Nemotron-Personas
收藏Hugging Face2025-06-10 更新2025-06-11 收录
下载链接:
https://huggingface.co/datasets/nvidia/Nemotron-Personas
下载链接
链接失效反馈官方服务:
资源简介:
Nemotron-Personas是一个开源(CC BY 4.0许可)的合成人物数据集,基于真实世界的人口统计、地理和性格特征分布,以捕捉人口的多样性和丰富性。它是第一个与姓名、性别、年龄、背景、婚姻状况、教育、职业和位置等属性的统计数据对齐的数据集。该数据集的初始版本专注于美国,为各种建模用例提供了高质量的人物。
Nemotron-Personas is an open-source (licensed under CC BY 4.0) synthetic persona dataset grounded in real-world demographic, geographic, and personality trait distributions to capture the diversity and richness of human populations. It is the first dataset aligned with the statistical distributions of attributes including name, gender, age, background, marital status, education, occupation, and location. The initial release of this dataset focuses on the United States, providing high-quality personas for a wide range of modeling use cases.
提供机构:
NVIDIA
创建时间:
2025-06-09
搜集汇总
数据集介绍
构建方式
在合成数据生成领域,Nemotron-Personas数据集采用了一种创新的复合人工智能方法,通过Gretel Data Designer系统构建。该系统结合了专有的概率图模型与经过Apache-2.0许可的大型语言模型Mistral-Nemo-Instruct-2407和Mixtral-8x22B-v0.1,并融入了不断扩展的验证器和评估器。数据生成过程严格遵循美国人口普查局和美国社区调查的公开统计数据,确保合成人物属性在人口统计、地理分布和人格特质等多个维度上与真实世界分布保持一致。
特点
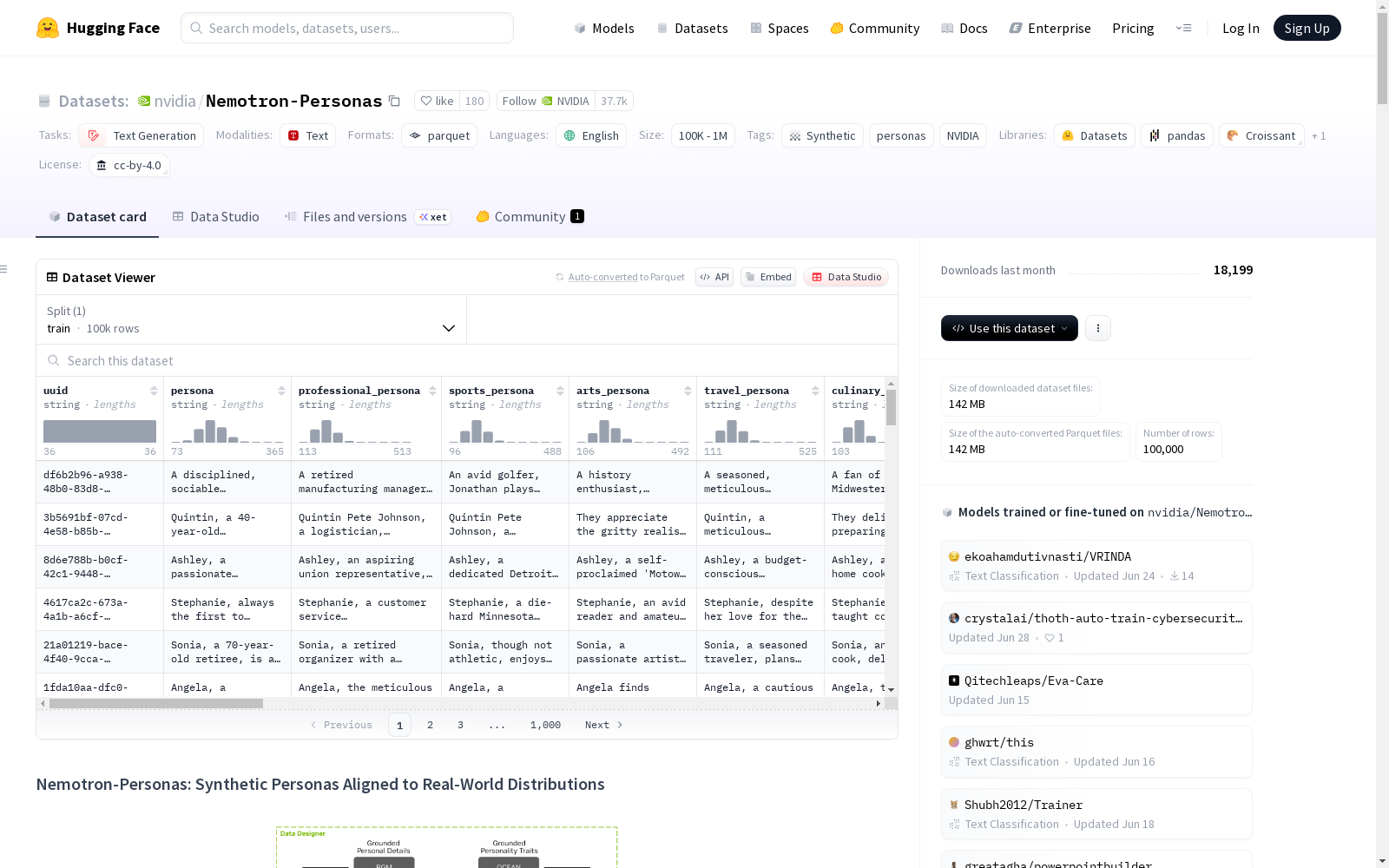
