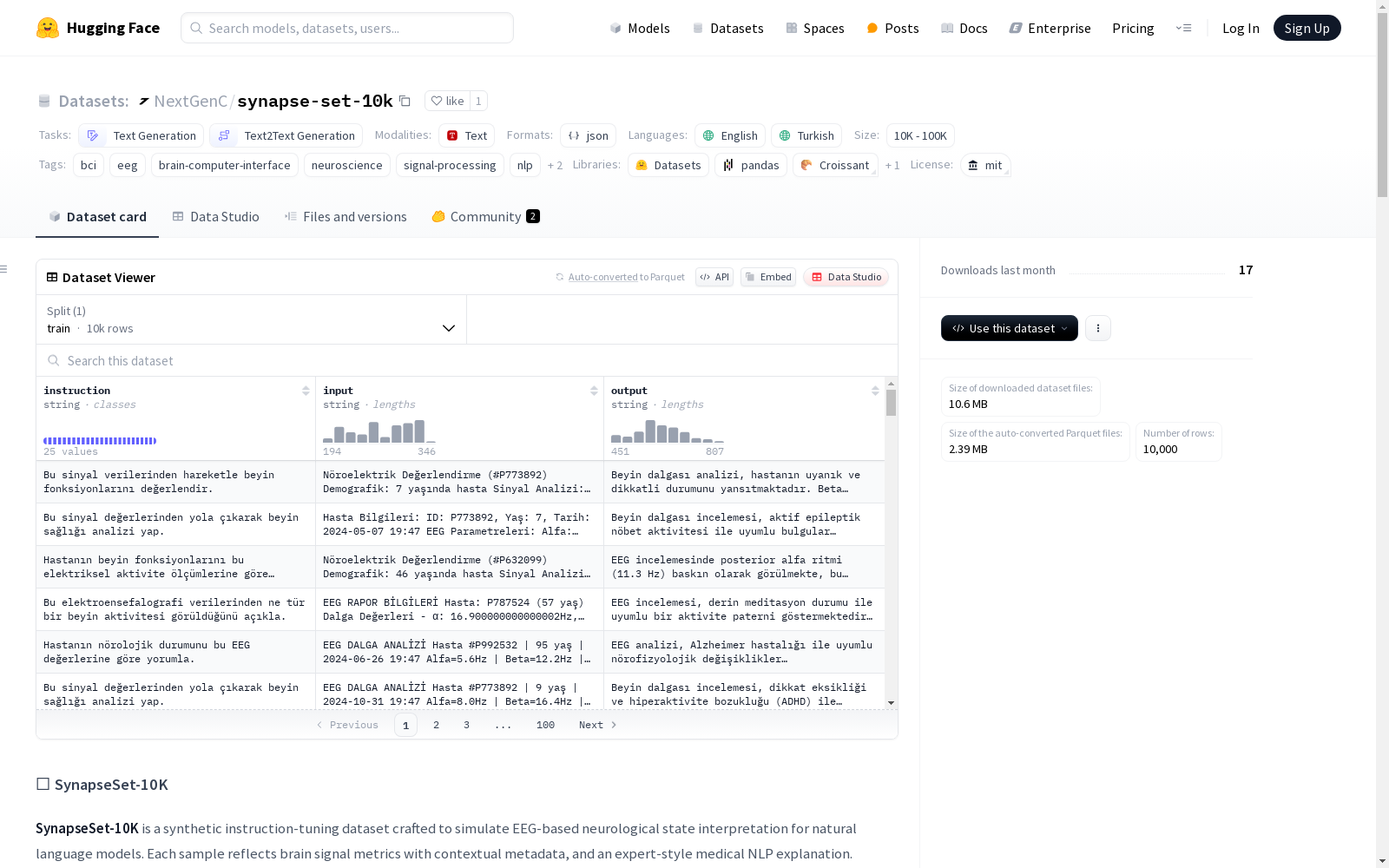
synapse-set-10k
收藏SynapseSet-10K: EEG Interpretation Dataset
数据集概述
- 名称: SynapseSet-10K
- 类型: 合成指令调优数据集
- 用途: 模拟基于EEG的神经状态解释,用于自然语言模型
- 数据来源: 7enn Labs生成
- 数据性质: 100%合成,非临床数据,仅供学术和研究使用
数据集特征
- 语言: 土耳其语
- 样本数量: 10,000
- 数据格式: JSON
- 内容:
instruction: 任务描述input: EEG信号指标与患者元数据output: 模拟临床解释
数据集格式示例
json { "instruction": "Interpret the given EEG values for a patient and explain their mental state.", "input": "Patient: ID#A7421 | Age: 38 | Date: 2024-10-12 | EEG: Alpha=9.8Hz, Beta=17.2Hz, Theta=4.1Hz, Delta=2.0Hz, Gamma=29.5Hz | Voltage=0.72mV", "output": "The EEG profile is consistent with relaxed wakefulness. Alpha wave dominance (9.8Hz) suggests the patient is in a calm, eyes-closed resting state. No signs of seizure activity or abnormal slowing are present." }
特性对比
| 特性 | SynapseSet-10K | SynapseSet-50K | SynapseSet-100K |
|---|---|---|---|
| 样本容量 | 10,000 | 50,000 | 100,000 |
| 语言 | 土耳其语 | 英语 | 英语 |
| 神经学条件 | 16 | 25+ | 50+ |
| EEG频段 | 5基础频段 | 5基础+6子频段 | 5基础+11子频段 |
| 数据格式 | 4种 | 6种 | 6种(增强) |
| 真实度 | 基础 | 中级 | 临床级 |
| 患者建模 | 简单 | 高级 | 全面医学档案 |
| 伪影建模 | 无 | 基础 | 全面(12+种) |
许可与伦理
- 许可证: MIT
- 要求:
- 必须明确披露使用合成数据
- 不可用于临床决策
- 使用风险自负,不提供任何保证
引用
bibtex @misc{7ennlabs2025synapseset, author = {7enn Labs}, title = {SynapseSet-10K: Synthetic Instruction Dataset for EEG Interpretation}, year = {2025}, url = {https://huggingface.co/datasets/NextGenC/synapse-set-100k}, note = {100% synthetic dataset for BCI/NLP research} }
示例用法
python from datasets import load_dataset dataset = load_dataset("DATASET_FILE_NAME") print(dataset["train"][0])
创建者
7enn Labs