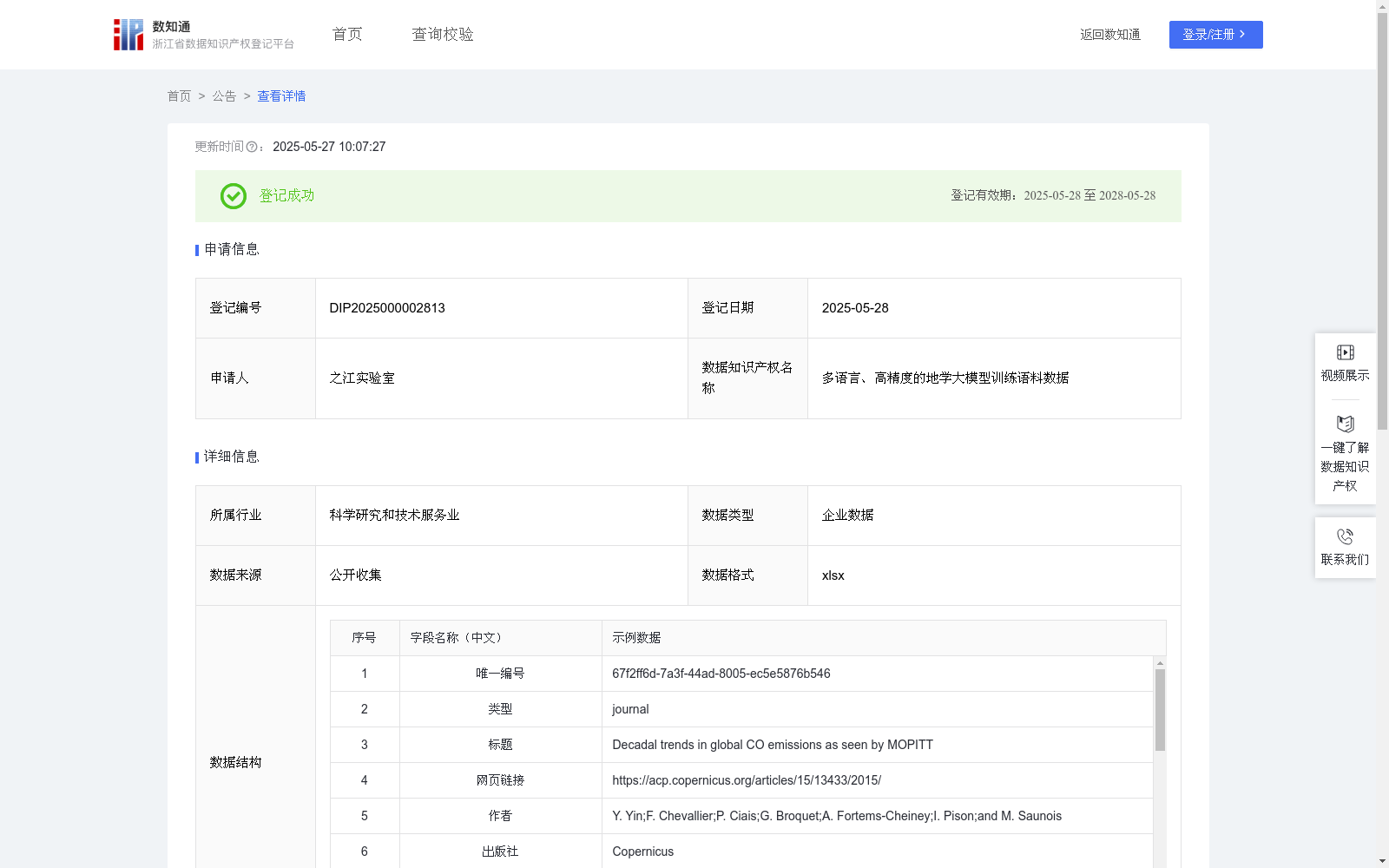
多语言、高精度的地学大模型训练语料数据
收藏浙江省数据知识产权登记平台2025-05-27 更新2025-05-28 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/132670
下载链接
链接失效反馈官方服务:
资源简介:
该数据知识产权数据量大于30万条。能够直接用于地学领域大语言模型训练,使其可以学习地学领域的专业术语、概念和语义信息,从而具备处理各种地学自然语言处理任务的能力,如文献分类、创新点挖掘、专业知识问答等。此外,利用该该数据知识产权可以构建一个大规模的地学知识图谱。通过实体识别和关系抽取技术,从论文标题、摘要和正文中提取地学领域的关键实体(如地质构造、岩石类型、矿物成分等)及其相互关系,形成结构化的知识网络。知识图谱结合检索增强生成能够使地学大模型生成更准确、更个性化的响应,从而帮助研究人员快速了解地学领域的研究现状、发现知识空白,并促进跨学科的研究合作。该数据知识产权也可以用于构建智能文献检索系统,从而使地学大模型能够具备地学文献检索的能力,为研究人员提供个性化的文献推荐服务,提高文献获取效率。1. 从互联网数据开放管理平台,比如spring nature等网站,广泛收集地球科学领域允许公开访问的论文数据集。
2. 对论文数据集做清洗和去重。清洗规则为没有标题或标题无意义(比如Untitled)、没有摘要、标题与摘要相等;去重规则为DOI(数字对象唯一标识)相等或者标题、期刊、年份全部相等。
3. 对论文的PDF(可携带文件格式)内容进行预处理,包括拆分、矫正、对齐和增强。
4. 对论文的PDF内容进行内容解析。包含版面分析和内容识别。版面分析包括基于文本解析的版面分析和基于视觉解析的版面分析两种。内容识别包括文本识别、表格识别、图片识别和公式识别。对每页图片应用目标检测技术,获取段落、公式、表格、图片等文档元素的位置和分类标签;对段落区域应用OCR(光学字符识别)技术,获取段落文本;对公式区域应用公式检测技术,获取公式latex表达;对表格区域应用表格识别技术,得到表示latex表达;根据坐标和识别结果,对所有内容进行合并,得到文本markdown。
5. 对论文的PDF内容进行后处理。后处理的步骤包括:数据清洗、信息过滤、内容去重、文档结构化。对于CPT(继续预训练)数据的后处理方法包括:去重、基于大模型的表格公式修复、页眉页脚去除、语言过滤、乱码去除、主题筛选(基于知识图谱或其他方式)。对于SFT(监督微调训练)数据的后处理方法主要包括基于解析后的markdown文本内容,利用大模型生成对话标注数据。
6. 将论文元数据与解析结果格式文件内容进行一一对应,形成用于地学大模型训练的语料数据,数据量为30万条左右。
7. 使用产出的论文元数据和解析结果对地学大模型进行训练。
This intellectual property dataset contains over 300,000 entries. It can be directly used for training geoscience large language models (LLMs), allowing the models to learn professional terminology, concepts and semantic information in the geoscience field, thus enabling them to handle various geoscience natural language processing tasks, such as document classification, innovation point mining, professional knowledge Q&A, etc. Additionally, this intellectual property dataset can be used to construct a large-scale geoscience knowledge graph. Through entity recognition and relation extraction technologies, key geoscience entities (such as geological structures, rock types, mineral components, etc.) and their interrelationships are extracted from paper titles, abstracts and full texts to form a structured knowledge network. When combined with Retrieval-Augmented Generation (RAG), the knowledge graph can enable geoscience LLMs to generate more accurate and personalized responses, helping researchers quickly grasp the current research status in the geoscience field, identify knowledge gaps, and promote interdisciplinary research collaboration. This intellectual property dataset can also be used to build an intelligent literature retrieval system, enabling geoscience LLMs to have the capability of geoscience literature retrieval, providing researchers with personalized literature recommendation services and improving the efficiency of literature acquisition.
