Health_QA_Darija
收藏Hugging Face2026-04-23 更新2026-04-24 收录
下载链接:
https://huggingface.co/datasets/Kakyoin03/Health_QA_Darija
下载链接
链接失效反馈官方服务:
资源简介:
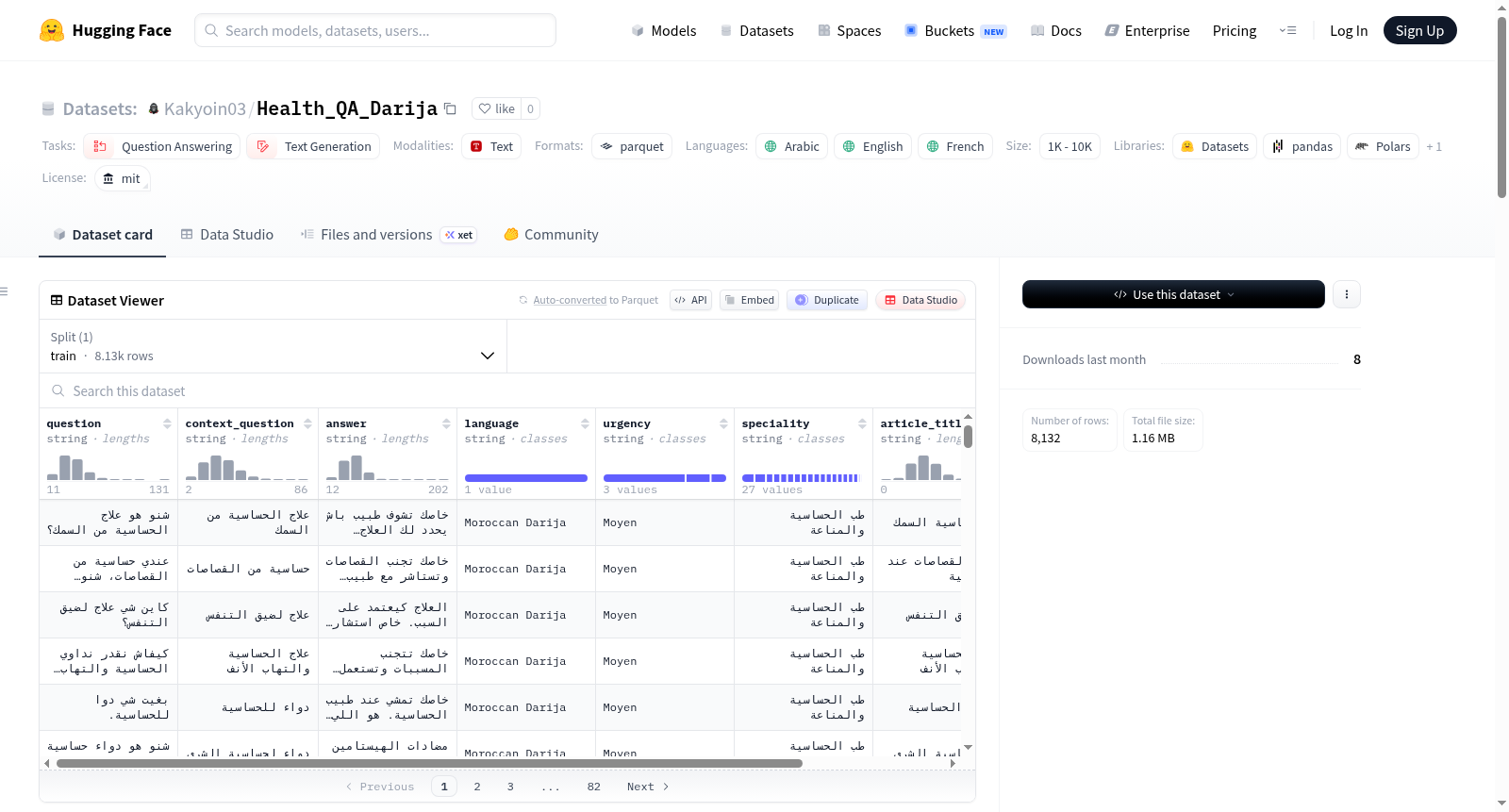
Health QA Darija 数据集包含翻译并文化适应为摩洛哥达里贾语的医学问答对,专门用于微调大型语言模型(LLMs),使其能够充当摩洛哥患者的医疗助手。数据集包含 8,132 个高质量的医学问答对,语言为摩洛哥达里贾语(包含标准医学英语/法语实体)。每个数据项包含以下字段:`question`(患者提出的原始问题,达里贾语)、`context_question`(结构化、总结版的问题,保留症状信息,达里贾语)、`answer`(医疗专业人员的回答,达里贾语)、`speciality`(医学领域,如心脏病学、皮肤病学等)、`urgency`(分诊级别:低、中、高)、`entities`(提取的临床实体,如年龄、症状、疾病、药物等)。数据集经过严格的“LLM-as-a-judge”评估框架(使用 Grok-4.20-Reasoning)和自动化 NLP 指标验证,确保语义和事实完整性。评估指标包括上下文相关性(4.90/5.0)、忠实性(4.65/5.0)、答案相关性(4.00/5.0)、专业性(3.80/5.0)、词汇多样性(类型-标记比 0.1570)等。
The Health QA Darija dataset contains medical question-answer pairs translated and culturally adapted into Moroccan Darija, specifically designed to fine-tune large language models (LLMs) to act as medical assistants for Moroccan patients. The dataset includes 8,132 high-quality medical question-answer pairs in Moroccan Darija (with standard medical English/French entities). Each data item contains the following fields: `question` (the original question posed by the patient, in Darija), `context_question` (a structured, summarized version of the question, retaining symptom information, in Darija), `answer` (the response from a medical professional, in Darija), `speciality` (the medical field, such as cardiology, dermatology, etc.), `urgency` (triage level: low, medium, high), and `entities` (extracted clinical entities, such as age, symptoms, diseases, medications, etc.). The dataset has undergone rigorous evaluation using an LLM-as-a-judge framework (with Grok-4.20-Reasoning) and automated NLP metrics to ensure semantic and factual integrity. Evaluation metrics include context relevance (4.90/5.0), faithfulness (4.65/5.0), answer relevance (4.00/5.0), professionalism (3.80/5.0), and lexical diversity (type-token ratio 0.1570), among others.
