full-modality-data
收藏Hugging Face2025-08-01 更新2025-08-02 收录
下载链接:
https://huggingface.co/datasets/ngqtrung/full-modality-data
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集包含了多模态视频问答对,需要同时使用视觉和音频信息来正确回答问题。问题覆盖了多个类别,包括时间推理、因果关系分析、场景描述等。所有问题都是开放式的。
创建时间:
2025-08-01
原始信息汇总
Full Modality Dataset 概述
基本信息
- 许可证: MIT
- 标签: 多模态, 视频问答, 视听
- 任务类别: 问答
- 语言: 英语
- 规模: 1M<n<10M
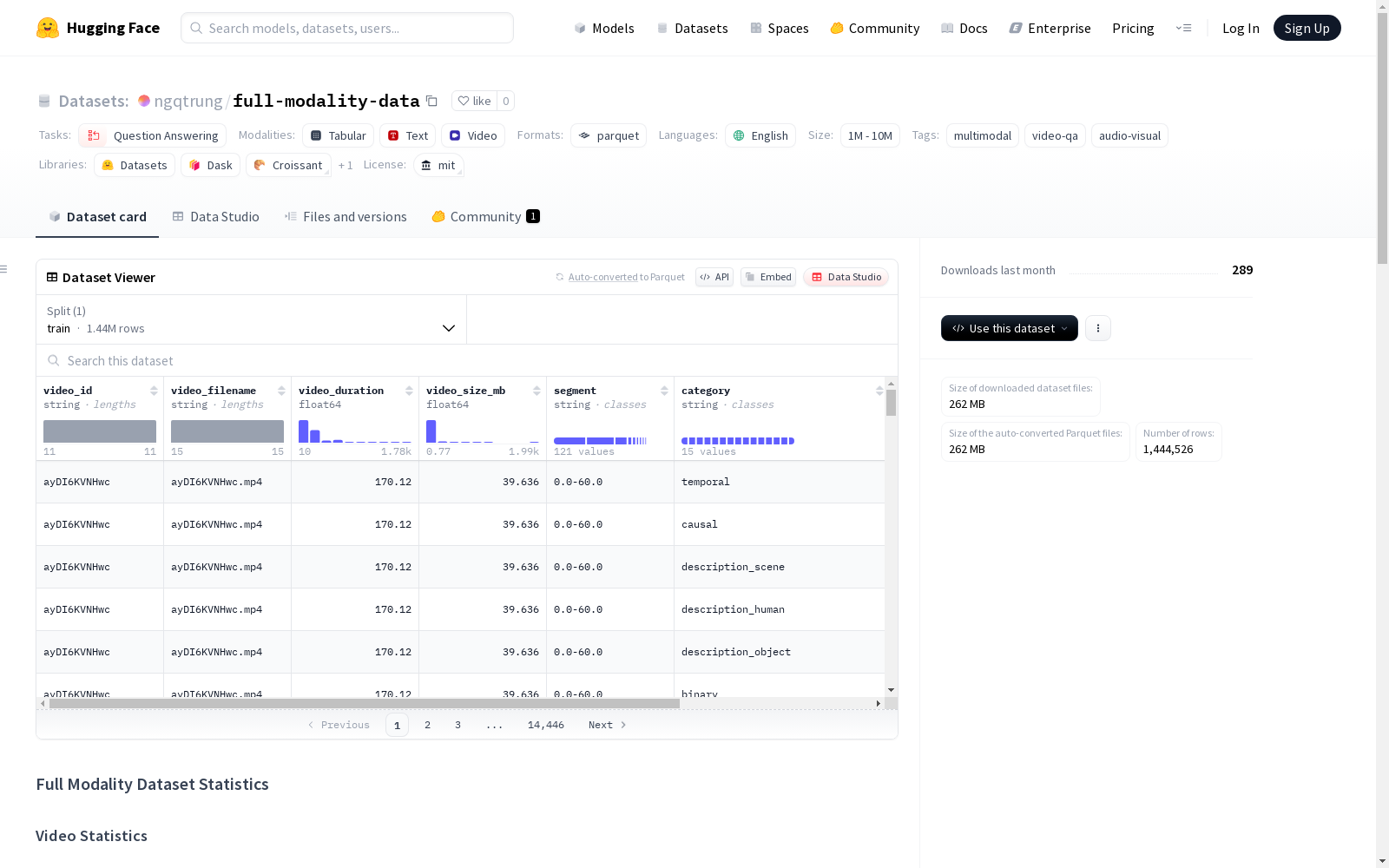
视频统计
- 视频总数: 28,472
- 总时长: 1422.33小时
- 平均时长: 179.84秒
- 中位数时长: 160.08秒
- 时长范围: 10.04秒 - 1780.03秒
问答统计
- 问题总数: 1,444,526
- 平均每视频问题数: 50.7
- 每视频问题数范围: 14 - 450
问题类型分布
- 开放式问题 (OE): 1,444,526 (100.0%)
问题类别分布
- 时间推理 (temporal): 96,873 (6.7%)
- 因果分析 (causal): 96,873 (6.7%)
- 场景描述 (description_scene): 96,873 (6.7%)
- 人物描述 (description_human): 96,873 (6.7%)
- 物体描述 (description_object): 96,873 (6.7%)
- 二元问题 (binary): 96,873 (6.7%)
- 细粒度动作理解 (fine_grained_action_understanding): 96,873 (6.7%)
- 情节理解 (plot_understanding): 96,873 (6.7%)
- 不存在动作 (non_existent_actions): 96,873 (6.7%)
- 时间顺序理解 (time_order_understanding): 96,873 (6.7%)
- 属性变化 (attribute_change): 96,873 (6.7%)
- 视听对话一致性 (audio_visual_dialogue_consistency): 96,873 (6.7%)
- 视听潜台词 (audio_visual_subtext): 96,873 (6.7%)
- 视听情绪 (audio_visual_mood): 96,873 (6.7%)
- 空间推理 (spatial_reasoning): 88,304 (6.1%)
数据集描述
该数据集包含多模态视频问答对,需要视觉和音频信息才能正确回答。问题涵盖多个类别,包括时间推理、因果分析、场景描述等。所有问题均为开放式格式。
数据集结构
包含以下列:
video_id: 视频的唯一标识符video_filename: 视频的原始文件名video_duration: 视频时长(秒)video_size_mb: 视频文件大小(MB)segment: 视频中的时间段(格式:开始时间-结束时间)category: 问题类别question: 问题文本(开放式格式)answer: 正确答案
使用方法
python from datasets import load_dataset
dataset = load_dataset("ngqtrung/full-modality-data")
按类别筛选
temporal_questions = dataset.filter(lambda x: x[category] == temporal) causal_questions = dataset.filter(lambda x: x[category] == causal)
获取唯一类别
