ActionHub
收藏arXiv2024-01-22 更新2024-08-06 收录
下载链接:
http://arxiv.org/abs/2401.11654v1
下载链接
链接失效反馈官方服务:
资源简介:
ActionHub数据集是一个包含1211种常见人类动作和360万个视频描述的大规模数据集。该数据集通过使用动作名称在视频网站上进行搜索,自动收集视频描述,无需额外的人工标注,因此成本低且易于扩展。ActionHub旨在解决零样本动作识别中的跨模态多样性问题,通过提供丰富的动作视频描述来增强文本模态的语义多样性,从而帮助模型更好地理解视频中的人类动作。数据集的创建过程涉及从七个现有的视频动作数据集中构建动作查询,并通过网络搜索收集相关的视频描述。ActionHub数据集的应用领域主要集中在零样本动作识别,旨在通过学习视频和文本数据之间的有效对齐来识别未见过的动作。
ActionHub Dataset is a large-scale dataset containing 1,211 common human actions and 3.6 million video descriptions. This dataset automatically collects video descriptions by searching video websites with action names, requiring no additional manual annotation, thus featuring low cost and easy scalability. Designed to address the cross-modal diversity issue in zero-shot action recognition, ActionHub enhances the semantic diversity of the text modality by providing abundant action-related video descriptions, thereby enabling models to better comprehend human actions in videos. The dataset construction process involves constructing action queries from seven existing video action datasets and collecting relevant video descriptions via web searches. The primary application scope of the ActionHub Dataset is zero-shot action recognition, where the goal is to recognize unseen actions by learning effective alignment between video and text data.
提供机构:
中山大学计算机科学与工程学院
创建时间:
2024-01-22
搜集汇总
数据集介绍
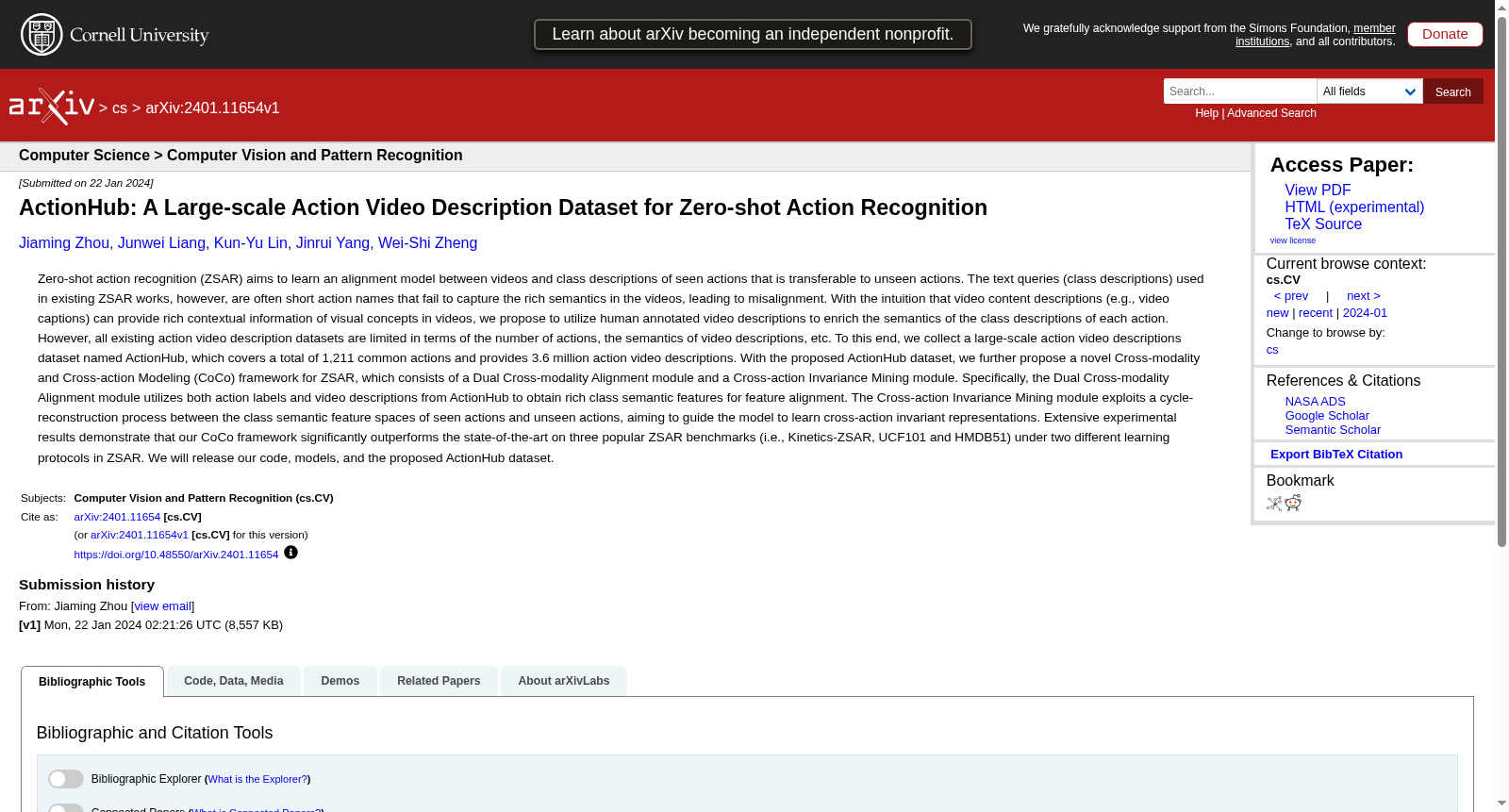
构建方式
在视频动作识别领域,零样本学习旨在通过已见动作的视频与文本描述之间的对齐模型,泛化至未见动作的识别。然而,现有数据集中动作类别的文本描述往往局限于简短的动作名称或定义,难以捕捉视频中丰富的视觉语义,导致跨模态对齐的多样性鸿沟。为应对这一挑战,ActionHub数据集通过自动化采集方法构建,其过程始于整合七个主流视频动作数据集(如Kinetics-700、UCF101等)中的1490个动作名称,经过去重和词形还原后,形成1211个独特的动作查询。随后,以每个动作名称作为搜索词,在公开视频素材网站中检索相关视频,并直接提取网站用户上传时提供的视频描述文本,无需额外人工标注。最终,数据集汇集了360万条视频描述,覆盖1211个常见人类动作,总计包含1010万句子,以低成本、高可扩展性的方式,为动作语义提供了丰富的上下文信息。
特点
