InstaDeepAI/nucleotide_transformer_downstream_tasks
收藏Hugging Face2025-06-30 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/InstaDeepAI/nucleotide_transformer_downstream_tasks
下载链接
链接失效反馈官方服务:
资源简介:
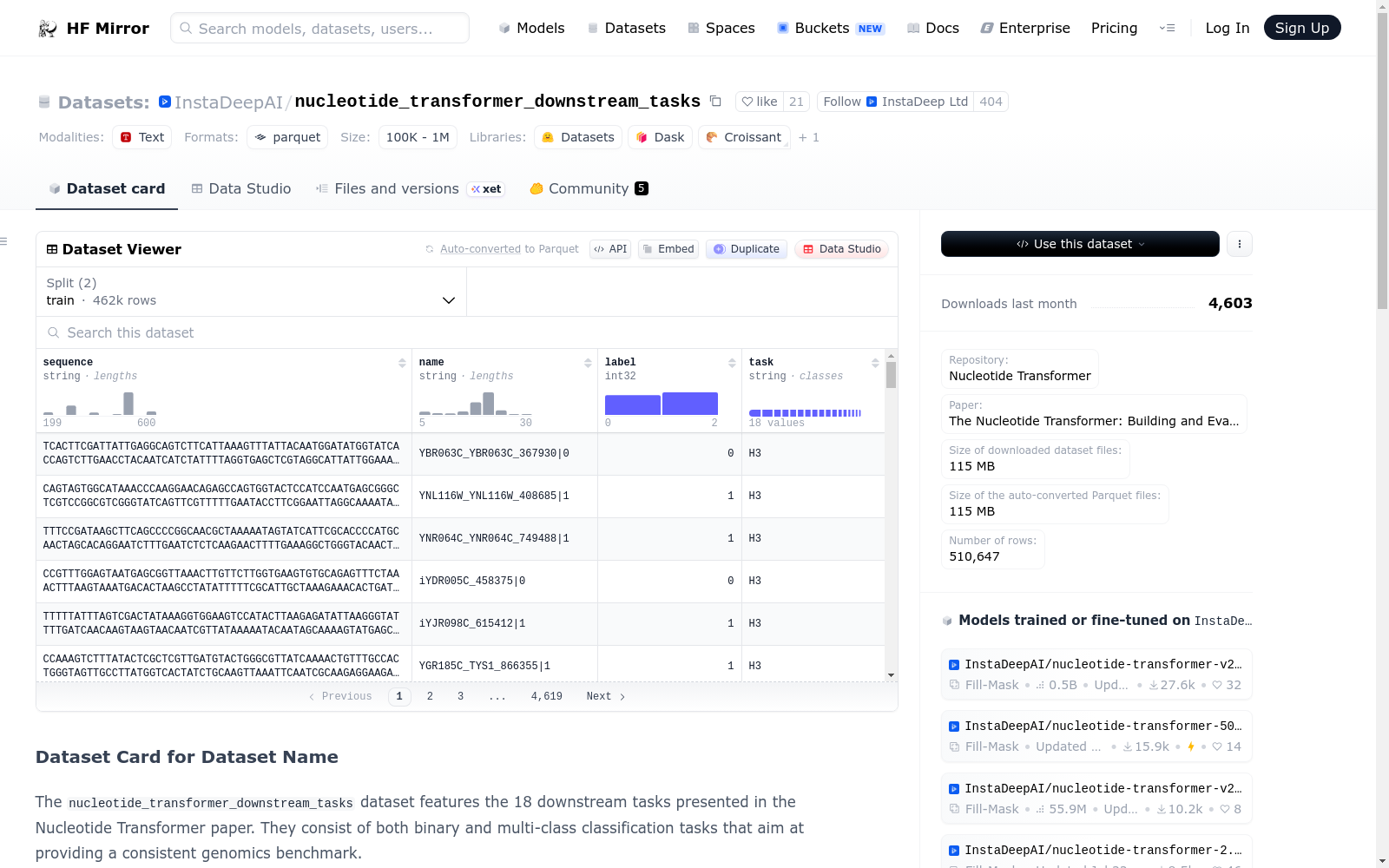
`nucleotide_transformer_downstream_tasks`数据集包含了Nucleotide Transformer论文中提出的18个下游任务。这些任务包括二分类和多分类任务,旨在提供一个一致的基因组学基准。数据集的结构部分详细列出了每个任务的训练序列数量、测试序列数量、标签数量和序列长度。
`nucleotide_transformer_downstream_tasks`数据集包含了Nucleotide Transformer论文中提出的18个下游任务。这些任务包括二分类和多分类任务,旨在提供一个一致的基因组学基准。数据集的结构部分详细列出了每个任务的训练序列数量、测试序列数量、标签数量和序列长度。
提供机构:
InstaDeepAI
原始信息汇总
数据集卡片 for nucleotide_transformer_downstream_tasks
数据集描述
nucleotide_transformer_downstream_tasks 数据集包含了 Nucleotide Transformer 论文中介绍的 18 个下游任务。这些任务包括二分类和多分类任务,旨在提供一个一致的基因组学基准。
数据集摘要
这些不同的数据集来自 4 篇不同的基因组学论文:
-
DeePromoter: Robust Promoter Predictor Using Deep Learning
- 数据集包含 3,065 个 TATA 启动子和 26,532 个非 TATA 启动子,每个启动子通过随机采样序列片段生成负样本。
promoter_all数据集包含所有启动子及其负样本,而promoter_tata和promoter_no_tata分别提供 TATA 和非 TATA 部分的数据集。
- 数据集包含 3,065 个 TATA 启动子和 26,532 个非 TATA 启动子,每个启动子通过随机采样序列片段生成负样本。
-
A deep learning framework for enhancer prediction using word embedding and sequence generation
- 作者收集了 742 个强增强子、742 个弱增强子和 1484 个非增强子,并通过生成模型增加了 6000 个合成增强子和 6000 个合成非增强子。测试数据集包含 100 个强增强子、100 个弱增强子和 200 个非增强子。原始论文使用此数据集进行二分类(即样本被分类为非增强子或增强子)和三分类(即样本被分类为非增强子、弱增强子或强增强子)。这两个任务分别在
enhancers和enhancers_types数据集中处理。
- 作者收集了 742 个强增强子、742 个弱增强子和 1484 个非增强子,并通过生成模型增加了 6000 个合成增强子和 6000 个合成非增强子。测试数据集包含 100 个强增强子、100 个弱增强子和 200 个非增强子。原始论文使用此数据集进行二分类(即样本被分类为非增强子或增强子)和三分类(即样本被分类为非增强子、弱增强子或强增强子)。这两个任务分别在
-
SpliceFinder: ab initio prediction of splice sites using convolutional neural network
- 作者引入了一个包含 10,000 个供体位点、受体位点和非剪接位点样本的数据集,总共有 30,000 个样本,这些样本在
