Audio-Transcription-Models-Comparison-PT-BR
收藏Hugging Face2026-01-22 更新2026-01-23 收录
下载链接:
https://huggingface.co/datasets/tech4humans/Audio-Transcription-Models-Comparison-PT-BR
下载链接
链接失效反馈官方服务:
资源简介:
该数据集专门用于比较现代语音转文本(STT)模型在巴西葡萄牙语中的性能。数据集包含了不同AI模型在具有挑战性的场景下的转录结果,涵盖了地区性词汇、口音、文化表达、非正式和不流畅的语音、以及数字实体等内容。数据集还包括了多种模型的性能比较,如Word Error Rate (WER)、Real-Time Factor (RTF)和Words Per Second (WPS)等指标。此外,数据集还提供了实验追踪和可重复性的详细信息,以及一个公开的Weights & Biases (W&B)仪表板。
创建时间:
2026-01-15
原始信息汇总
Audio Transcription Models Comparison 数据集概述
数据集基本信息
- 任务类别: 自动语音识别
- 语言: 葡萄牙语
- 特定语言: 巴西葡萄牙语
- 标签: asr, speech-recognition, brazilian-portuguese, low-resource, noisy-speech, benchmark-dataset, speech-to-text, audio, benchmark, evaluation, wer, pt-br, whisper, gpt-4o, gemini, qwen2-audio, mistral, nvidia-parakeet, gemma
- 许可证: Apache-2.0
数据集内容与特征
该数据集专用于比较现代语音转文本模型在巴西葡萄牙语上的性能。其核心目标是评估模型在具有挑战性的现实场景中的表现,重点关注:
- 地域性: 本地词汇、口音和文化表达。
- 非正式性与不流畅性: 包含犹豫、口吃、句中修正和口语化表达的自然语音。
- 数字实体: 对数值、日期、时间和数量的转录精确度。
数据特征
数据集包含以下字段:
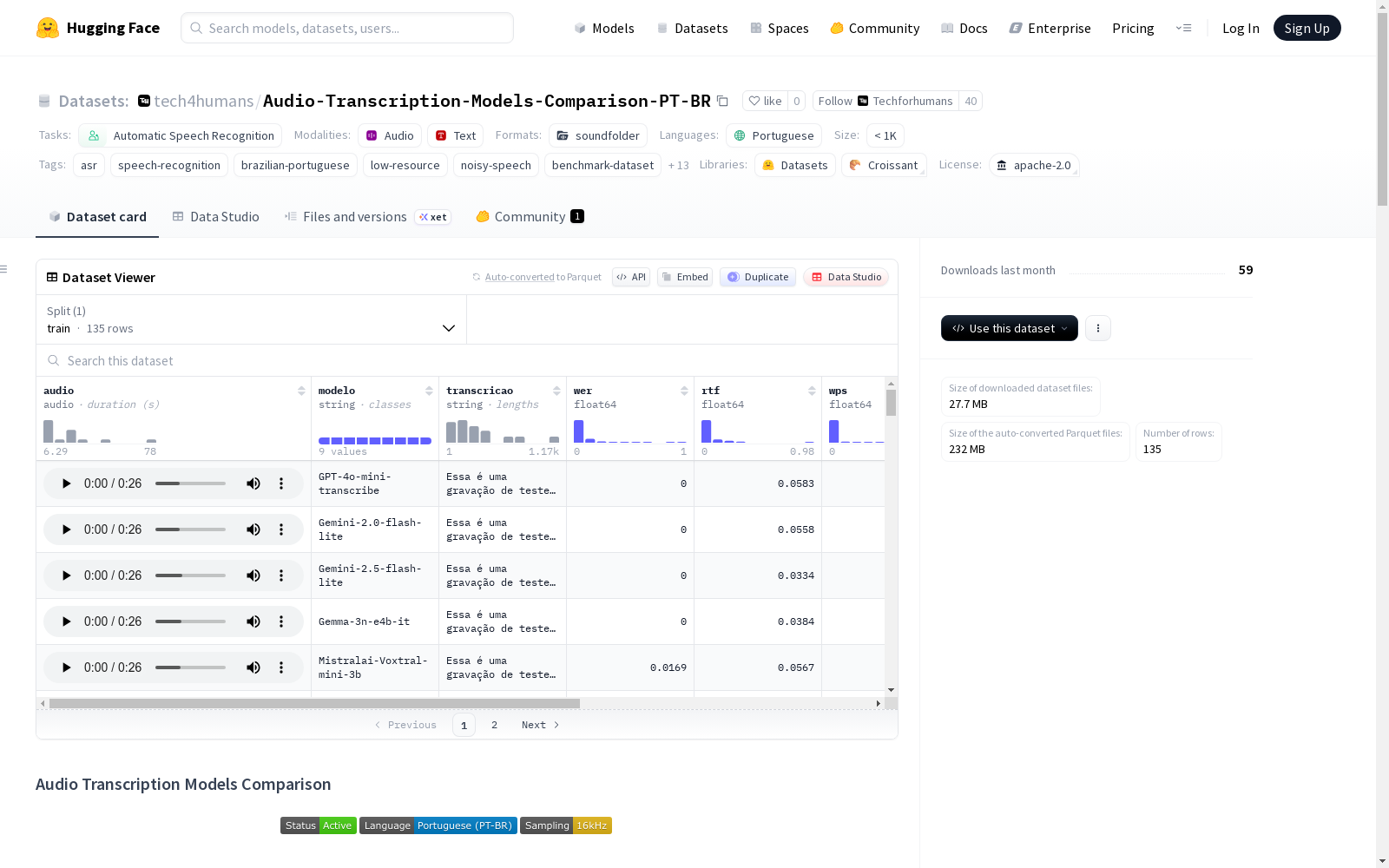
audio: 音频数据,采样率为16000 Hz。file_name: 文件名。modelo: 模型名称。transcricao: 转录文本。wer: 词错误率。rtf: 实时因子。wps: 每秒处理词数。desvio_padrao: 标准差。status: 状态。error_analysis: 错误分析。
评估模型
数据集包含以下语音转文本架构的转录结果:
- OpenAI Whisper (
large-v3,large-v3-turbo) - OpenAI GPT-4o-mini-transcribe
- Google Gemini-2.0-Flash-Lite
- Google Gemini-2.5-Flash-Lite
- Google Gemma-3n-e4b-it
- Qwen2-Audio-7b-instruct
