osm-polygon-to-wikipedia-articles
收藏Hugging Face2026-06-30 更新2026-07-01 收录
下载链接:
https://huggingface.co/datasets/NoeFlandre/osm-polygon-to-wikipedia-articles
下载链接
链接失效反馈官方服务:
资源简介:
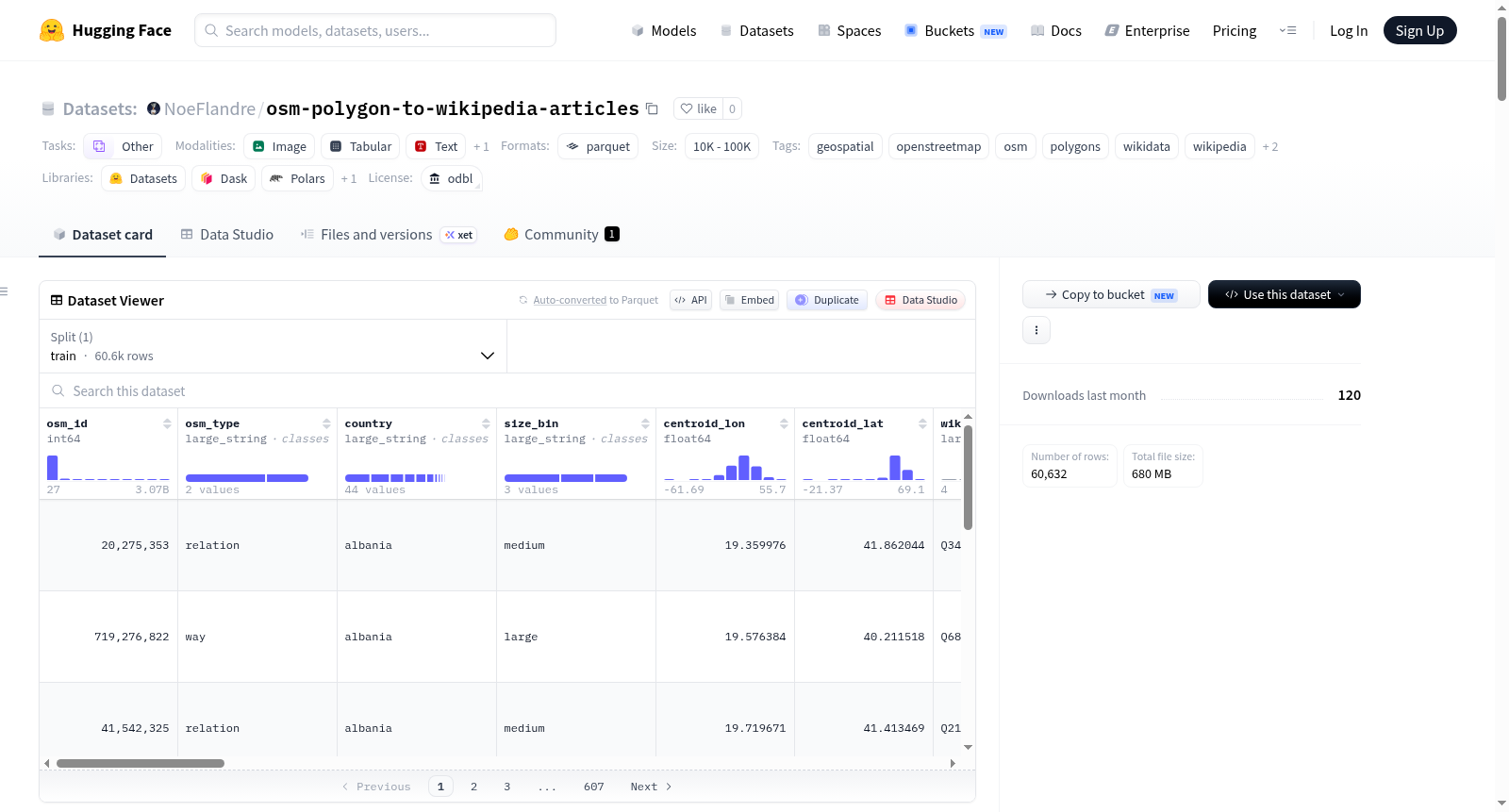
该数据集通过Wikidata QID黄金路径,将OpenStreetMap多边形与英文维基百科文章进行匹配,并按国家组织。数据集覆盖42个欧洲国家,包含20,214个成功匹配的多边形样本,每个样本对应一个真实的英文维基百科文章。每个数据行包含24个字段,整合了几何信息(多边形WKT、质心坐标)、维基百科内容(文章标题、摘要、完整纯文本正文)以及源数据属性(OSM标签、面积、日期等)。数据总文本量达6,686,124词,平均每篇文章331词。数据集以Parquet和JSONL格式提供,包含全量合并文件(all_wikidata.parquet)和分国家文件。适用于地理空间分析、多模态基础模型训练、知识图谱增强等任务。主要局限性包括仅支持英文、仅处理带有wikidata标签的多边形(约覆盖源数据的3%),且瑞典和德国尚未处理。
创建时间:
2026-06-29
原始信息汇总
数据集概述
该数据集将 OpenStreetMap(OSM)中的多边形(polygon)通过 Wikidata QID 关联到对应的英文 Wikipedia 文章,以国家为单位增量构建,目前包含 43 个欧洲国家的信息。
核心数据规模
| 指标 | 数值 |
|---|---|
| 已处理国家数 | 43 |
| 匹配成功多边形总数 | 24,595 |
| 成功获取文章正文的多边形数 | 24,567 |
| 每个数据行包含字段数 | 24 |
| 所有文章总词数 | 8,758,912 |
| 所有文章总字符数 | 54,758,443 |
| 平均每篇文章词数 | 357 |
数据文件
| 文件 | 行数 | 列数 | 说明 |
|---|---|---|---|
all_wikidata.parquet |
24,595 | 24 | 所有 43 个国家匹配结果的合并文件 |
all_wikidata_map.html |
— | — | 全部国家的交互式地图 |
all_wikidata_map.png |
— | — | 全部国家的静态地图截图 |
<country>_wikidata.parquet |
不定 | 24 | 单个国家的匹配结果(Parquet 格式) |
<country>_wikidata.jsonl |
不定 | 24 | 单个国家的匹配结果(JSONL 格式) |
<country>_wikidata_map.html |
— | — | 单个国家的交互式地图 |
<country>_wikidata_map.png |
— | — | 单个国家的静态地图 |
README.md |
— | — | 本说明文件 |
数据模式(Schema)
Wikidata 匹配阶段产生的字段:
| 字段 | 类型 | 描述 |
|---|---|---|
osm_id |
i64 | OSM 路径/关系 ID |
osm_type |
str | 类型(way 或 relation) |
country |
str | 国家代码(与源 parquet 文件名一致) |
size_bin |
str | OSM 多边形尺寸分类(tiny/small/medium/large/very_large) |
