LongViTU
收藏LongViTU 数据集概述
数据集简介
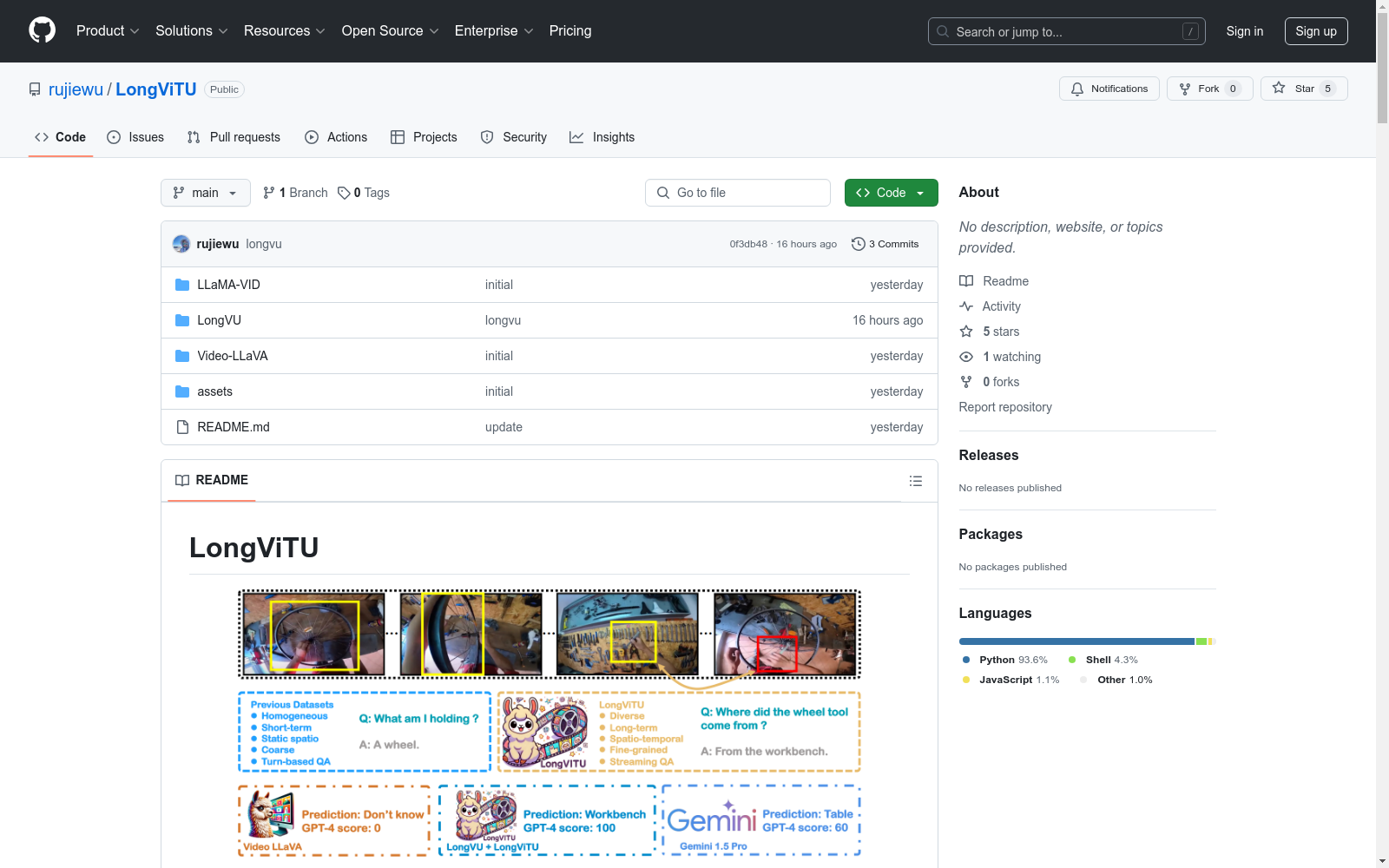
LongViTU 是一个用于长视频理解的大规模数据集,包含约121k个问答对和约900小时的视频。该数据集通过系统化的方法生成,视频内容被组织成层次树结构,并引入了自我修订机制以确保高质量的问答对。每个问答对具有以下特点:
- 长期上下文:平均上下文长度为4.6分钟。
- 丰富的知识和推理:包含常识、因果关系、规划等内容。
- 明确的时间戳标签:为相关事件提供时间戳。
数据集特点
- 规模:121k个问答对,900小时视频。
- 结构:视频内容被组织成层次树结构,支持多时间尺度的信息提取。
- 质量保证:通过自我修订机制去除冗余和不相关信息,确保数据质量。
- 应用场景:作为长视频理解和流媒体视频理解的基准数据集。
数据集评估
LongViTU 数据集被用于评估开源和商业模型在长视频理解任务中的表现。评估结果显示:
- 开源模型 LongVU:在 LongViTU 基准上得分为55.9,优于商业模型 Gemini-1.5-Pro 的52.3分。
- 性能提升:通过对 LongVU 进行监督微调(SFT),在 LongViTU 基准上提升了12.0%,在其他基准(如 EgoSchema、VideoMME、WorldQA 和 OpenEQA)上也有显著提升。
数据集结构
数据集文件结构如下: plain LongViTU ├── dataset │ └── longvitu │ ├── videos │ │ ├── 0000_ed90c2e8-c608-423f-a565-7b4cfffbe438.mp4 │ │ ├── 0001_80d2d992-0765-4fd9-b75b-7334cfefbd6f.mp4 │ │ ├── .... │ │ └── 1832_cdfd99eb-88c6-4bc7-8f66-e0318216feab.mp4 │ ├── longvitu_train_101k.json │ ├── longvitu_valid_14k.json │ └── longvitu_test_6k.json
数据集下载与使用
- 视频数据:从 Ego4D 下载。
- 标注文件:从 Hugging Face 下载。
引用
如果您在研究中使用了 LongViTU 数据集,请引用以下论文: bibtex @misc{wu2025longvituinstructiontuninglongform, title={LongViTU: Instruction Tuning for Long-Form Video Understanding}, author={Rujie Wu and Xiaojian Ma and Hai Ci and Yue Fan and Yuxuan Wang and Haozhe Zhao and Qing Li and Yizhou Wang}, year={2025}, eprint={2501.05037}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2501.05037}, }
许可证
- 代码:Apache 许可证。
- 数据:CC BY-NC-SA 4.0 许可证。