- Nvidia/Parakeet-tdt-0.6b-v3
- MistralAI/Voxtral-Mini-3B-2507
基准构建与方法论
该数据集是本项目中所有基准测试的主要数据来源,用于:
- 计算词错误率、实时因子和每秒处理词数等定量指标。
- 在相同的音频条件下进行跨模型比较。
- 聚合和分析结果以生成基准测试中的图表和表格。
- 对具有挑战性的巴西葡萄牙语音频样本进行定性和定量错误分析。
实验追踪与可复现性
所有转录实验、评估和比较均通过 Weights & Biases 进行记录和追踪。
- 公共W&B仪表板: https://api.wandb.ai/links/anna-ferreira-tech4humans/y46ek9xd
性能排行榜
| 排名 | 模型 | WER ↓ | RTF ↓ |
|---|---|---|---|
| 🥇 1 | Gemini 2.0 Flash Lite | 0.1052 | 0.0881 |
| 🥈 2 | Whisper Large v3 Turbo | 0.0667 | 0.1627 |
| 🥉 3 | GPT-4o-mini-transcribe | 0.0794 | 0.0918 |
| 4 | Gemini 2.5 Flash Lite | 0.1141 | 0.1766 |
| 5 | Whisper Large v3 | 0.0790 | 0.1664 |
| 6 | NVIDIA Parakeet | 0.1159 | 0.0081 |
| 7 | Mistral Voxtral | 0.0860 | — |
| 8 | Gemma 3n | 0.1448 | 0.0397 |
| 9 | Qwen2-Audio | 0.2662 | 0.0452 |
预期用途与局限性
- 预期用途: 用于巴西葡萄牙语ASR模型的基准测试和评估。
- 局限性: 不代表葡萄牙语的所有口音和地域变体。
加载方式
python from datasets import load_dataset dataset = load_dataset("tech4humans/Audio-Transcription-Models-Comparison-PT-BR")
搜集汇总
数据集介绍
构建方式
在语音识别领域,针对巴西葡萄牙语这一特定语言环境的评估资源相对稀缺。该数据集的构建过程聚焦于现实应用场景,精心选取涵盖区域方言、非正式表达及数字实体等挑战性内容的音频样本。通过整合多种前沿语音转文本模型,包括Whisper、GPT-4o、Gemini等系列架构,在统一音频条件下生成转录文本,并系统计算词错误率、实时因子及每秒词数等量化指标。所有实验均通过Weights & Biases平台进行追踪记录,确保了评估过程的透明性与可复现性,为低资源语言场景下的模型比较提供了严谨的基准框架。
特点
该数据集的核心特征在于其专注于巴西葡萄牙语的真实语言复杂性,深入捕捉了当地方言、口语化表达及文化特定词汇等语言细微差别。数据集不仅收录了多模型在相同音频样本上的转录结果,更提供了词错误率、处理效率及误差分析等多维度评估指标,形成立体化的性能画像。其独特价值体现在对非流畅语音、数字实体识别等现实挑战的针对性覆盖,以及通过标准化度量实现跨模型公平比较的能力,为研究低资源语言环境下的语音识别技术提供了珍贵的实证数据。