centroid_lon, centroid_lat |
f64 | 多边形在 WGS84 坐标系下的质心 |
wikidata_qid |
str | 从多边形 wikidata=* 标签解析出的 Wikidata ID |
sitelinks_count |
i64 | Wikidata 实体上的 Wikipedia 站点链接数量 |
article_title |
str | 匹配的英文 Wikipedia 文章标题 |
article_lang |
str | 文章语言(始终为 en) |
article_url |
str | 文章完整 URL |
match_status |
str | 匹配状态(始终为 matched,未匹配项已过滤) |
article_description |
str? | REST 摘要中的简短描述 |
article_extract_short |
str? | REST 摘要中的引言段落 |
article_thumbnail_url |
str? | 文章首图 URL |
article_lat, article_lon |
f64? | 文章标记的地理坐标 |
article_pageid |
i64? | Wikipedia 内部页面 ID |
article_body_text |
str | 文章正文全文(未截断) |
geometry_wkt |
str? | OSM 多边形几何的 WKT 表示(MULTIPOLYGON / POLYGON) |
从源数据补充的字段(通过 (osm_id, country) 左连接):
| 字段 | 类型 | 描述 |
|---|---|---|
tags |
list[str] | 多边形的原始 OSM key=value 标签 |
continent |
str | 多边形所在大洲(当前均为 Europe) |
area_km2 |
f64 | 多边形面积(平方公里) |
pbf_date |
str | 提取多边形的 OSM PBF 数据日期 |
已包含的国家及匹配多边形数量
| 国家 | 匹配多边形数 |
|---|---|
| czech-republic | 6,359 |
| slovakia | 3,473 |
| ukraine | 2,649 |
| france | 2,757 |
| germany | 1,945 |
| turkey | 870 |
| moldova | 722 |
| romania | 522 |
| switzerland | 470 |
| greece | 463 |
| denmark | 405 |
| belarus | 403 |
| finland | 392 |
| estonia | 315 |
| austria | 284 |
| netherlands | 283 |
| belgium | 223 |
| portugal | 205 |
| croatia | 188 |
| serbia | 187 |
| iceland | 166 |
| bulgaria | 162 |
| slovenia | 150 |
| hungary | 141 |
| spain | 126 |
| lithuania | 117 |
| luxembourg | 102 |
| bosnia-herzegovina | 76 |
| cyprus | 71 |
| latvia | 70 |
| albania | 56 |
| united-kingdom | 44 |
| montenegro | 39 |
| azores | 35 |