ActionHub数据集在零样本动作识别领域展现出多项显著特点。其规模宏大,涵盖1211个多样化的人类动作,远超现有动作视频描述数据集的动作类别数量,且动作来源广泛,避免了特定领域(如室内或烹饪动作)的局限性。数据集中每条视频描述均由用户生成,蕴含丰富的视觉概念语义,如场景、物体、人物互动等,能够有效弥补传统动作名称或定义在文本多样性上的不足。此外,数据集通过自动化采集实现高效扩展,避免了昂贵的人工标注成本,同时保持了描述文本与视频内容的高度相关性。这些特点共同助力模型在跨模态对齐中减少语义鸿沟,提升对未见动作的泛化能力。
使用方法
ActionHub数据集的使用主要围绕零样本动作识别任务展开,旨在通过丰富的视频描述文本增强动作类别的语义表示。在实际应用中,研究者可首先利用数据集中提供的视频描述,与传统的动作定义相结合,构建每个动作类别的多样化文本特征。例如,通过预训练的语言模型(如BERT)提取描述文本的嵌入表示,并与视频视觉特征进行对齐学习。具体而言,可采用双跨模态对齐模块,同时利用动作定义和视频描述,学习视频特征与类别语义特征之间的映射关系。此外,通过跨动作不变性挖掘模块,在已见和未见动作的语义特征空间中进行循环重构,约束语义一致性,以学习更具泛化能力的表征。该数据集可直接应用于现有零样本动作识别框架(如CoCo),在Kinetics-ZSAR、UCF101等基准数据集上验证模型性能,推动视频与语言模态对齐的前沿研究。
背景与挑战
背景概述
在视频理解领域,零样本动作识别旨在通过已见动作的视频与类别描述学习可迁移的对齐模型,以识别未见动作。然而,现有方法通常依赖简短的动作名称或定义作为文本模态输入,其语义丰富度难以匹配视频中复杂的场景、动态人体运动等多样化视觉概念,导致跨模态语义鸿沟。为应对这一挑战,由周嘉明、梁俊伟、林坤宇、杨金睿、郑伟诗等研究人员于2024年构建了ActionHub数据集。该数据集作为首个大规模动作视频描述数据集,涵盖了1,211种常见人类动作,并提供了360万条视频描述,通过从公开视频网站自动采集用户上传的文本描述,以低成本、高可扩展性的方式丰富了动作的语义表示。ActionHub的发布为零样本动作识别研究提供了关键的文本模态资源,显著缓解了视频与文本之间的语义差异,推动了跨模态对齐模型的发展,并为视频-语言基础模型在动作领域的训练奠定了数据基础。
当前挑战
ActionHub数据集主要应对零样本动作识别领域的核心挑战:跨模态语义鸿沟。具体而言,现有方法使用的文本查询(如动作名称)语义稀疏,难以捕捉视频中丰富的视觉概念,导致模型无法有效对齐视频与文本特征。构建过程中的挑战包括:1)数据规模与多样性平衡:需覆盖大规模动作类别(1,211类)并确保动作来自多样领域(如日常、运动、烹饪),避免现有数据集的领域偏差问题;2)描述质量与噪声控制:自动采集的网络视频描述需筛选高相关性内容,以提供丰富上下文信息,同时减少语义噪声对模型学习的干扰;3)可扩展性与成本约束:依赖用户生成内容而非人工标注,需设计高效的查询与去重流程,在低成本前提下实现数据集的持续扩展。
常用场景
经典使用场景
在零样本动作识别领域,ActionHub数据集通过提供大规模动作视频描述,成为弥合视频与文本模态间语义鸿沟的关键资源。该数据集包含1211个常见动作类别及360万条视频描述,其经典应用场景在于训练跨模态对齐模型,使模型能够利用已见动作的视觉与文本数据,学习可迁移的语义对齐,从而实现对未见动作的准确识别。
解决学术问题
ActionHub数据集主要解决了零样本动作识别中视频与文本模态间的语义多样性不匹配问题。传统方法依赖简短的动作名称或定义,难以捕捉视频中丰富的视觉概念,导致跨模态对齐效果受限。该数据集通过提供详尽的视频描述,增强了动作类别的语义表达,有效缩小了模态间差异,提升了模型对未见动作的泛化能力,推动了零样本学习在视频理解领域的进展。
衍生相关工作
基于ActionHub数据集,研究者提出了跨模态与跨动作建模框架,如CoCo方法,其包含双重跨模态对齐模块与跨动作不变性挖掘模块。这些工作进一步推动了零样本动作识别模型的创新,例如利用视频描述进行实例级语义对齐,或通过循环重构学习跨动作不变表示。相关研究已在Kinetics-ZSAR、UCF101等基准测试中取得显著性能提升,验证了数据集的驱动价值。
以上内容由遇见数据集搜集并总结生成