使用方法
研究人员可通过Hugging Face数据集库直接加载该资源,利用其结构化字段进行模型性能的横向对比分析。数据集支持基于词错误率、实时因子等核心指标的模型排序,同时提供转录文本与误差分析字段,便于开展细粒度的语言学错误模式研究。该资源适用于构建巴西葡萄牙语语音识别系统的基准测试流程,亦可用于探究不同模型架构对特定语言现象的适应能力。通过集成到现有评估管道中,能够有效加速低资源语言场景下语音技术的迭代优化进程。
背景与挑战
背景概述
在自动语音识别技术迅猛发展的背景下,针对特定语言资源的系统性评估显得尤为重要。Audio-Transcription-Models-Comparison-PT-BR数据集由tech4humans团队创建,专注于巴西葡萄牙语的语音转文本模型性能比较。该数据集旨在解决低资源语言环境下,现代ASR模型对区域性词汇、口音、非流利表达及数字实体转录的泛化能力问题。通过整合包括Whisper、GPT-4o、Gemini在内的多种前沿架构转录结果,该数据集为巴西葡萄牙语ASR研究提供了关键基准,推动了语言技术在该语种上的公平性与可复现性评估。
当前挑战
该数据集致力于应对巴西葡萄牙语自动语音识别领域的核心挑战,即模型在真实场景中对区域性口音、文化特有表达及非正式口语的准确转录。构建过程中的挑战集中于采集具有代表性的音频样本,这些样本需涵盖广泛的区域变体与自然言语现象,如犹豫、修正及数字信息,同时确保标注的一致性与高质量。此外,在低资源语言环境下,平衡不同ASR模型的计算效率与转录精度,并设计公平的评估指标以进行跨模型比较,亦是数据集构建中需克服的关键难题。
常用场景
经典使用场景
在自动语音识别领域,针对低资源语言和特定方言的模型评估一直是研究的关键挑战。Audio-Transcription-Models-Comparison-PT-BR数据集专注于巴西葡萄牙语,其经典使用场景在于为不同语音转文本模型提供一个统一的基准测试平台。该数据集通过包含区域性词汇、非正式表达及数字实体等真实语音特征,使研究人员能够在相同音频条件下系统比较各模型的转录性能,从而推动针对特定语言变体的模型优化与选择。
衍生相关工作
围绕该数据集衍生的经典工作主要包括基于其基准结果的模型优化研究。例如,针对Whisper和Gemini等模型在巴西葡萄牙语上的错误分析,催生了针对区域性发音的微调策略。同时,数据集支撑的跨架构比较研究,为开发轻量级、高效率的语音识别模型提供了实证依据,进一步推动了低资源语言处理领域的算法创新与工程实践。
数据集最近研究
最新研究方向
在低资源语言处理领域,巴西葡萄牙语自动语音识别研究正聚焦于模型在真实场景下的鲁棒性评估。前沿工作利用该数据集,系统比较了Whisper、GPT-4o、Gemini等主流架构对地域口音、非正式表达及数字实体的转录精度。研究热点紧密关联多模态大模型在语音任务上的适配与优化,通过引入词错误率、实时因子等量化指标,深入分析模型在噪声环境与语言特性下的泛化能力。这类基准测试不仅推动了葡萄牙语语音技术的实用化进程,也为低资源语言的公平性评估提供了可复现的实证基础。
以上内容由遇见数据集搜集并总结生成


