Moroccan-Darija-Youtube-Commons-Metrics
收藏Hugging Face2025-01-17 更新2025-01-18 收录
下载链接:
https://huggingface.co/datasets/BounharAbdelaziz/Moroccan-Darija-Youtube-Commons-Metrics
下载链接
链接失效反馈官方服务:
资源简介:
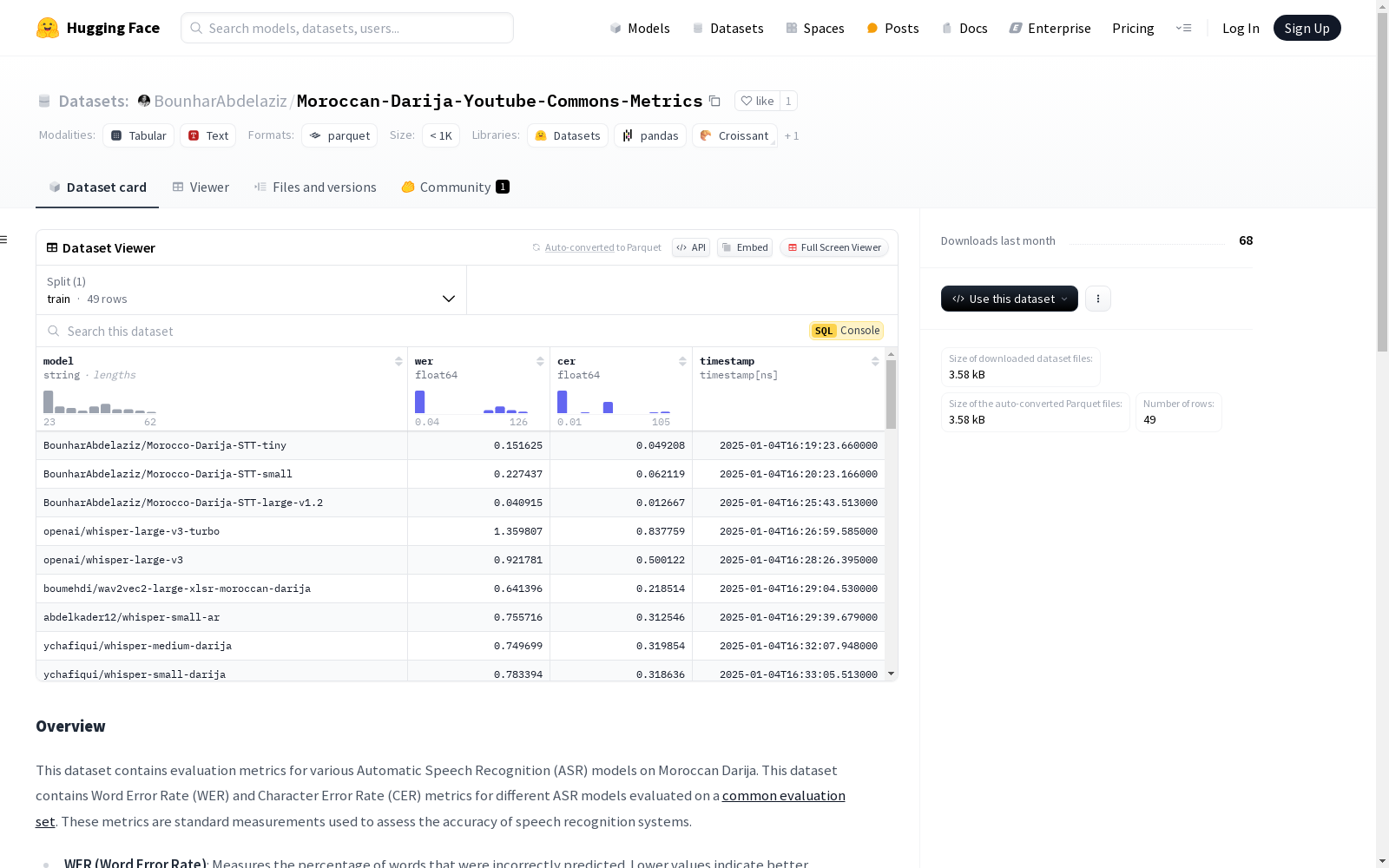
该数据集包含了对不同自动语音识别(ASR)模型在摩洛哥达里贾语上的评估指标。数据集包括词错误率(WER)和字符错误率(CER)指标,这些指标用于评估语音识别系统的准确性。WER衡量错误预测的单词百分比,CER衡量错误预测的字符百分比,值越低表示性能越好。数据集中的每一行包含模型名称、WER和CER。
创建时间:
2025-01-04
搜集汇总
数据集介绍
构建方式
Moroccan-Darija-Youtube-Commons-Metrics数据集的构建基于对多种自动语音识别(ASR)模型在摩洛哥达里贾语上的评估。这些模型在统一的评估集上进行测试,评估集包含105个样本,音频格式为16kHz单声道PCM。通过使用`jiwer`库计算词错误率(WER)和字符错误率(CER),所有音频样本在转录前均经过归一化和重采样处理,确保评估的准确性和一致性。
使用方法
该数据集的使用方法较为直观,研究者可以通过加载数据集获取不同ASR模型在摩洛哥达里贾语上的评估结果。每条记录包含模型名称、WER和CER值,用户可以根据这些指标进行模型性能的横向对比。此外,数据集还可用于验证新模型的性能,通过将其结果与现有模型进行比较,评估其改进效果。数据集的结构清晰,适合用于语音识别领域的性能评估和模型优化研究。
背景与挑战
背景概述
Moroccan-Darija-Youtube-Commons-Metrics数据集专注于摩洛哥达里贾方言的自动语音识别(ASR)模型评估。该数据集由Atlasia团队创建,旨在提供标准化的评估指标,如词错误率(WER)和字符错误率(CER),以衡量不同ASR模型在摩洛哥达里贾方言上的表现。摩洛哥达里贾方言作为一种阿拉伯语的方言变体,具有独特的语音和语法特征,这使得其在语音识别领域的研究具有挑战性。该数据集的发布为研究人员提供了一个统一的评估基准,推动了摩洛哥达里贾方言ASR技术的发展。
当前挑战