| isle-of-man | 29 |
| faroe-islands | 22 |
| guernsey-jersey | 21 |
| malta | 20 |
| kosovo | 20 |
| andorra | 7 |
| liechtenstein | 3 |
| poland | 2 |
| monaco | 1 |
| 合计 | 24,595 |
注意: 意大利(Italy)未包含在内(源数据中有 26 个多边形,但均无英文站点链接)。
数据来源
多边形数据源自数据集 NoeFlandre/osm-polygon-selection(https://huggingface.co/datasets/NoeFlandre/osm-polygon-selection),每个多边形携带 geometry_wkt 字段(MULTIPOLYGON WKT 表示)。
已知限制
- 仅支持英文。 未解析非英文的 Wikipedia 站点链接。
- 仅使用 Wikidata 金路径。 没有
wikidata=*标签的多边形(约占源数据的 97%)未被覆盖。名称匹配(阶段 2b)和地理搜索(阶段 2c)尚未实现。 - 瑞典尚未处理。 瑞典有 30,980 个 Wikidata 命中结果,计算量较大,需要数小时运行。
- 每行对应一个
(osm_id, country)组合。 部分源数据中同一逻辑多边形存在多个记录(例如法国有 5,155 个重复项),已通过去重脚本scripts/dedupe_per_country.py压缩为首次出现记录。
搜集汇总
数据集介绍
构建方式
该数据集通过将OpenStreetMap(OSM)多边形与英文维基百科文章进行对齐而构建,对齐的桥梁是Wikidata的QID标识符。构建过程以国家为单位逐步推进,每个国家的OSM多边形首先从源数据集`NoeFlandre/osm-polygon-selection`中采样,随后通过`match_wikidata.py`脚本依据多边形标签中的`wikidata=*`字段解析出对应的Wikidata实体,进而匹配到拥有英文站内链接的维基百科文章。匹配成功后,仅保留那些成功解析到真实英文文章的多边形,并为其抓取文章标题、REST摘要字段以及完整的纯文本正文。所有处理均在本地完成,并最终生成每个国家的独立文件以及全量合并的联合Parquet文件。
特点
该数据集的核心特色在于其跨模态的地理与文本对齐能力,将空间几何信息与丰富的自然语言语义紧密耦合。每个数据行都包含了OSM多边形的WKT几何表示、地理中心坐标、面积等空间属性,同时携带对应的维基百科文章标题、全文正文以及摘要描述等文本信息。数据覆盖43个欧洲国家,共包含约24,595个有效匹配样本,平均每篇文章含357个单词,总计超过875万字。此外,数据集还提供了交互式地图(HTML格式)以可视化多边形的地理分布,并附带了OSM原始标签、所属大洲和PBF提取日期等辅助字段,便于下游任务进行多维度分析。
使用方法
该数据集以Parquet和JSONL两种格式发布,分为每个国家的单独文件与全量联合文件`all_wikidata.parquet`。用户可通过HuggingFace Datasets库直接加载,例如使用`load_dataset('NoeFlandre/osm-polygon-to-wikipedia-articles', split='all')`获取全部数据,或通过指定子集名称加载特定国家数据。数据包含24列,涵盖了`osm_id`、`geometry_wkt`、`article_title`、`article_body_text`等关键字段,适用于训练地理空间基础模型、多模态检索、遥感图像属性分类以及图文对齐等任务。用户也可以利用提供的交互式HTML地图进行直观的样本探索与验证。
