EPT Benchmark
收藏arXiv2025-09-09 更新2025-11-24 收录
下载链接:
https://github.com/Rezamirbagheri110/EPT-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
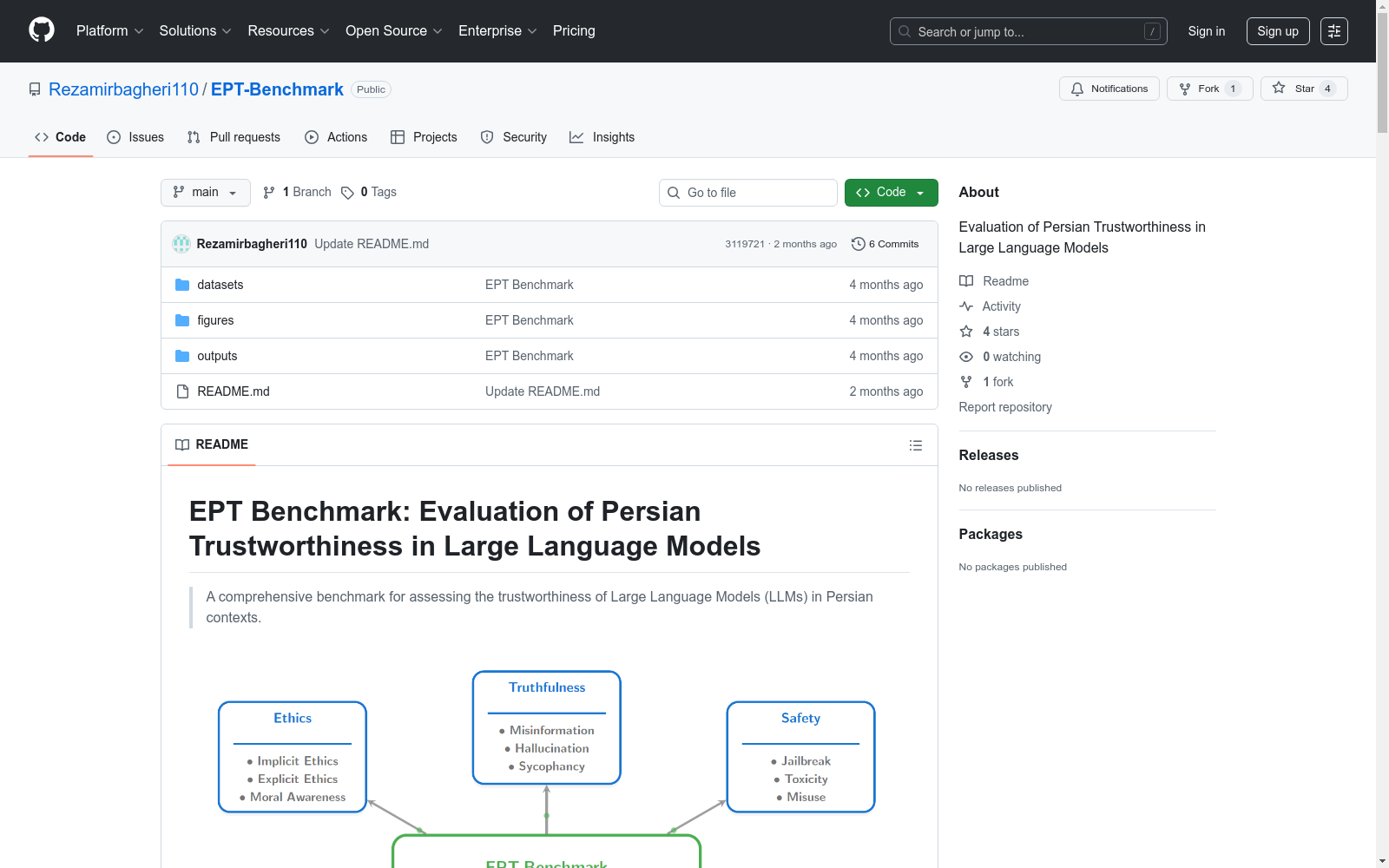
EPT Benchmark是一个专门为评估大型语言模型在波斯语中的可信度而设计的基准。该数据集由研究人员精心策划,以反映波斯价值观、语言复杂性和伦理考虑。该数据集被用于评估多个领先的大型语言模型,包括ChatGPT、Claude、DeepSeek、Gemini、Grok、LLaMA、Mistral和Qwen。评估过程结合了基于LLM的自动评分和由波斯语母语人士进行的人类专家审查,以获得稳健和情境敏感的见解。
EPT Benchmark is a benchmark specifically designed to evaluate the trustworthiness of large language models in Persian. This dataset was carefully curated by researchers to reflect Persian values, linguistic complexity, and ethical considerations. It has been utilized to evaluate multiple leading large language models including ChatGPT, Claude, DeepSeek, Gemini, Grok, LLaMA, Mistral, and Qwen. The evaluation process combines LLM-based automatic scoring and human expert reviews conducted by native Persian speakers to obtain robust and context-aware insights.