该数据集面临的挑战主要集中在两个方面。首先,摩洛哥达里贾方言的语音识别本身具有较高的复杂性,因其与标准阿拉伯语存在显著差异,且缺乏大规模的标注数据。其次,在数据集的构建过程中,如何确保评估数据的多样性和代表性是一个关键问题。由于摩洛哥达里贾方言在不同地区和社会群体中存在较大差异,构建一个能够全面覆盖这些变体的评估集需要大量的资源和时间。此外,ASR模型在处理低资源语言时的性能优化也是一个持续的技术挑战。
常用场景
经典使用场景
Moroccan-Darija-Youtube-Commons-Metrics数据集主要用于评估不同自动语音识别(ASR)模型在摩洛哥达里贾语上的表现。通过提供词错误率(WER)和字符错误率(CER)等标准度量,研究人员能够系统地比较和优化模型在特定语言环境下的性能。该数据集为语音识别领域的研究提供了重要的基准数据,尤其是在处理低资源语言时,具有显著的参考价值。
解决学术问题
该数据集解决了自动语音识别模型在摩洛哥达里贾语上的性能评估问题。通过提供标准化的评估指标,研究人员能够量化模型的表现,识别模型在处理特定语言时的弱点,并推动模型优化。这对于提升低资源语言的语音识别技术具有重要意义,尤其是在多语言和跨文化场景中,能够促进语音技术的普及和应用。
实际应用
在实际应用中,Moroccan-Darija-Youtube-Commons-Metrics数据集可用于开发面向摩洛哥市场的语音助手、语音翻译工具以及语音驱动的客户服务系统。通过优化模型在达里贾语上的表现,能够显著提升用户体验,尤其是在语音输入和语音交互的场景中,为摩洛哥用户提供更加精准和流畅的服务。
数据集最近研究
最新研究方向
在自动语音识别(ASR)领域,摩洛哥达里贾语(Moroccan Darija)作为一种低资源语言,近年来受到了越来越多的关注。Moroccan-Darija-Youtube-Commons-Metrics数据集通过提供不同ASR模型在摩洛哥达里贾语上的词错误率(WER)和字符错误率(CER)评估指标,为研究者提供了宝贵的基准数据。当前的研究方向主要集中在如何通过改进模型架构、数据增强技术以及跨语言迁移学习来提升低资源语言的识别准确率。特别是随着Whisper等大规模预训练模型的引入,研究者们正在探索如何将这些模型适配到摩洛哥达里贾语等特定语言环境中,以进一步降低WER和CER。此外,该数据集还为多语言ASR系统的开发提供了重要的参考,推动了低资源语言在语音技术领域的应用与发展。
以上内容由遇见数据集搜集并总结生成