splice_sites_all数据集中展示。
- 作者引入了一个包含 10,000 个供体位点、受体位点和非剪接位点样本的数据集,总共有 30,000 个样本,这些样本在
-
Spliceator: multi-species splice site prediction using convolutional neural networks
- 该论文引入了两个数据集,每个数据集包含剪接位点及其对应的负样本。
splice_sites_acceptor数据集包含受体剪接位点,而splice_sites_donor数据集包含供体剪接位点。
- 该论文引入了两个数据集,每个数据集包含剪接位点及其对应的负样本。
-
Qualitatively predicting acetylation and methylation areas in DNA sequences
- 该论文引入了一系列数据集,展示了酵母基因组中识别的表观遗传标记,即乙酰化和甲基化核小体占据情况。这些十大数据集通过 Chip-Chip 实验获得核小体占据值,并进一步处理成正负观测值,对应以下组蛋白标记:
H3,H4,H3K9ac,H3K14ac,H4ac,H3K4me1,H3K4me2,H3K4me3,H3K36me3和H3K79me3。
- 该论文引入了一系列数据集,展示了酵母基因组中识别的表观遗传标记,即乙酰化和甲基化核小体占据情况。这些十大数据集通过 Chip-Chip 实验获得核小体占据值,并进一步处理成正负观测值,对应以下组蛋白标记:
数据集结构
| 任务 | 训练序列数量 | 测试序列数量 | 标签数量 | 序列长度 |
|---|---|---|---|---|
| promoter_all | 53,276 | 5,920 | 2 | 300 |
| promoter_tata | 5,509 | 621 | 2 | 300 |
| promoter_no_tata | 47,767 | 5,299 | 2 | 300 |
| enhancers | 14,968 | 400 | 2 | 200 |
| enhancers_types | 14,968 | 400 | 3 | 200 |
| splice_sites_all | 27,000 | 3,000 | 3 | 400 |
| splice_sites_acceptor | 19,961 | 2,218 | 2 | 600 |
| splice_sites_donor | 19,775 | 2,198 | 2 | 600 |
| H3 | 13,468 | 1,497 | 2 | 500 |
| H4 | 13,140 | 1,461 | 2 | 500 |
| H3K9ac | 25,003 | 2,779 | 2 | 500 |
| H3K14ac | 29,743 | 3,305 | 2 | 500 |
| H4ac | 30,685 | 3,410 | 2 | 500 |
| H3K4me1 | 28,509 | 3,168 | 2 | 500 |
| H3K4me2 | 27,614 | 3,069 | 2 | 500 |
| H3K4me3 | 33,119 | 3,680 | 2 | 500 |
| H3K36me3 | 31,392 | 3,488 | 2 | 500 |
| H3K79me3 | 25,953 | 2,884 | 2 | 500 |
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个基因组学基准测试集,包含18个下游任务,涵盖启动子预测、增强子分类、剪接位点识别和组蛋白修饰等多种任务。数据集格式为parquet,总行数超过510k,序列长度在200-600bp之间,适用于深度学习模型训练和评估。
以上内容由遇见数据集搜集并总结生成


