United States Supreme Court Cases
收藏case.law2024-10-24 收录
下载链接:
https://case.law/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了美国最高法院的案例信息,包括案件编号、案件名称、判决日期、法官意见、案件摘要等详细信息。
This dataset contains detailed case information from the Supreme Court of the United States, including case numbers, case names, judgment dates, judicial opinions, case summaries, and other relevant details.
提供机构:
case.law
搜集汇总
数据集介绍
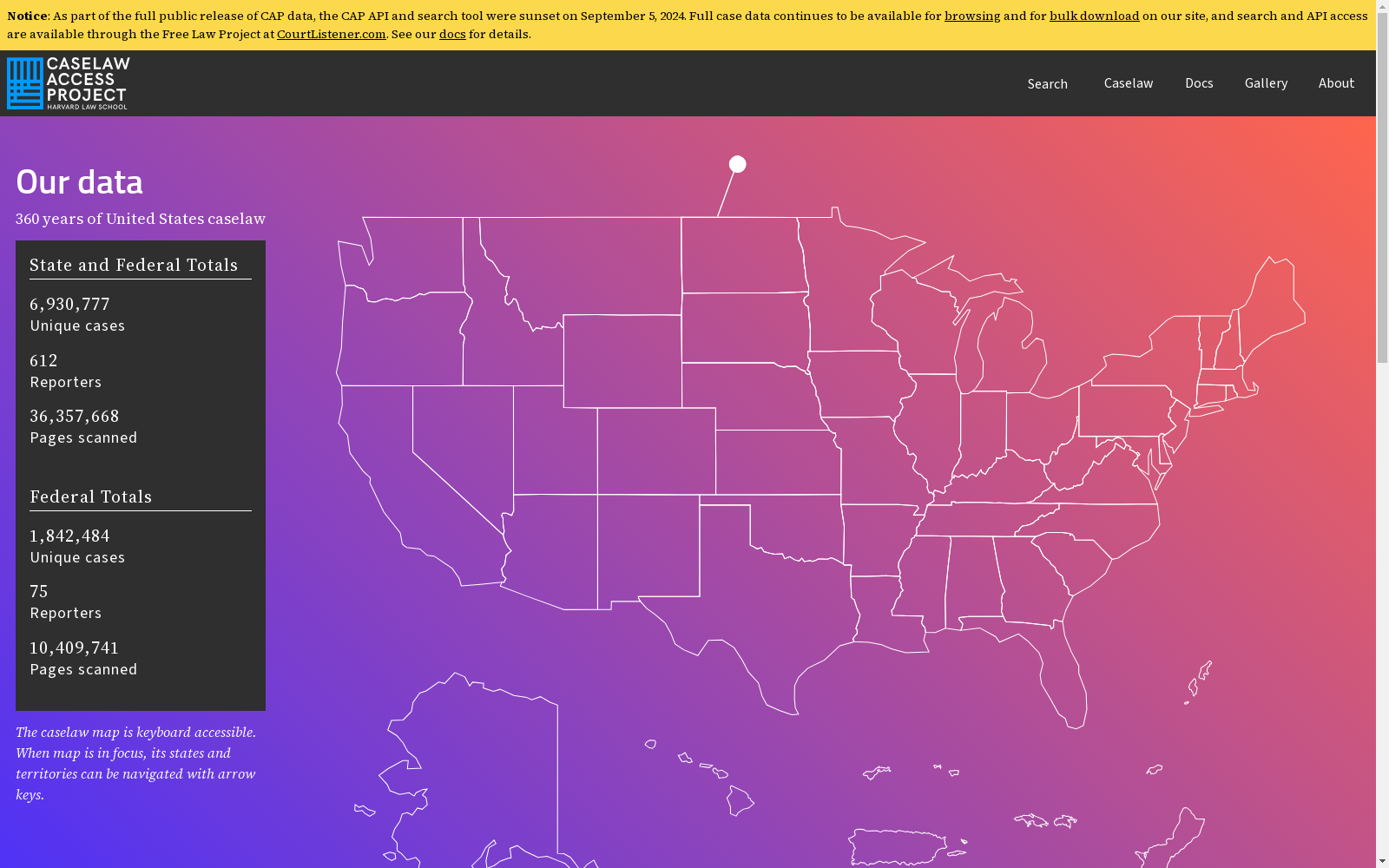
构建方式
United States Supreme Court Cases数据集的构建基于美国最高法院自成立以来的所有公开判决记录。这些记录包括案件的详细信息、判决书文本、法官意见以及相关的法律条文。数据集的构建过程涉及对原始法律文档的数字化处理、文本挖掘和结构化数据的提取,确保了数据的完整性和准确性。通过自动化工具和人工校对相结合的方式,数据集得以涵盖从1790年至今的广泛案例,为法律研究和分析提供了坚实的基础。
使用方法
United States Supreme Court Cases数据集适用于多种研究目的。研究者可以利用其进行历史法律趋势分析,探讨不同历史时期的司法决策模式。此外,该数据集支持文本挖掘和自然语言处理技术,可用于分析法官的判决风格和法律文本的演变。对于法律学者和政策制定者,数据集提供了详尽的案例信息,有助于理解法律实践和制定更为精准的法律政策。数据集的多功能性使其在法律、历史和社会科学研究中具有广泛的应用前景。
背景与挑战
背景概述
美国最高法院案件数据集(United States Supreme Court Cases)汇集了自1791年至今的美国最高法院判决案例,由美国国家档案馆和法律信息研究所等机构共同维护。该数据集的核心研究问题涉及司法判例的分析、法律解释的演变以及司法决策的影响因素。通过这一数据集,学者们能够深入探讨法律与社会、政治、经济之间的复杂关系,从而为法律理论和实践提供宝贵的见解。该数据集不仅在法学领域具有重要影响力,还为跨学科研究如政治学、社会学和历史学提供了丰富的数据资源。
当前挑战
尽管美国最高法院案件数据集提供了丰富的历史和法律信息,但其构建和使用过程中仍面临诸多挑战。首先,数据集的庞大规模和复杂性使得数据清洗和标准化成为一项艰巨任务。其次,法律文本的特殊性,如法律术语的多样性和判例的依赖性,增加了自然语言处理的难度。此外,数据集的更新频率和案例的时效性要求研究人员不断适应新的法律变化和判例解释。最后,跨学科研究的需求使得数据集的整合和分析需要多领域的专业知识,这进一步增加了研究的复杂性。
发展历史
创建时间与更新
United States Supreme Court Cases数据集的创建时间可追溯至19世纪末,具体为1882年,当时美国最高法院开始系统地记录其判决。该数据集的更新时间则持续至今,每年都会新增最高法院的判决案例,确保数据的时效性和完整性。
重要里程碑
该数据集的重要里程碑之一是1971年,美国最高法院与美国国家档案馆合作,开始将所有判决案例数字化,这标志着法律数据管理进入了一个新的时代。另一个重要里程碑是2000年,随着互联网技术的发展,这些案例开始在线公开,极大地促进了法律研究和学术交流。此外,2010年,数据集引入了自然语言处理技术,使得案例的检索和分析更加高效和精确。
当前发展情况