创建时间:
2026-04-23
原始信息汇总
Health QA Darija 数据集概述
基本信息
- 数据集名称: Health QA Darija
- 语言: 摩洛哥达里贾语(包含标准医学英语/法语术语),同时支持阿拉伯语、英语、法语
- 许可证: MIT
- 任务类型: 问答、文本生成
- 数据集规模: 8,132 条高质量医疗问答对(1K < 样本数 < 10K)
- 数据集链接: https://huggingface.co/datasets/Kakyoin03/Health_QA_Darija
数据集结构
每条数据包含以下字段:
- question: 患者提出的原始问题(达里贾语)
- context_question: 保留症状的结构化、摘要化问题版本(达里贾语)
- answer: 医疗专业人员的回答(达里贾语)
- speciality: 医学领域(如心脏病学、皮肤病学)
- urgency: 分诊级别(Faible 低、Moyen 中、Fort 高)
- entities: 提取的临床实体(年龄、症状、疾病、药物)
数据评估与验证
数据集经过严格的“LLM-as-a-judge”评估框架,使用 Grok-4.20-Reasoning(xAI)确保语义和事实完整性,同时结合自动化 NLP 指标。
1. RAG Triad 指标(Grok-4.20 评估)
- 上下文相关性: 4.90 / 5.0(症状捕获优秀)
- 忠实度: 4.65 / 5.0(高事实准确性,零幻觉)
- 答案相关性: 4.00 / 5.0(医疗建议的直接性)
- 专业性: 3.80 / 5.0(通俗易懂,文化相关语气)
2. 词汇与数据多样性指标
- 类型-标记比率(TTR): 问题部分 0.1570(相比英语基线 0.02,词汇多样性显著更高)
- 完全重复率: 2.79%(从原始数据集的 18% 大幅降低)
- 近似重复率(Jaccard >80%): 0.0012%
- 过拟合风险: 可忽略
3. 自动化 NLP 流水线评分
- 语义相似度(余弦): 0.4045
- BERTScore(F1): 0.6873
- 安全评分(危险关键词检查): 96.8%
数据集用途
该数据集专门设计用于微调大型语言模型(LLMs),使其能够作为摩洛哥患者的医疗助手。
搜集汇总
数据集介绍
构建方式
Health_QA_Darija数据集旨在弥合摩洛哥达里加方言与医疗服务之间的语言鸿沟,为大型语言模型提供高质量的医学问答微调资源。该数据集包含8,132对精心构建的医学问答,每一对都经过翻译和文化适配,以契合摩洛哥患者的语言习惯与医疗语境。每条数据均由四个核心字段组成:原始患者提问(question)、结构化摘要后的语境问题(context_question)、专业医师的答复(answer),以及额外的元信息如医学专科(speciality)、分诊紧急程度(urgency)和提取的临床实体(entities)。构建过程中,研究团队运用了严格的‘以大模型为裁判’(LLM-as-a-judge)评估框架,借助Grok-4.20-Reasoning模型对语义完整性和事实准确性进行把关,同时辅以自动化自然语言处理指标,确保数据集的可靠性与实用价值。
使用方法
使用Health_QA_Darija数据集进行模型微调时,开发者可直接加载HuggingFace上的数据仓库,将问答对适配至序列到序列或文本生成类任务。典型应用场景包括训练面向摩洛哥患者的智能医疗助手,通过输入患者原生达里加语问题,结合context_question字段提供的结构化语境,由模型输出准确且文化适配的医疗建议。数据集中的speciality与urgency字段可用于条件生成,分诊控制或领域约束,而entities字段则支持实体感知的增强检索或解释性生成。建议在微调时以question和context_question作为输入、answer作为目标序列,并利用评估代码(如提供的llm_as_a_judge.py)中的自动化管道,持续监控模型输出的相关性、忠实度与安全性,以迭代优化医疗对话系统的表现。