categories = set(dataset[category]) print(f"Available categories: {categories}")
搜集汇总
数据集介绍
构建方式
在多媒体智能研究领域,full-modality-data数据集通过系统化采集与标注流程构建而成。该数据集整合了28,472段总时长超过1,422小时的视频素材,每段视频平均配备50.7个开放式问题,形成总计1,444,526个问答对。视频素材经过严格的时间分段处理,标注团队针对每个片段设计了涵盖15种认知维度的问答内容,包括时间推理、因果分析、场景描述等类别,确保问题类型分布均衡。标注过程采用双重校验机制,保证问答对与视频内容的强相关性。
使用方法
该数据集通过HuggingFace平台提供便捷的Python接口调用,研究者可使用datasets库直接加载。典型应用场景包括多模态表示学习、视听问答系统开发等。加载后的数据支持按问题类别过滤,例如提取时间推理或因果分析类子集进行分析。数据集中每个样本包含视频元信息、时间片段标记、问题类别及标准答案,研究者可结合视频文件进行端到端建模。特别建议利用set(dataset['category'])方法获取完整类别体系,以便设计针对性的评估方案。
背景与挑战
背景概述
full-modality-data数据集是近年来多模态学习领域的重要资源,由研究人员ngqtrung于2023年构建并发布。该数据集聚焦于视频问答任务,旨在推动视听联合理解的研究。数据集包含28,472段总时长超过1400小时的视频,配套生成144万条开放式问题,覆盖时间推理、因果分析、场景描述等15类认知任务。其创新性在于严格设计需要同时解析视觉内容和音频线索的问题,为多模态推理建立了新的基准。该资源已被广泛应用于跨模态表示学习、视听对齐等前沿方向,显著促进了人机交互系统的认知能力发展。
当前挑战
构建full-modality-data面临双重挑战:在领域问题层面,视频问答需克服模态异构性带来的表征对齐难题,特别是时间敏感型问题要求精确的跨模态事件定位。数据集中占比6.7%的音频视觉一致性类别问题,暴露出当前模型在跨模态矛盾检测方面的薄弱环节。在构建过程中,确保问题质量与视频内容深度耦合成为关键瓶颈,每个视频平均需人工生成50.7个问题,且需维持15个类别间的严格平衡。此外,处理1780秒超长视频的时序标注消耗了大量计算资源,而开放式答案的评估标准制定亦耗费研究者大量精力。
常用场景
经典使用场景
在多媒体理解领域,full-modality-data数据集因其丰富的视频和问答对资源,成为研究多模态学习的经典基准。该数据集特别适用于开发视频问答系统,研究者可通过分析视频内容与对应问题,训练模型理解视觉与听觉信息的关联性。其开放性问题格式和多类别分布为模型评估提供了全面维度,尤其在时序推理和因果分析等复杂任务中展现出独特价值。
解决学术问题
该数据集有效解决了多模态融合中的关键科学问题,包括跨模态表征对齐、时序信息建模以及视听语义一致性验证。通过28,472段视频与144万问题的组合,研究者能够系统探索视听信号与自然语言理解的协同机制。其均衡的类别分布为消除模型偏见提供了数据基础,而细粒度动作理解等特殊类别则推动了复杂认知任务的算法突破。
实际应用
在实际应用层面,该数据集支撑了智能教育辅助系统的开发,通过解析教学视频内容自动生成知识问答;在无障碍技术领域,可训练系统为视障用户描述复杂场景中的视听关系;其细粒度的动作理解数据更被应用于体育训练分析,自动识别运动员动作细节并生成技术改进建议。
数据集最近研究
最新研究方向
在多媒体智能领域,full-modality-data数据集因其丰富的视频问答对和全面的模态信息,正成为跨模态理解研究的热点。该数据集覆盖了时间推理、因果分析、场景描述等多样化问题类型,为探索视听融合机制提供了理想平台。近期研究聚焦于如何通过端到端深度学习框架,实现视频内容与音频线索的协同理解,特别是在细粒度动作识别和时空推理任务中展现出突破性进展。随着多模态大语言模型的兴起,该数据集被广泛用于验证模型在开放域问答中的泛化能力,推动了人机交互场景下复杂语义解析技术的发展。
以上内容由遇见数据集搜集并总结生成


