Discord-Dialogues
收藏Hugging Face2025-08-15 更新2025-08-16 收录
下载链接:
https://huggingface.co/datasets/mookiezi/Discord-Dialogues
下载链接
链接失效反馈官方服务:
资源简介:
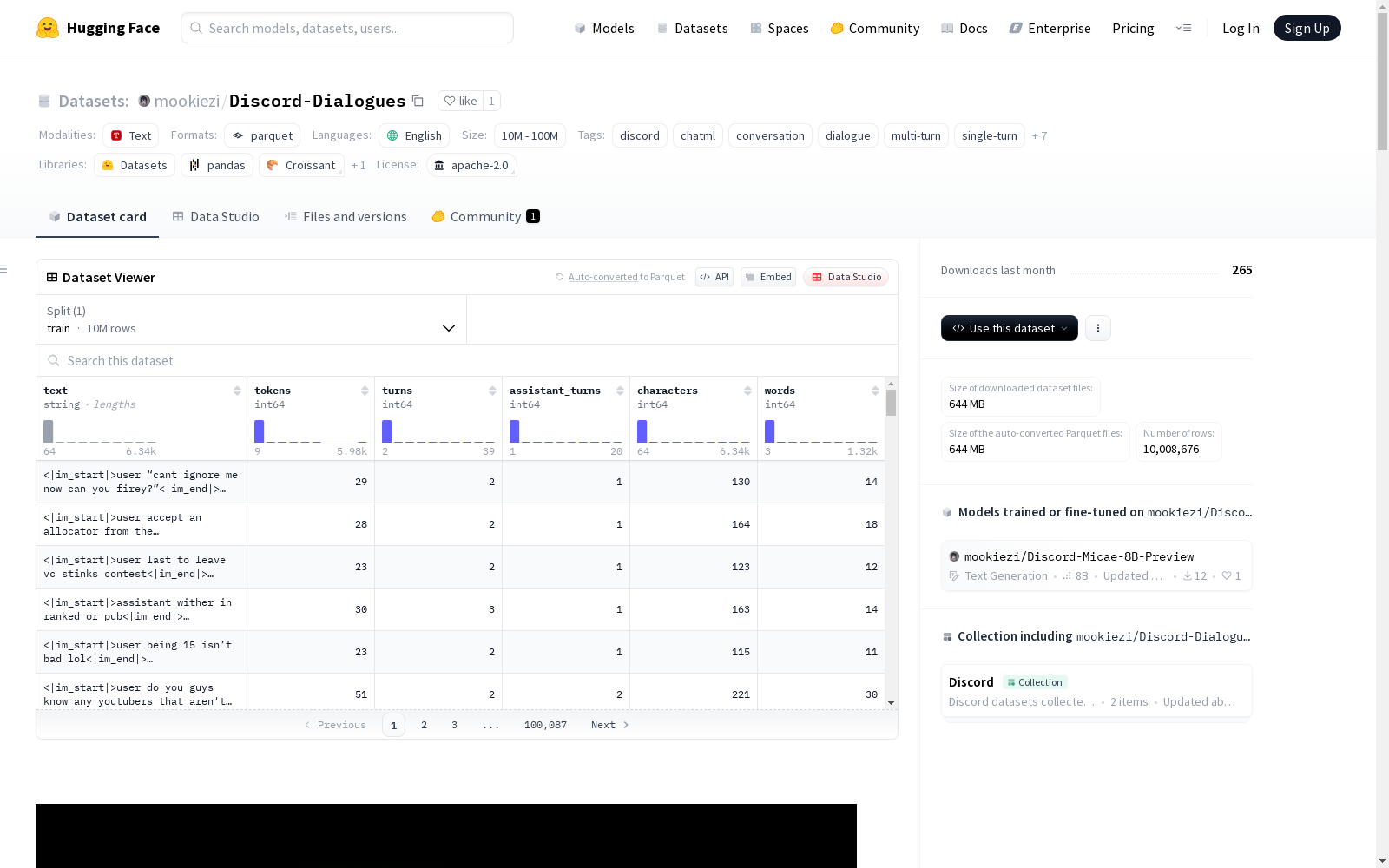
Discord-Dialogues是一个大规模的匿名化Discord对话数据集,适用于训练和评估会话AI模型,以ChatML友好的格式提供。数据集包含混合的单次和多次对话交流,仅包含人类对话,并经过清理以去除链接、嵌入、命令以及违规或不安全内容。该数据集主要适用于对话模型的微调、相关性和奖励模型的训练以及对话生成研究。
创建时间:
2025-08-12
搜集汇总
数据集介绍
构建方式
Discord-Dialogues数据集通过严格遵循Discord服务条款,从匿名化的Discord对话中精心构建而成。原始数据经过多轮清洗,剔除了机器人对话、链接、嵌入内容及命令代码等非自然语言元素,仅保留纯粹的人类双人对话。采用ChatML兼容格式对数据进行结构化处理,合并了同一作者的自回复消息,并通过去重和过滤机制确保对话质量,最终形成规模达千万级的语料库。
特点
该数据集以多轮对话为主轴,同时包含单轮交流样本,全面覆盖日常对话的多样性。其核心特征体现在严格的纯人类对话筛选机制,所有样本均经过长度标准化处理,平均token数控制在36左右。数据分布呈现典型的长尾特征,绝大多数对话集中在16-64个token区间,且包含少量超长对话样本,为模型训练提供了丰富的语境变化。英语为主导语言的同时,适度保留了其他语言的对话实例。
使用方法
作为对话AI研究的优质资源,该数据集特别适配于微调对话生成模型与训练奖励模型。使用时可加载ChatML格式数据,建议结合具体研究目标进行二次筛选,重点关注2-5轮的中等长度对话样本以获得最佳训练效果。数据已预分割为可直接输入模型的token序列,支持使用标准transformer架构进行端到端训练,也可通过统计分析方法挖掘对话模式特征。
背景与挑战
背景概述