背景与挑战
背景概述
在低资源语言自然语言处理领域,医疗问答系统的构建面临数据稀缺与文化适配的双重瓶颈。Health_QA_Darija数据集由研究者Kakyoin03主导创建,于近期发布在HuggingFace平台,旨在为摩洛哥达里亚方言提供高质量的医学问答对。该数据集包含8132条经过严格筛选的问答实例,覆盖心脏病学、皮肤病学等多个专科,并整合了临床实体(如症状、药物)与分诊等级,为大型语言模型在医疗辅助场景下的微调奠定基础。其独创性在于将标准医学英语/法语术语与本土方言融合,通过‘LLM-as-a-judge’评估框架(采用Grok-4.20模型)保障语义准确与事实完整性,显著提升了模型在文化语境敏感任务中的可靠性,对推动低资源语言医疗AI的研究具有里程碑意义。
当前挑战
该数据集的核心挑战在于解决摩洛哥达里亚语医疗问答的领域空白,即缺乏可直接用于模型精调的汉英双语对照资源,且方言中混杂的法语、阿拉伯语词汇加剧了语义歧义。构建过程中面临多重难点:首先,原始数据重复率高达18%,需通过精准去重算法降至2.79%,并控制近重复条目(Jaccard相似度>80%)在0.0012%以内,以防范过拟合风险;其次,医疗术语的跨语言对齐与文化适配需兼顾专业性与可读性,最终导致专业度评分(3.80/5.0)偏低,表明在保持答案直达性的同时仍需提升语境中立的表达能力;此外,自动化评估指标显示语义相似度(0.4045)与BERTScore(0.6873)仍有优化空间,提示现有模型在理解方言细微差别和生成连贯推理链方面存在局限。
常用场景
经典使用场景
Health_QA_Darija数据集的核心经典使用场景在于对大规模语言模型进行微调,使其能够胜任摩洛哥达里加方言的医疗问答助手角色。该数据集收录了超过八千条高质量、经过文化适配的医患问答对,覆盖心脏病学、皮肤病学等多个专科领域,并标注了临床实体、紧急程度和结构化上下文。研究者可基于这些数据,训练模型理解方言中口语化的症状描述,同时结合标准医学术语,生成精准且文化贴切的医疗建议,从而实现面向北非阿拉伯语群体的智能医疗对话系统。
解决学术问题
该数据集精准回应了低资源语言在医疗自然语言处理领域长期面临的学术困境——方言与专业医学知识之间的语义鸿沟。传统医疗问答数据集多集中于英语或规范阿拉伯语,难以覆盖摩洛哥达里亚语独特的词汇变体与语法结构。Health_QA_Darija通过构建结构化上下文与临床实体标注,解决了方言症状表述的歧义性问题,并利用LLM-as-a-judge评估框架验证了事实一致性与语义相关性,为跨语言医疗信息检索、方言问答推理以及低资源语言模型对齐研究提供了可靠的基准与方法论支撑。
实际应用
在实际应用中,基于该数据集微调的模型可被部署为摩洛哥本土化医疗助手,服务于医疗资源匮乏的地区。患者能用日常达里加方言描述病情,系统则依据紧急程度进行分诊建议,并给出符合当地文化与习惯的用药和就医指导。此外,数据集中的专科标签与实体信息可用于开发辅助临床决策系统,帮助基层医生快速检索相似病例。项目还计划整合于公共卫生平台,实现对非标准方言语音转文本后的实时医疗咨询,真正弥合语言障碍导致的就医鸿沟。
数据集最近研究
最新研究方向
Health_QA_Darija数据集的最新研究方向聚焦于利用大规模语言模型(LLM)在低资源语言环境下的医疗问答能力,尤其在摩洛哥达里贾语这一方言变体中实现医学信息的精准传播。当前,该领域的热点事件包括将LLM与结构化医疗知识库结合,通过'LLM-as-a-judge'框架(如Grok-4.20)自动评估语义保真度与临床安全性,以解决文化适应与医学翻译中的歧义问题。此外,研究还强调通过RAG三元指标优化症状捕获可靠性,并利用极低重复率(2.79%)的数据质量控制确保模型泛化能力,这对推动非洲地区数字医疗基础设施的民主化、弥合语言鸿沟具有深远意义。
以上内容由遇见数据集搜集并总结生成