1. Extensively collect publicly accessible paper datasets in the geoscience field from open internet data management platforms, such as Springer Nature and other similar websites.
2. Clean and deduplicate the paper datasets. The cleaning rules include: no title or meaningless title (e.g., "Untitled"), no abstract, and title identical to abstract. The deduplication rules are: same Digital Object Identifier (DOI), or identical title, journal and publication year.
3. Preprocess the Portable Document Format (PDF) content of the papers, including splitting, rectification, alignment and enhancement.
4. Perform content analysis on the PDF content of the papers, including layout analysis and content recognition. Layout analysis includes two types: text parsing-based layout analysis and visual parsing-based layout analysis. Content recognition includes text recognition, table recognition, image recognition and formula recognition. Apply object detection technology to each page image to obtain the positions and classification labels of document elements such as paragraphs, formulas, tables and images; apply Optical Character Recognition (OCR) technology to paragraph areas to obtain paragraph text; apply formula detection technology to formula areas to obtain LaTeX expressions of formulas; apply table recognition technology to table areas to obtain LaTeX expressions. Merge all content based on coordinates and recognition results to obtain markdown-formatted text.
5. Perform post-processing on the PDF content of the papers. The post-processing steps include: data cleaning, information filtering, content deduplication and document structuring. The post-processing methods for Continual Pre-training (CPT) data include: deduplication, large model-based table and formula repair, header and footer removal, language filtering, garbled code removal and topic screening (based on knowledge graphs or other methods). The post-processing methods for Supervised Fine-tuning (SFT) data mainly include generating dialogue annotation data using large models based on the parsed markdown text content.
6. One-to-one correspond the paper metadata with the parsed result format file contents to form corpus data for geoscience LLM training, with a scale of approximately 300,000 entries.
7. Train the geoscience LLM using the generated paper metadata and parsed results.
提供机构:
之江实验室
创建时间:
2025-04-16
搜集汇总
数据集介绍
背景与挑战
背景概述
多语言、高精度的地学大模型训练语料数据是一个由之江实验室公开收集的企业数据集,包含601条地学领域的论文数据,主要用于训练地学大语言模型,支持多种地学自然语言处理任务。
以上内容由遇见数据集搜集并总结生成