背景与挑战
背景概述
随着地理空间数据分析与自然语言处理领域的深度融合,将非结构化地理实体与百科全书式文本知识进行语义对齐,已成为构建地理空间基础模型的关键技术路径。由研究者NoeFlandre主导,于近期发布的osm-polygon-to-wikipedia-articles数据集,创新地通过维基数据QID黄金路径,将OpenStreetMap中的多边形矢量实体与对应的英文维基百科文章进行了一对一匹配。该数据集目前覆盖了43个欧洲国家的24,595个多边形,每个多边形不仅保留了其几何形态,还关联了文章标题、摘要及完整正文文本,累计收录逾875万词。这一数据集为遥感影像理解、地理空间实体检索、以及多模态地理基础模型的预训练提供了高质量的跨模态对齐样本,有效弥合了空间几何信息与语义知识之间的鸿沟。
当前挑战
该数据集在构建与应用中面临多重挑战。在领域问题层面,OpenStreetMap中约97%的多边形缺乏直接关联的维基数据标签,导致大量地理实体无法通过黄金路径获得语义信息覆盖,这一问题使得数据集在样本完整性和代表性上存在显著偏差。此外,当前仅支持英文维基百科的匹配,限制了其在多语言地理信息检索与跨文化研究中的应用广度。在构建过程中的挑战上,数据预处理必须处理来源parquet文件中因逻辑重复而导致的同地物多条记录问题,例如法国数据中就存在5,155个重复项,需要通过脚本进行去重。同时,瑞典等大面积国家因匹配命中数量高达30,980条,所需计算时间可达数小时,给规模化扩展带来了算力与时间成本的压力。
常用场景
经典使用场景
在遥感和地理信息科学领域,将非结构化的地理空间数据与语义丰富的百科知识进行对齐是一项极具挑战性的任务。osm-polygon-to-wikipedia-articles数据集应运而生,它通过维基数据QID这一黄金路径,将OpenStreetMap中的多边形要素与对应的英文维基百科文章精准匹配。该数据集最经典的用途在于为地理空间基础模型提供高质量的多模态训练语料,每个样本同时包含多边形的几何信息(WKT格式)和对应的百科文章全文,使得模型能够学习从地理形状到自然语言描述的映射关系,从而赋能地理场景理解、地物分类与检索等下游任务。
实际应用
在实际应用层面,该数据集展现出广泛的价值。在城市规划与智慧城市建设中,它可用于构建自动化的地物语义查询系统,例如通过多边形形状直接检索出该建筑或绿地的维基百科介绍,极大提升城市数据管理的效率。在旅游与导航领域,开发人员可利用该数据集训练模型,使得用户在浏览地图时能即刻获得关于所见地标、公园或行政区域的百科知识卡片,实现沉浸式的地理信息体验。此外,该数据集还支持环境监测与文化遗产保护场景,通过将遥感影像中提取的湖泊、森林等生态要素与维基百科中的详尽背景知识关联,为科研人员和决策者提供更丰富的信息支撑。
衍生相关工作
该数据集的诞生催生了多个方向的衍生研究工作。其上游工作包括Noé Flandre提供的osm-polygon-selection数据集,该数据集精心筛选了不同尺度的OSM多边形样本。基于此,研究者可以进一步拓展至非英文语言版本的百科匹配,例如引入多语种维基链接以构建跨语言的地理知识库。另外,该数据集目前仅覆盖了约3%的含维基数据标签的多边形,推动了后续阶段(如名称匹配与地理搜索)的开发,以覆盖更广泛的无标签地理要素。在模型层面,已有多项工作尝试利用该数据集微调地理空间基础模型,例如将多边形几何编码与BERT风格的语言模型结合,生成更准确的区域描述,未来有望催生出一系列端到端的地理问答与生成系统。
以上内容由遇见数据集搜集并总结生成