当前,United States Supreme Court Cases数据集已成为法学研究的重要资源,不仅服务于学术界,还广泛应用于法律实践和政策制定。数据集的持续更新和扩展,结合先进的数据分析工具,使得研究人员能够深入挖掘案例中的法律原则和判例法的发展趋势。此外,数据集的开放性和可访问性,促进了公众对法律系统的理解和参与,对法治社会的建设具有深远的意义。
发展历程
- 美国最高法院案例数据集的雏形开始形成,随着美国最高法院的成立,其判决案例逐渐被记录和保存。
- 美国最高法院案例数据集开始系统化整理,相关法律文献和案例汇编工作逐步展开。
- 随着计算机技术的引入,美国最高法院案例数据集开始数字化处理,为后续的电子数据库建设奠定基础。
- 美国最高法院案例数据集正式上线电子数据库,公众和研究者可以通过网络访问和检索历史案例。
- 数据集的覆盖范围扩展至所有历史案例,包括未公开的判决和内部讨论,进一步丰富了研究资源。
- 数据集的更新和维护机制得到优化,确保了案例信息的及时性和准确性,同时增加了多维度的检索功能。
- 数据集与人工智能技术结合,实现了案例的智能分析和预测功能,提升了法律研究和实践的效率。
常用场景
经典使用场景
在法律研究领域,United States Supreme Court Cases数据集被广泛用于分析美国最高法院的判决历史。研究者通过该数据集,可以深入探讨不同历史时期法院的判决趋势、法官的投票模式以及法律原则的演变。例如,学者们利用这一数据集研究了种族歧视案件中法院的态度变化,以及宪法修正案对司法实践的影响。
解决学术问题
该数据集解决了法律学术研究中的多个关键问题。首先,它为研究者提供了详尽的判决文本和相关背景信息,使得对法律原则和司法实践的深入分析成为可能。其次,通过对大量案例的统计分析,研究者能够识别出法律变化的趋势和模式,从而为法律理论的发展提供实证支持。此外,该数据集还促进了跨学科研究,如法律与社会学、政治学的结合,推动了法律社会学和司法政治学的进步。
实际应用
在实际应用中,United States Supreme Court Cases数据集被法律从业者和政策制定者广泛使用。律师和法官利用该数据集进行案例研究,以支持其法律论证和判决。政策制定者则通过分析历史案例,评估现行法律政策的有效性和潜在影响,从而制定更为合理的法律改革方案。此外,教育机构也利用这一数据集进行法律教学,帮助学生理解复杂的法律概念和司法实践。
数据集最近研究
最新研究方向
近年来,美国最高法院案件数据集的研究方向主要集中在法律文本的自动化分析与预测上。随着自然语言处理技术的进步,研究者们致力于开发算法,以自动提取案件中的关键信息,如判决结果、法官意见和法律依据。这些研究不仅有助于法律实务中的案件预测和策略制定,还为法律教育和研究提供了新的工具。此外,数据集的分析还揭示了司法决策中的模式和趋势,为政策制定者和公众提供了关于司法公正和透明度的深入见解。
相关研究论文
- 1The Supreme Court Database: A User's GuideWashington University in St. Louis · 2015年
- 2The Supreme Court and the Judicial Genre: A Computational Analysis of Legal LanguageUniversity of Chicago · 2020年
- 3The Impact of Supreme Court Decisions on Public Opinion: A Longitudinal AnalysisUniversity of Michigan · 2019年
- 4Judicial Behavior and the Supreme Court: A Data-Driven ApproachHarvard University · 2018年
- 5The Evolution of Supreme Court Decision-Making: A Network AnalysisStanford University · 2021年
以上内容由遇见数据集搜集并总结生成


