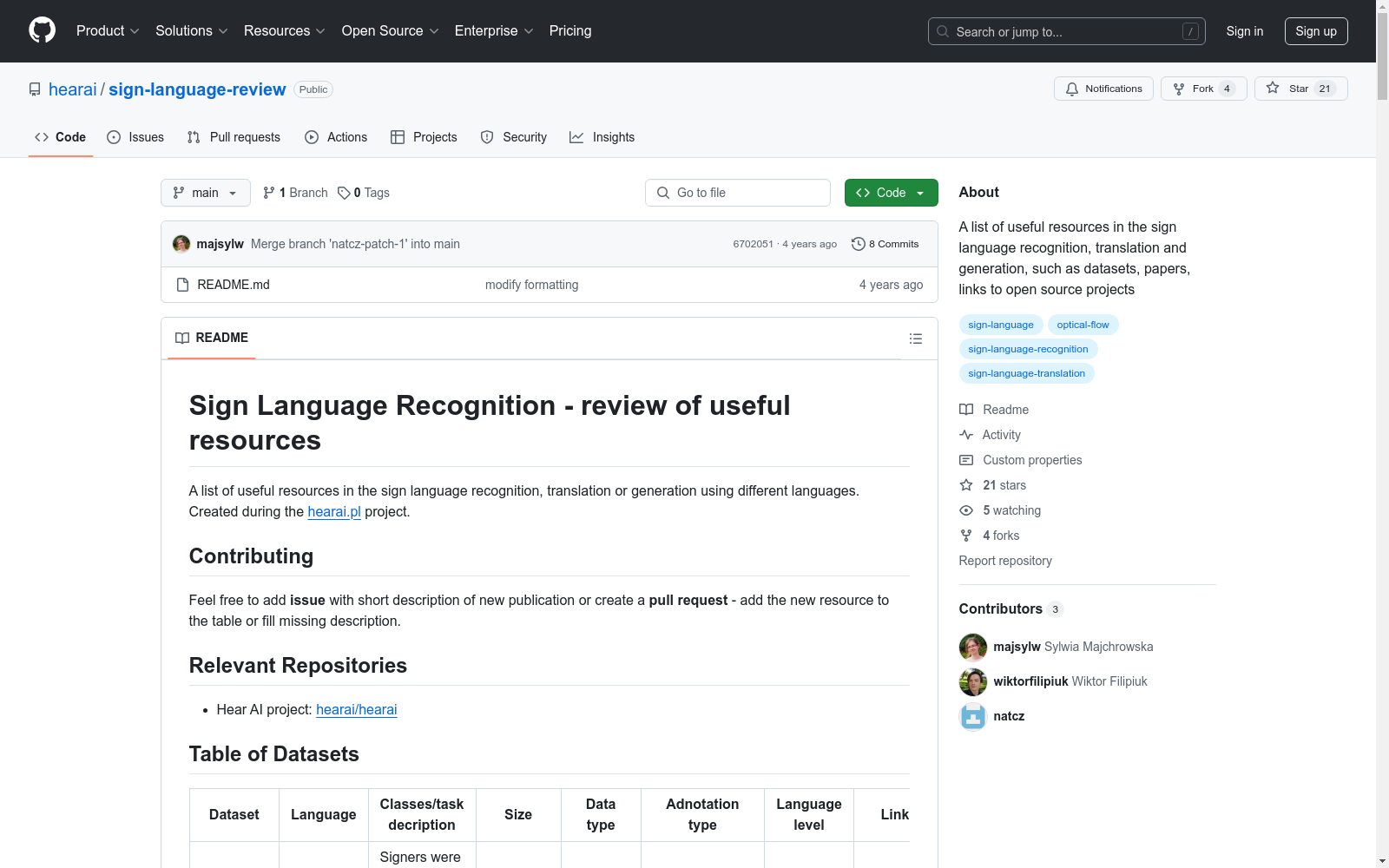
DGS, PJM, Signor Corpus, Dicta Sign Lexicon, Galex, LEDASILA, RWTH-PHOENIX, GSLL, SIGNUM, MS-ASL, AUTSL, WLASL
收藏github2021-12-18 更新2024-05-31 收录
下载链接:
https://github.com/hearai/sign-language-review
下载链接
链接失效反馈官方服务:
资源简介:
DGS: 德语手语数据集,包含20种活动描述和讲故事的视频。PJM: 波兰手语数据集,包含讲述图片内容和个人故事的视频。Signor Corpus: 斯洛文尼亚手语数据集,主要在本地聋人俱乐部录制。Dicta Sign Lexicon: 多国手语词汇数据集,包含1000个单词和短语的视频。Galex: 德语手语数据集,专注于园艺和景观词汇。LEDASILA: 奥地利手语数据集,包含不同类别的单词。RWTH-PHOENIX: 德语手语数据集,包含天气预报的符号语言转录。GSLL: 希腊手语数据集,包含347个不同的符号/类别。SIGNUM: 德语手语数据集,包含日常使用的单词和短语。MS-ASL: 美国手语数据集,包含1000个符号的视频。AUTSL: 土耳其手语数据集,包含226个符号,由43个不同的符号者执行。WLASL: 美国手语数据集,包含3126个符号。
DGS: German Sign Language Dataset, containing videos of 20 activity descriptions and storytelling. PJM: Polish Sign Language Dataset, including videos of picture descriptions and personal stories. Signor Corpus: Slovenian Sign Language Dataset, primarily recorded at local deaf clubs. Dicta Sign Lexicon: Multinational Sign Language Lexicon Dataset, featuring videos of 1000 words and phrases. Galex: German Sign Language Dataset, focusing on gardening and landscape vocabulary. LEDASILA: Austrian Sign Language Dataset, containing words from various categories. RWTH-PHOENIX: German Sign Language Dataset, featuring sign language transcriptions of weather forecasts. GSLL: Greek Sign Language Dataset, comprising 347 different signs/categories. SIGNUM: German Sign Language Dataset, including words and phrases for everyday use. MS-ASL: American Sign Language Dataset, containing videos of 1000 signs. AUTSL: Turkish Sign Language Dataset, featuring 226 signs performed by 43 different signers. WLASL: American Sign Language Dataset, containing 3126 signs.
