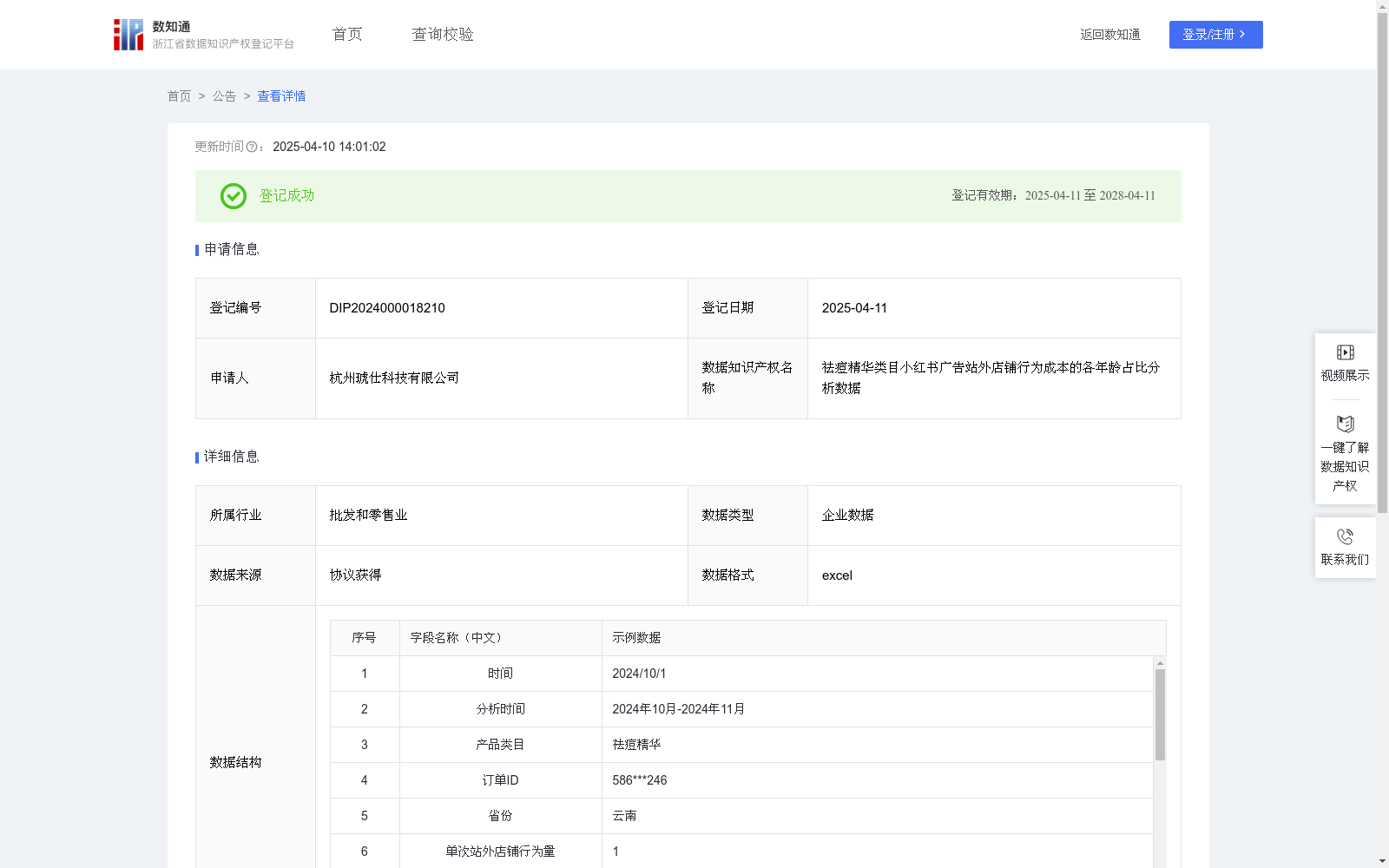
祛痘精华类目小红书广告站外店铺行为成本的各年龄占比分析数据
收藏浙江省数据知识产权登记平台2025-04-10 更新2025-04-11 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/122757
下载链接
链接失效反馈官方服务:
资源简介:
通过该数据,能深入了解小红书平台对于祛痘精华类目产品的兴趣人群,数据集包含了单次站外店铺行为量、<18、18-22、23-27、28-32、>32以上的总站外店铺行为量以及对应的站外店铺行为量占比。
通过分析不同年龄人群的广告站外店铺行为量情况占比,祛痘精华类目品牌可以更精准地进行市场细分,针对不同年龄段的消费者特点和需求,制定相应的产品和营销策略。优化广告投放渠道和内容,提高广告的针对性和效果,减少无效的支出。此外祛痘精华类目行业可以评估各年龄段市场的潜力,优先投入资源开发那些具有较大增长潜力的市场,利用趋势调整市场策略
1.数据处理:从公司小红书平台渠道系统数据库中收集到的2024年10-11月祛痘精华类目的用户数据,本数据包括统计时间段内祛痘精华类目产品的订单ID、省份、单次站外店铺行为量、总站外店铺行为量、<18总站外店铺行为量、18-22总站外店铺行为量、23-27总站外店铺行为量、28-32总站外店铺行为量、>32总站外店铺行为量和对应站外店铺行为量占比。将收集到的祛痘精华类目的数据进行归集,对数据进行加工、筛选、统计、分析。
2.算法规则:<18总站外店铺行为量/总站外店铺行为量=<18总站外店铺行为量占比,以此类推。
3.通过统计、筛选得到综合分析结果。为企业管理者和政策制定者在经营中进行营销战略制定和市场指导,以满足不同年龄用户的需求和偏好。
提供机构:
杭州琥仕科技有限公司
创建时间:
2024-12-02
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集为祛痘精华类目在小红书平台的广告站外店铺行为成本分析数据,包含3470条记录,主要统计了不同年龄段用户的站外店铺行为量及占比,用于市场细分和广告策略优化。
以上内容由遇见数据集搜集并总结生成


