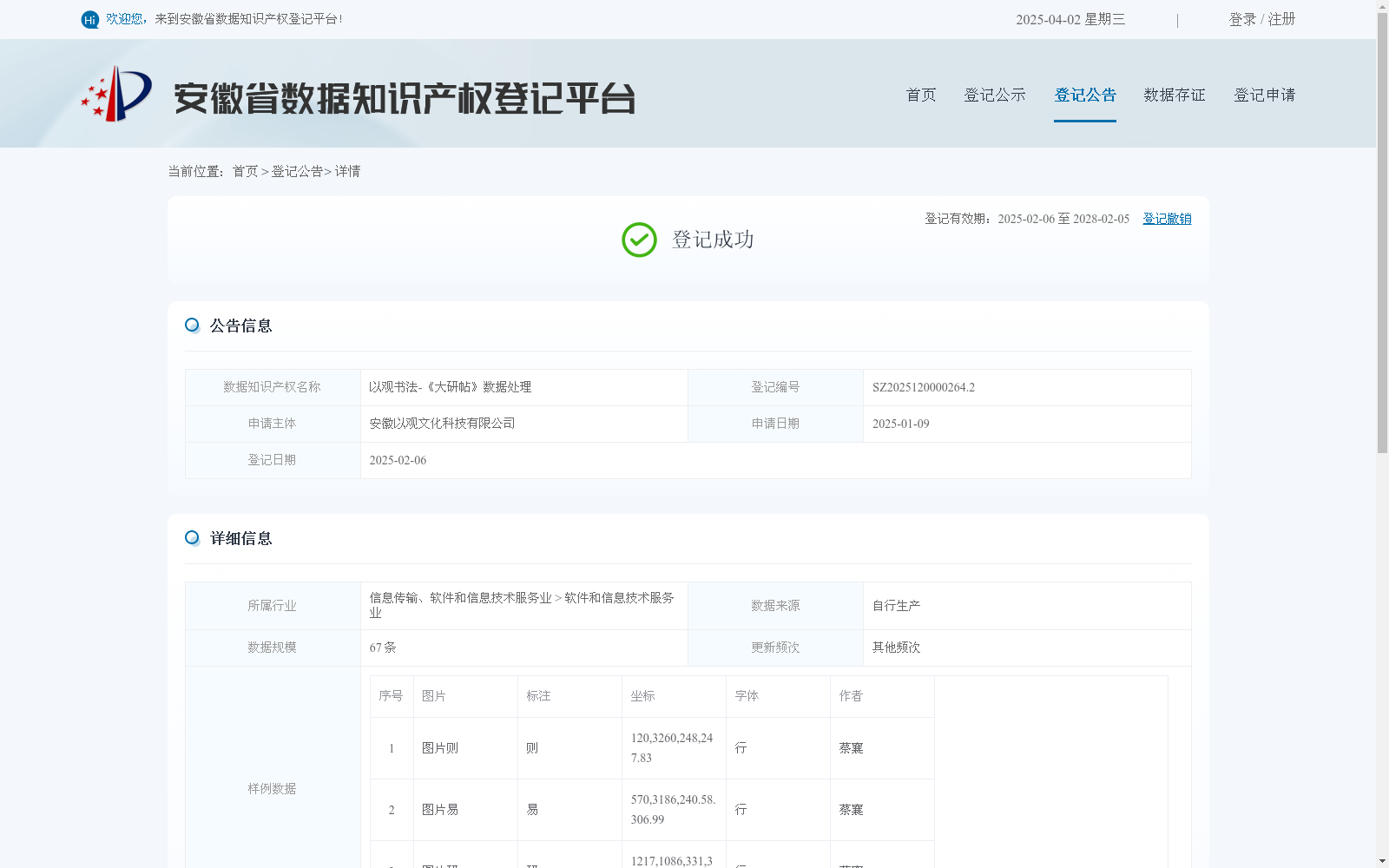
以观书法-《大研帖》数据处理
收藏安徽省数据知识产权登记平台2025-01-09 更新2025-02-06 收录
下载链接:
http://58.56.66.75:14401/#/registerAnnouncementDetail?id=97efdd45-e8a7-4a4e-87f4-7290d1f4428f&state=2
下载链接
链接失效反馈官方服务:
资源简介:
字帖图片为各大博物馆、图书馆、大学等提供的开放数据,标注、坐、字体、作者、来源均为人工处理。
The calligraphy copybook images are open datasets sourced from major museums, libraries, universities and other relevant institutions. All annotations, font sizes, typefaces, authors and sources have been manually curated.
提供机构:
安徽以观文化科技有限公司
创建时间:
2025-01-09
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