创建时间:
2021-12-11
原始信息汇总
数据集概述
1. DGS
- 语言: 德语手语
- 任务描述: 20种活动,如描述事物和讲故事
- 大小: 50小时
- 数据类型: 视频
- 注释类型: iLex, srt (字幕), openpose (json), elan, cmdi
- 语言水平: 连续
- 链接: DGS
- 许可证: 许可证
- 下载状态: 部分
2. PJM
- 语言: 波兰手语
- 任务描述: 讲述图片内容和视频,讲述自己的视频,谈论感兴趣的话题
- 大小: 400小时
- 数据类型: 视频
- 注释类型: 文本
- 语言水平: 连续
- 链接: PJM
- 许可证: 无信息
- 下载状态: 部分
3. Signor Corpus
- 语言: 斯洛文尼亚手语
- 任务描述: 大多数录制在当地的聋人俱乐部,部分在家中录制
- 大小: 无信息
- 数据类型: 视频
- 注释类型: 分词, iLex, HamNoSys, gloss
- 语言水平: 连续
- 链接: Signor
- 许可证: 不可用
- 下载状态: 由于数据保护问题未提供
4. Dicta Sign Lexicon
- 语言: 英国手语, 希腊手语, 德语手语, 法语手语
- 任务描述: 1000个单词和短语,许多视频中手语者讲述故事
- 大小: 无信息
- 数据类型: 视频
- 注释类型: gloss/翻译
- 语言水平: 两者
- 链接: Dicta
- 许可证: 无信息
- 下载状态: 否
5. Galex
- 语言: 德语手语
- 任务描述: 园艺和景观词汇
- 大小: 654个技术短语
- 数据类型: 视频
- 注释类型: gloss
- 语言水平: 孤立
- 链接: GaLex
- 许可证: 无信息
- 下载状态: 否
6. LEDASILA
- 语言: 奥地利手语
- 任务描述: 不同类别的单词
- 大小: 无信息
- 数据类型: 视频
- 注释类型: 含义(gloss)和动作描述
- 语言水平: 孤立
- 链接: LedaSila
- 许可证: 创意共享
- 下载状态: 与所有者联系中
7. RWTH-PHOENIX
- 语言: 德语手语
- 任务描述: 天气预报的手语转录
- 大小: 53GB
- 数据类型: 视频
- 注释类型: gloss
- 语言水平: 连续
- 链接: Phoenix
- 许可证: 似乎开放使用
- 下载状态: 是
8. GSLL
- 语言: 希腊手语
- 任务描述: 347个不同的符号/类
- 大小: 3,464个视频/42GB
- 数据类型: 视频
- 注释类型: gloss/翻译
- 语言水平: 孤立
- 链接: GSLL
- 许可证: 公开可用,无限制信息
- 下载状态: 是
9. SIGNUM
- 语言: 德语手语
- 任务描述: 日常使用的单词和短语
- 大小: 无信息
- 数据类型: 视频
- 注释类型: gloss/翻译
- 语言水平: 两者
- 链接: SIGNUM
- 许可证: 无限制信息
- 下载状态: 否
10. MS-ASL
- 语言: 美国手语
- 任务描述: 1000个符号
- 大小: 25000个视频
- 数据类型: 视频
- 注释类型: bbox, gloss
- 语言水平: 孤立
- 链接: MS ASL
- 许可证: 公开可用
- 下载状态: 是
11. AUTSL
- 语言: 土耳其手语
- 任务描述: 226个符号,由43个不同的手语者执行