Discord-Dialogues数据集由研究者mookiezi于2025年构建,是一个大规模匿名化的Discord对话数据集,旨在为对话式人工智能模型的训练与评估提供丰富资源。该数据集以ChatML友好格式呈现,涵盖了单轮和多轮对话,严格过滤了机器人对话、链接及命令等非自然交互内容,保留了纯人类对话的原始特征。作为开源项目,其遵循Apache 2.0许可协议,显著推动了开放领域对话生成、奖励模型训练等研究方向的发展,并为社交平台语境下的自然语言处理研究提供了独特视角。
当前挑战
该数据集面临的核心挑战体现在两方面:领域问题层面,如何精准捕捉非结构化社交对话中的语义连贯性与语境依赖性,成为对话系统泛化能力提升的关键瓶颈;构建过程层面,需克服数据匿名化与隐私保护的平衡难题,同时处理Discord平台特有的混合内容(如代码块、交易帖等),确保数据纯净度。此外,多语言混杂与对话长度极端差异(8至5979个token)对模型训练的稳定性提出了严峻考验。
常用场景
经典使用场景
Discord-Dialogues数据集在自然语言处理领域中被广泛用于训练和评估对话生成模型。其丰富的多轮对话和单轮对话混合结构,为研究人员提供了一个接近真实人类交流的语料库。特别是在ChatML格式的支持下,该数据集成为优化对话系统流畅性和连贯性的理想选择。
衍生相关工作
基于Discord-Dialogues,研究者们开发了多个经典模型,如Discord-Micae-Hermes-3-3B和Discord-OpenMicae。这些模型在对话生成和奖励模型训练中表现出色,进一步推动了开源社区在对话AI领域的发展。相关成果也为后续研究提供了重要的基线参考。
数据集最近研究
最新研究方向
在自然语言处理领域,Discord-Dialogues数据集因其大规模、多样化的对话内容而成为研究热点。该数据集涵盖了单轮和多轮对话,为训练和评估对话生成模型提供了丰富的语料。前沿研究主要集中在利用该数据集进行对话模型的微调,特别是在提升模型的上下文理解和多轮对话连贯性方面。此外,该数据集还被广泛用于奖励模型的训练,以优化生成内容的相关性和自然度。随着开源社区的推动,Discord-Dialogues在推动对话AI技术的发展中扮演了重要角色,其匿名化和去重处理也为数据隐私和安全研究提供了新的视角。
以上内容由遇见数据集搜集并总结生成


