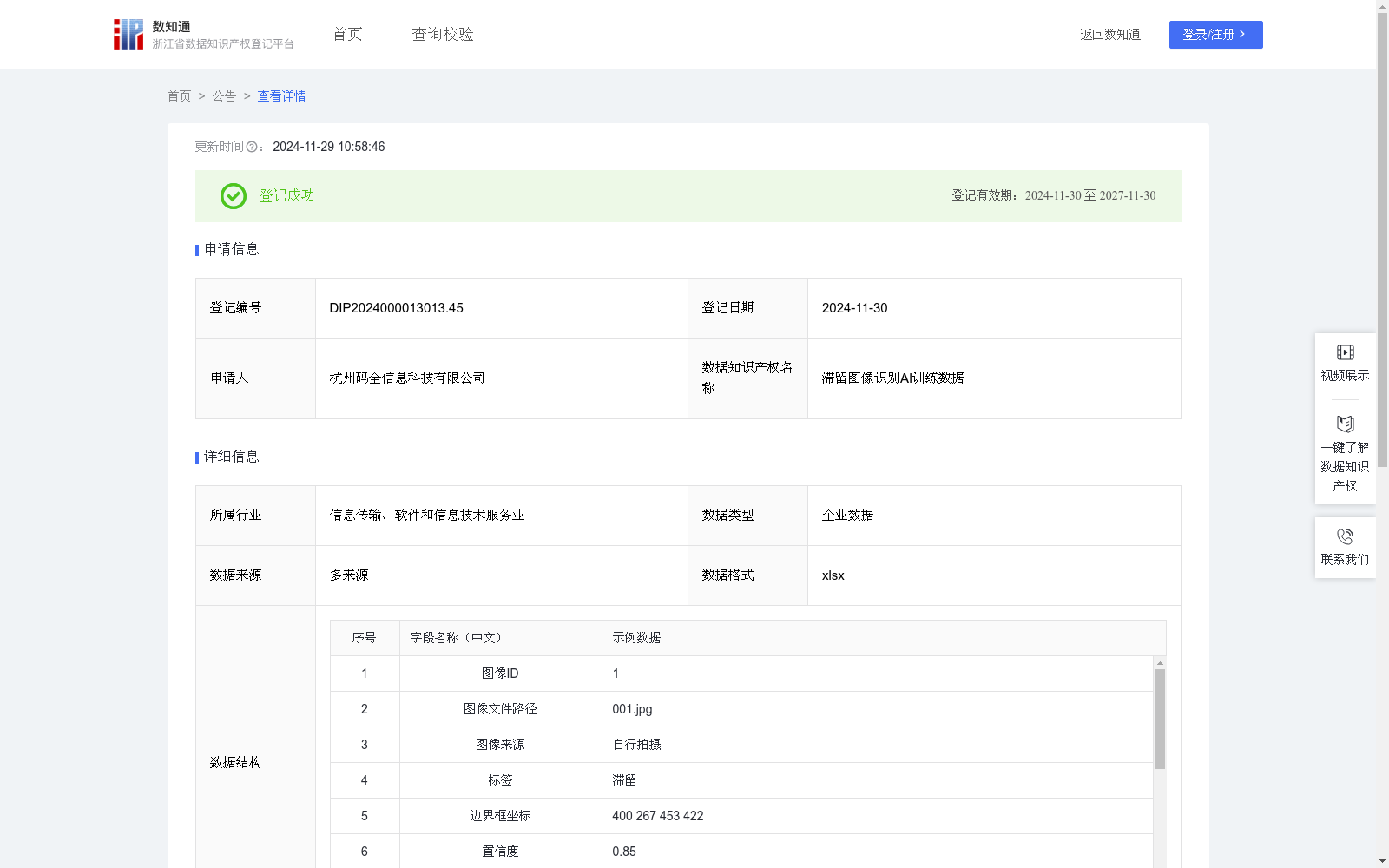
滞留图像识别AI训练数据
收藏浙江省数据知识产权登记平台2024-11-29 更新2024-11-30 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/91231
下载链接
链接失效反馈官方服务:
资源简介:
滞留图像识别AI训练数据主要应用于提升AI模型在实际场景中对滞留行为的识别能力和识别准确度。通过这些数据的训练,AI模型可以更准确地识别人员滞留行为,从而胜任在人流监控、安全预警等领域的应用。此外,超参数的应用进一步提升了模型的泛化能力和鲁棒性,使得AI模型在处理不同光照、天气和背景条件下的滞留图像时,具有更好的泛化能力和适应性。步骤1,原始图像数据来源于公开图像数据库、自行拍摄或其他算法生成。在此步骤中,记录每张图像的图像ID和图像文件路径。
步骤2,根据自身项目需求和模型要求,将滞留图像数据分类成数据集类型,分为训练集和测试集。对训练集图像进行标注,包括标签和边界框坐标。
步骤3,选择适合滞留图像识别的YOLO预训练模型,并初始化模型参数。设置合理的超参数,如学习率、批量大小等,以优化模型的训练过程。记录所使用的模型名称和这些超参数。
步骤4,使用PyTorch深度学习框架加载和初始化模型。将准备好的数据集输入到模型中进行训练。在训练过程中,模型会不断调整权重,以最小化预测框与真实框之间的差值。记录训练的训练时长和训练周期(迭代次数)。训练过程中,模型的置信度将逐渐提升。
步骤5,在训练完成后,使用测试集对模型进行评估。计算模型在不同场景下的精度、召回率、F1分数、以及实时性能评估等性能指标,确保模型的准确性和鲁棒性。
步骤6,将最终训练、测试后得到的模型应用到具体的项目中。在实际应用中,评估模型的实时性能,包括检测的准确性和处理速度,确保满足项目需求。记录模型在实际应用中的实时性能评估。
提供机构:
杭州码全信息科技有限公司
创建时间:
2024-11-11
搜集汇总
数据集介绍
特点
滞留图像识别AI训练数据集包含3306条数据,主要用于提升AI模型对滞留行为的识别能力,适用于人流监控和安全预警等场景。数据详细记录了图像ID、文件路径、标签、边界框坐标等信息,并采用YOLOv10模型进行训练。
以上内容由遇见数据集搜集并总结生成