- 大小: 38336个视频
- 数据类型: 视频,使用Microsoft Kinect v2录制,格式为RGB, 深度和骨骼
- 注释类型: 手语者身体上25个关节点的空间坐标, gloss
- 语言水平: 孤立
- 链接: AUTSL
- 许可证: 公开但未上传
- 下载状态: 否
12. WLASL
- 语言: 美国手语
- 任务描述: 3126个glosses
- 大小: 34404个视频
- 数据类型: 视频
- 注释类型: gloss, bbox, 时间边界(开始, 结束帧), 手语方言
- 语言水平: 孤立
- 链接: WLASL
- 许可证: 计算使用数据协议(C-UDA)
- 下载状态: 部分,不包括YouTube视频
13. SPREAD THE SIGN
- 语言: 波兰手语, 英国手语, 德语手语, 俄罗斯手语, 法语手语, 美国手语, 西班牙手语
- 任务描述: 42种语言中的25030个单词
- 大小: 574273个视频
- 数据类型: 视频
- 注释类型: gloss
- 语言水平: 孤立
- 链接: Spread the sign
- 许可证: 无信息
- 下载状态: 是
14. CSL-Daily
- 语言: 中国手语
- 任务描述: 旅行, 购物, 医疗和日常生活词汇
- 大小: 无信息
- 数据类型: 视频
- 注释类型: 口语翻译和gloss级注释
- 语言水平: 连续
- 链接: CSL
- 许可证: 需与中国科技大学签订协议,仅限研究使用,非商业用途
- 下载状态: 否
15. NMFs-CSL
- 语言: 中国手语
- 任务描述: 1,067个中国手语单词(610个混淆单词, 457个正常单词)
- 大小: 无信息
- 数据类型: RGB视频
- 注释类型: gloss
- 语言水平: 孤立
- 链接: NMFs CSL
- 许可证: 需与中国科技大学签订协议,仅限研究使用,非商业用途
- 下载状态: 否
16. ASLLVD
- 语言: 美国手语
- 任务描述: 许多单词和短语
- 大小: 无信息
- 数据类型: 视频
- 注释类型: gloss标签, 手语开始和结束时间码, 双手开始和结束手势标签, 手语类型形态和发音分类
- 语言水平: 孤立
- 链接: ASLLVD
- 许可证: 可用于研究和教育目的,不允许商业使用
- 下载状态: 否
17. BUHMAP-DB
- 语言: 土耳其手语
- 任务描述: 非手动手势, 8个不同类
- 大小: 48个注释视频
- 数据类型: 视频
- 注释类型: gloss, 选定点的地面实况
- 语言水平: 孤立
- 链接: BUHMAP
- 许可证: 可用于学术研究目的
- 下载状态: 否
18. PL-Kinect
- 语言: 波兰手语
- 任务描述: 84个PSL(PJM)单词,每个手势执行20次
- 大小: 84个视频
- 数据类型: 点云视频
- 注释类型: 翻译/gloss
- 语言水平: 孤立
- 链接: Vision PRZ
- 许可证: 公开可用,无限制信息
- 下载状态: 否
19. LATLAB
- 语言: 美国手语
- 任务描述: 98个不同的故事
- 大小: 每个视频0.5-4分钟
- 数据类型: 视频
- 注释类型: 每个手语的glosses, 每段英文翻译, 代词空间参考点的建立和使用细节
- 语言水平: 连续
- 链接: LATLAB
- 许可证: 无信息
- 下载状态: 否
搜集汇总
数据集介绍
构建方式
