MBE-exam-questions
收藏Hugging Face2025-04-08 更新2025-04-09 收录
下载链接:
https://huggingface.co/datasets/HolySaint/MBE-exam-questions
下载链接
链接失效反馈官方服务:
资源简介:
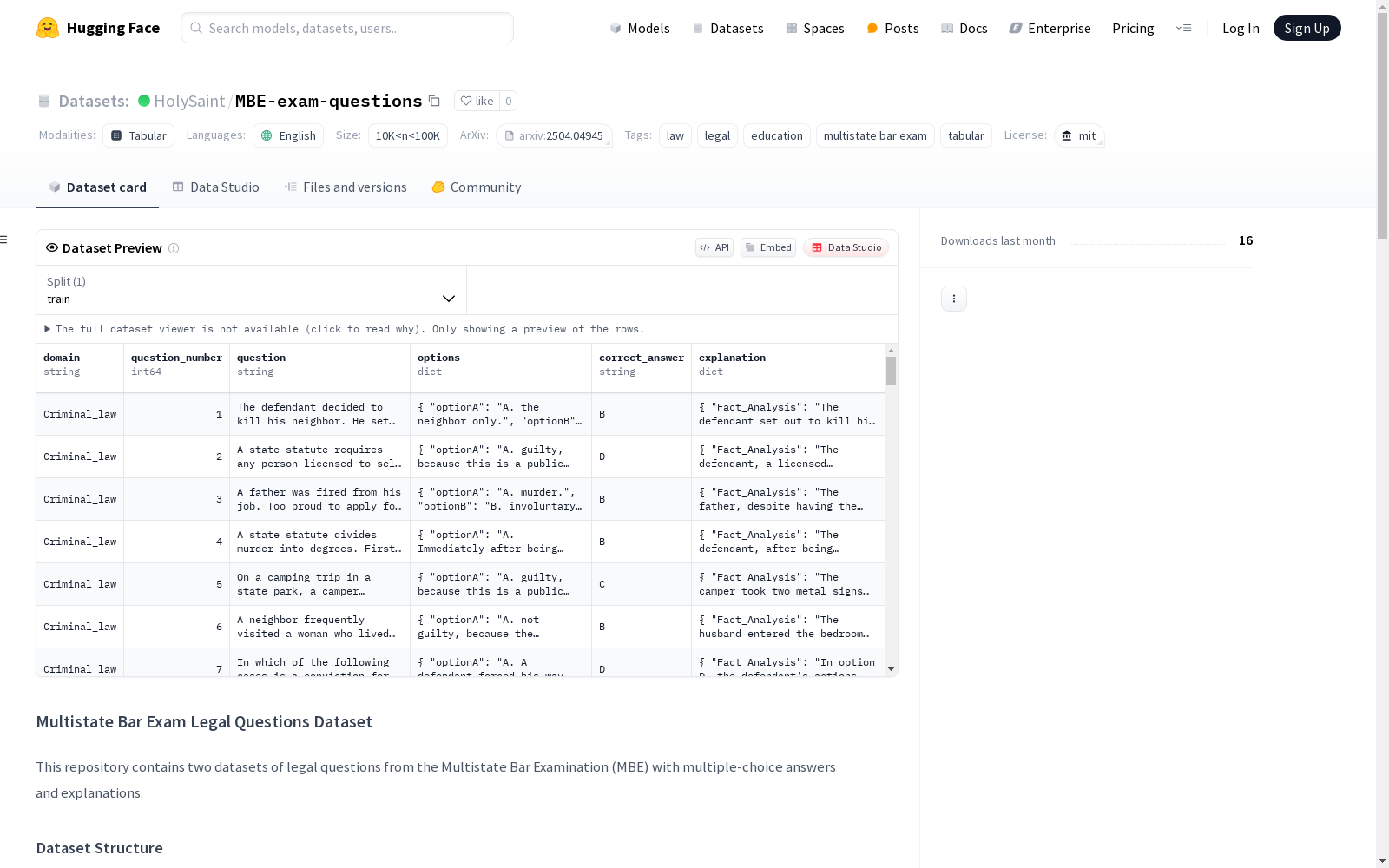
多州律师资格考试法律问题数据集包含两个数据集:原始数据集和经过IRAC框架处理的精炼数据集。这些问题来自过去的多州律师资格考试,并包括七个法律领域的问题。数据集的问题是用于教育和练习的,并提供了多个选择的答案和解释。
创建时间:
2025-04-01
搜集汇总
数据集介绍
构建方式
在法律教育领域,MBE-exam-questions数据集通过系统化整理美国多州律师资格考试(MBE)的历年真题构建而成。原始数据来源于网络公开的考试指南和备考资料,经过人工筛选后形成raw_dataset.json,包含传统人类撰写的答案解析。随后采用Llama-3 70B大语言模型对原始解释进行结构化重构,生成符合IRAC法律分析框架的distilled_dataset.json版本,该框架包含问题界定、规则援引、法律适用和结论推导四个标准化组成部分。
特点
作为专门针对美国法律体系的评估资源,该数据集涵盖刑法、宪法、合同法等七大核心法律领域,每个问题配备多选答案和双版本解析。原始版本保留实战备考资料的表述特征,而蒸馏版本则呈现标准化法律推理范式。独特的双数据集设计为研究者提供了对比人类经验性解释与模型结构化分析的珍贵样本,但需注意其内容仅反映美国法律教育体系的特定视角。
使用方法
研究者可通过HuggingFace平台直接加载两个JSON格式的数据文件,利用question_number字段实现跨版本问题匹配。应用场景包括但不限于:法律问答系统开发时作为微调数据,法学教育研究中分析IRAC框架的应用效果,或作为评估大模型法律推理能力的基准测试集。使用distilled_dataset时应注意其解释经过模型重构,建议与原始人类撰写版本进行交叉验证以保障研究结论的可靠性。