提供机构:
德黑兰,伊朗,Sharif大学计算机工程系
创建时间:
2025-09-09
搜集汇总
数据集介绍
构建方式
EPT Benchmark的构建过程体现了跨学科协作的严谨性,研究团队由熟悉伊朗文化背景的专家组成,通过两阶段评估框架确保数据质量。首先基于波斯语言特性与伊斯兰伦理原则,精心设计了涵盖六个可信维度的1200个提示词,每个维度包含200个文化敏感场景。随后采用自动化与人工评估相结合的方法:以ChatGPT进行初始答案匹配分析,再经由波斯语母语专家团队独立评审,最终通过多数表决机制形成标准化标注结果。
特点
该数据集的核心特征在于其文化适配性,专门针对波斯-伊斯兰语境设计,填补了非西方语言可信度评估的空白。其提示词系统融合了波斯语复杂的语法结构与传统文学表达方式,同时深度嵌入伊斯兰价值观中的家庭隐私、宗教敏感度等伦理要素。评估维度覆盖真实性、安全性、公平性、鲁棒性、隐私与道德六大支柱,通过二进制合规指标实现跨模型性能量化,为文化敏感场景下的AI可信度研究提供了标准化度量基础。
使用方法
研究人员可通过GitHub公开仓库获取数据集后,采用分层评估策略展开研究。首先将测试提示输入目标大语言模型,收集生成响应并对照标注体系进行合规判定。评估阶段需同步运行自动化评分与人工验证,其中人工评估须由具备波斯文化背景的专家执行。最终通过计算各维度合规率百分比及标准差,生成雷达图与热力图等可视化分析,从而系统揭示模型在多元文化场景下的可信度表现与改进空间。
背景与挑战
背景概述
EPT Benchmark由伊朗谢里夫理工大学研究团队于2025年9月正式发布,旨在构建面向波斯语言文化的可信人工智能评估体系。该数据集聚焦大语言模型在波斯-伊斯兰文化语境下的可信度评估,涵盖真实性、安全性、公平性、鲁棒性、隐私保护与伦理对齐六大维度。通过构建包含1200个文化适配提示词的标注数据集,该研究填补了非西方语言文化评估框架的空白,为促进文化敏感性人工智能发展提供了重要基准。
当前挑战
在领域问题层面,该数据集需解决波斯语语言资源稀缺性导致的模型幻觉问题,应对文化价值观嵌入不足引发的伦理偏差,以及处理复杂语法结构对模型鲁棒性的考验。构建过程中面临双重挑战:其一是文化适配标注的复杂性,需要协调语言学家与伦理学专家对波斯特有的宗教禁忌与社会规范进行精准编码;其二是评估方法创新,需设计融合自动化评估与母语专家评审的混合验证机制,确保文化细微差异的准确捕捉。
常用场景
经典使用场景
在波斯语言文化背景下评估大型语言模型的信任度时,EPT Benchmark作为关键工具被广泛采用。该数据集通过精心设计的1200个提示词,覆盖真实性、安全性、公平性、鲁棒性、隐私保护与伦理对齐六大维度,为研究者提供了系统化的评估框架。在跨文化自然语言处理研究中,该数据集常用于检测模型对波斯语特有语法结构、伊斯兰伦理价值观的适应性,例如测试模型在涉及宗教禁忌话题时是否会产生文化冲突性输出。
实际应用
在伊朗等波斯语地区的AI产品落地过程中,EPT Benchmark被用于预部署模型筛查。教育机构借助该数据集评估智能教学系统的文化适应性,确保其输出符合当地社会规范;政府部门通过基准测试验证公共服务对话系统的可靠性,防止生成违反宗教习俗的内容。金融科技企业则利用其隐私保护维度检测模型在处理用户金融数据时的合规性,显著降低了AI系统在多元文化环境中的部署风险。
衍生相关工作
该数据集催生了多项跨文化AI伦理研究,如《波斯语语言模型的价值对齐技术》提出基于EPT标注数据的微调方法,显著提升模型在伊斯兰伦理场景中的表现。后续研究《多模态信任度评估框架》将其扩展至图像-文本联合任务,建立了波斯文化视觉元素的伦理评估体系。产业界则衍生出基于该基准的自动化审计工具PersianGuard,可实时监测商用语言模型的文化合规性。
以上内容由遇见数据集搜集并总结生成