该数据集的构建基于多国手语的实际应用场景,涵盖了德国、波兰、斯洛文尼亚、英国、希腊、法国、美国、土耳其、中国等多个国家的手语数据。数据采集主要通过视频录制完成,录制内容涵盖了日常对话、故事讲述、天气预报等多种情境。部分数据集还通过Kinect等设备捕捉了深度和骨骼信息,进一步丰富了数据的维度。数据的标注形式多样,包括手语词汇的翻译、手势的起始和结束时间、手形标签等,确保了数据的多样性和实用性。
特点
该数据集的特点在于其广泛的语言覆盖和丰富的标注信息。数据集不仅包含了多种手语的视频数据,还提供了详细的标注信息,如手语词汇的翻译、手势的起始和结束时间、手形标签等。此外,部分数据集还提供了深度和骨骼信息,为手语识别和生成任务提供了更多的可能性。数据集的语言层次涵盖了连续手语和孤立手语,适用于不同的研究需求。
使用方法
该数据集的使用方法主要围绕手语识别、翻译和生成任务展开。研究人员可以通过视频数据和标注信息,训练和验证手语识别模型。对于连续手语数据,可以用于手语翻译和生成任务,而孤立手语数据则适用于手语词汇识别和分类任务。部分数据集还提供了深度和骨骼信息,可以用于更复杂的手势分析和生成任务。在使用过程中,研究人员需注意数据的使用许可,确保符合研究或教育用途的要求。
背景与挑战
背景概述
手语识别与翻译领域近年来随着深度学习技术的进步取得了显著进展,DGS、PJM、Signor Corpus等数据集的构建为这一领域的研究提供了重要的数据支持。这些数据集涵盖了多种语言的手语数据,包括德语、波兰语、斯洛文尼亚语等,旨在通过视频、文本等多种数据形式记录手语表达。这些数据集的创建时间主要集中在2010年代后期,由多个研究机构共同推动,如德国汉堡大学、波兰华沙大学等。这些数据集的核心研究问题在于如何通过计算机视觉和自然语言处理技术,实现手语的自动识别与翻译,从而为听障人士提供更好的沟通工具。这些数据集的出现极大地推动了手语识别与翻译领域的发展,为相关算法的训练与评估提供了丰富的资源。
当前挑战
手语识别与翻译领域面临诸多挑战。首先,手语的多样性和复杂性使得数据标注和模型训练变得极为困难。手语不仅涉及手势,还包括面部表情、身体姿态等多种非语言信息,如何有效地捕捉并建模这些信息是一个关键问题。其次,数据集的构建过程中,数据采集和标注的难度较大,尤其是在多语言环境下,不同手语之间的差异增加了数据处理的复杂性。此外,手语的连续性和上下文依赖性也对模型的实时性和准确性提出了更高的要求。最后,数据集的开放性和许可问题也限制了其广泛应用,部分数据集由于隐私保护等原因无法公开下载,影响了研究的可重复性和推广性。
常用场景
经典使用场景
在自然语言处理领域,手语识别数据集如DGS、PJM、RWTH-PHOENIX等被广泛应用于手语翻译和生成任务。这些数据集通常包含大量手语视频及其对应的文本注释,研究者利用这些数据进行模型训练,以实现从手语到文本或语音的自动翻译。例如,RWTH-PHOENIX数据集因其高质量的天气播报手语视频而成为手语翻译研究的基准数据集。
解决学术问题
这些手语数据集解决了手语识别和翻译中的多个关键学术问题,如手语动作的时空建模、手语与自然语言之间的对齐问题以及跨语言手语翻译的挑战。通过提供丰富的标注数据,研究者能够开发出更精确的模型,提升手语识别的准确性和翻译的流畅性。例如,AUTSL数据集通过提供RGB、深度和骨骼数据,帮助研究者更好地理解手语动作的三维空间特征。
衍生相关工作
基于这些手语数据集,研究者们提出了多种经典的手语识别和翻译模型。例如,RWTH-PHOENIX数据集催生了Progressive Transformers和Mixture Density Networks等模型,用于连续手语生成任务。WLASL数据集则推动了基于骨架和视觉特征的多流神经网络模型的发展,显著提升了手语识别的准确性。此外,AUTSL数据集的应用还促进了基于深度学习的多模态手语识别系统的研究。
以上内容由遇见数据集搜集并总结生成