该数据集包含10万条记录,涵盖22个字段,其中6个为核心人物属性字段,16个为上下文字段,总计约5400万令牌。其显著特点在于全面覆盖了人口统计、地理和人格特质等多个轴线的多样性,包括超过560种不同的职业类别。数据集特别注重代表性地捕捉年龄分布、婚姻状况、教育水平和地理差异等复杂模式,例如年龄分布呈现非高斯右偏形态,反映了真实人口结构的历史出生率、死亡率趋势和迁移模式。
使用方法
研究人员和开发者可通过Hugging Face的datasets库直接加载该数据集,使用简洁的Python代码即可访问。该数据集专为提升合成数据的多样性、缓解数据与模型偏见以及防止模型坍塌而设计,适用于训练大型语言模型和多种建模用例。用户可根据16个上下文字段精确定位特定人物类型,这在现有数据集中难以实现。数据集采用CC BY 4.0许可,支持商业和非商业用途,鼓励开源社区进一步探索和改进。
背景与挑战
背景概述
在人工智能与合成数据生成领域,Nemotron-Personas数据集由NVIDIA于2025年6月推出,标志着合成人物画像生成技术的重要进展。该数据集基于美国人口普查局和开放统计数据,采用概率图模型与先进大语言模型联合生成,旨在构建符合真实世界人口统计分布的高质量合成人物画像。其核心研究问题在于如何通过合成数据技术提升模型训练中的多样性与公平性,减少数据偏见,并防止模型坍塌现象。这一工作对推动自然语言生成、个性化推荐系统及伦理人工智能发展具有深远影响。
当前挑战
Nemotron-Personas致力于解决合成人物画像生成中的分布对齐与多样性保障问题,其挑战包括如何在多维度属性(如年龄、教育、职业、地域等)上精确拟合真实人口统计分布,并避免生成数据的模式单一性。在构建过程中,需克服真实数据源的限制,如性别与性别认同数据的缺失,以及高维属性间的复杂依赖关系建模难题。此外,合成数据还需在保持统计一致性的同时,避免生成与真实个体相似的信息,以确保伦理合规性。
常用场景
经典使用场景
在自然语言生成领域,Nemotron-Personas数据集通过合成人物角色数据为对话系统和个性化文本生成提供丰富素材。该数据集基于真实世界人口统计分布构建,涵盖年龄、职业、教育等多维特征,使研究者能够生成具有人口统计学代表性的对话样本,显著提升生成文本的社会多样性表现。
解决学术问题
该数据集有效解决了合成数据生成中的代表性缺失问题,通过对齐美国人口普查统计分布,弥补了传统方法在年龄偏态分布、地理差异和职业多样性方面的不足。其概率图模型与大型语言模型协同的生成方式,为消除数据偏见和防止模型坍塌提供了新的技术路径,推动了合成数据生成领域的算法公平性研究。
衍生相关工作
基于该数据集衍生的研究包括多模态人物角色生成系统、偏见检测框架以及合成数据质量评估标准。其采用的复合AI方法启发了后续工作如Demographic-Aware数据生成器和联邦学习中的合成数据增强方案,这些成果在ACL、NeurIPS等顶级会议中形成了新的研究方向。
以上内容由遇见数据集搜集并总结生成