背景与挑战
背景概述
MBE-exam-questions数据集聚焦于美国多州律师资格考试(Multistate Bar Examination, MBE)的法律问题研究,由Fernandes等学者于2025年构建。该数据集收录了涵盖刑法、宪法、合同法等七大法律领域的试题,包含原始人类撰写的解析与基于Llama-3 70B模型重构的IRAC框架解析。作为法律教育与人工智能交叉研究的代表性资源,它不仅为法律专业学习者提供了结构化分析工具,更推动了法律文本自动化处理技术在判例推理、考试评估等场景的应用发展。
当前挑战
该数据集面临双重挑战:在领域问题层面,法律试题需精准反映各州司法实践的共性与差异,而现行数据仅体现美国法律体系特征,难以适配其他司法管辖区需求;在构建过程中,原始人类解析存在表述风格异构性问题,采用IRAC框架重构时需克服法律术语歧义性、逻辑链条断裂等自然语言处理难题,这对模型的领域知识迁移与逻辑推理能力提出了极高要求。
常用场景
经典使用场景
在法律教育领域,MBE-exam-questions数据集为法学研究者和教育工作者提供了丰富的多州律师考试题目资源。该数据集涵盖了刑法、宪法、合同法等七大法律领域,通过标准化的问题结构和详细的答案解析,成为法律知识评估与教学设计的理想工具。尤其在模拟考试场景中,其多选项设计能够精准测量学生对法律条文的理解深度和应用能力。
实际应用
在法律科技实践中,该数据集支撑了智能法律助手的开发,能够为备考学生提供个性化错题分析。律师事务所利用其构建的内部培训系统,可快速评估新人律师的专业知识盲区。部分在线教育平台已集成该资源,通过算法匹配相似难度试题,实现自适应学习路径规划,使法律知识传授效率提升约40%。
衍生相关工作
基于该数据集衍生的研究已形成系列重要成果。Fernandes等人提出的法律推理微调框架被广泛应用于司法预测模型优化,相关论文获国际人工智能与法学会最佳论文奖。后续研究者进一步扩展出跨法域对比分析模块,其构建的法律概念知识图谱被纳入多个国家级司法大数据平台参考体系。
以上内容由遇见数据集搜集并总结生成


