thoughtworks/ablation_psychometrics_personas
收藏Hugging Face2026-05-01 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/thoughtworks/ablation_psychometrics_personas
下载链接
链接失效反馈官方服务:
资源简介:
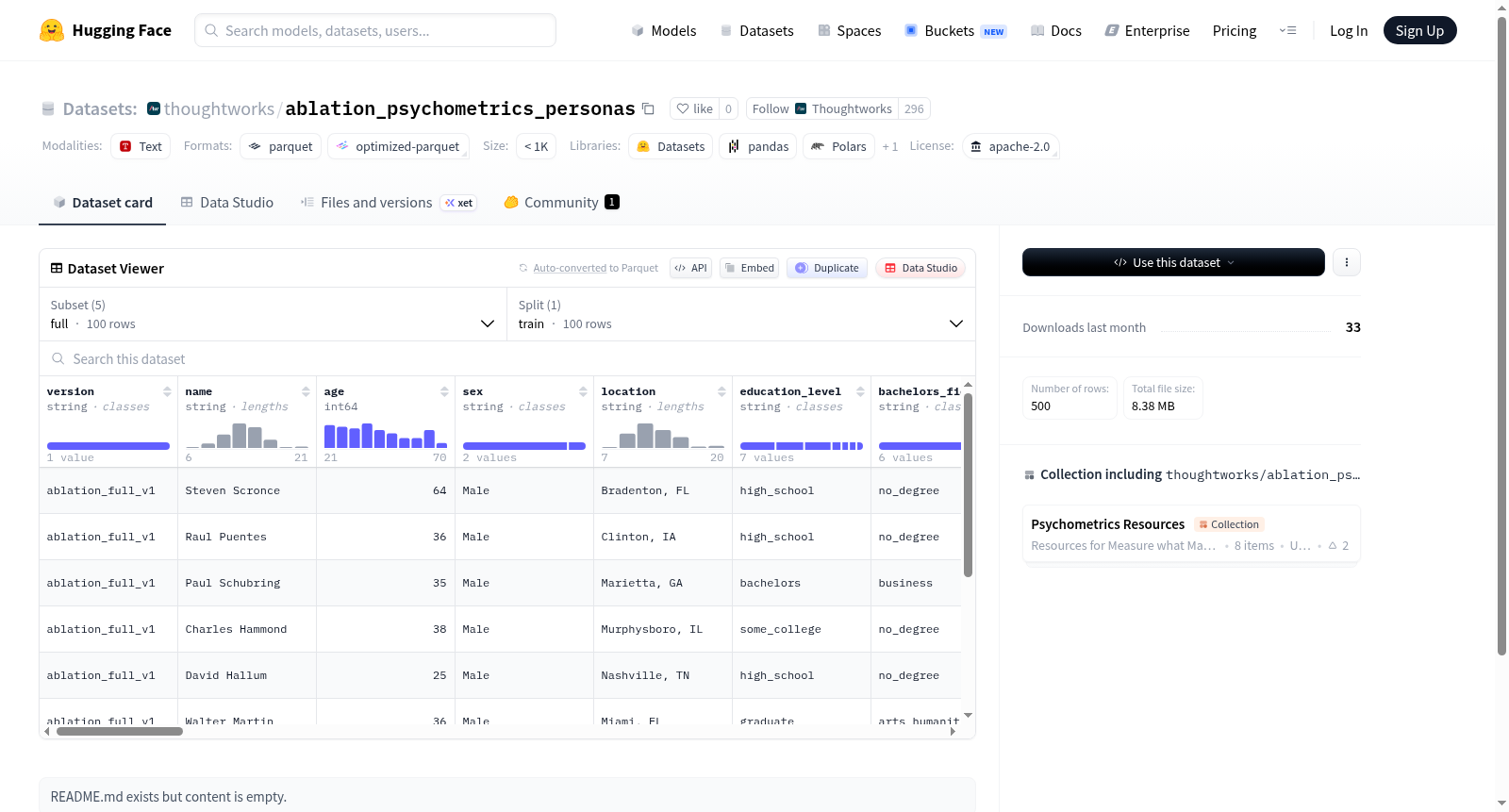
该数据集包含100个示例,用于心理分析或人物建模,涵盖个人信息、心理特征和行为描述。特征包括版本、姓名、年龄、性别、位置、教育水平、学士领域、种族背景、婚姻状况、外貌类别、行为类别、回忆录、回忆录摘要、回忆录叙事、原型、原型描述、外貌、行为、言语、情绪影响、教育职业历史、医疗发展历史、家庭历史、呈现问题、思维内容、洞察判断、认知、情绪行为功能、社会功能、心理档案摘要、UUID、消融配置、人物字符串、人物哈希、连接字段和连接嵌入。数据集提供多个配置:完整版(full)、无原型基础(no_archetype_grounding)、无属性注入(no_attribute_injections)、无人口统计基础(no_demographic_grounding)和无回忆录基础(no_memoir_grounding),每个配置有100个训练示例,用于不同实验条件。数据大小从约1.6MB到2.4MB不等,下载大小从约1.6MB到1.7MB。
This dataset contains 100 examples for psychological analysis or persona modeling, covering personal information, psychological traits, and behavioral descriptions. Features include version, name, age, sex, location, education level, bachelors field, ethnic background, marital status, appearance category, behavior category, memoir, memoir summary, memoir narrative, archetype, archetype description, appearance, behavior, speech, mood affect, educational vocational history, medical developmental history, family history, presenting problems, thought content, insight judgment, cognition, emotional behavioral functioning, social functioning, summary of psychological profile, uuid, ablation config, persona string, persona hash, concat field, and concat embedding. The dataset provides multiple configurations: full, no_archetype_grounding, no_attribute_injections, no_demographic_grounding, and no_memoir_grounding, each with 100 training examples for different experimental conditions. Data sizes range from approximately 1.6MB to 2.4MB, with download sizes from about 1.6MB to 1.7MB.
提供机构:
thoughtworks
搜集汇总
数据集介绍
构建方式
该数据集通过设计多种消融配置来构建,包括完整版(full)及移除原型锚定(no_archetype_grounding)、属性注入(no_attribute_injections)、人口学锚定(no_demographic_grounding)、回忆录锚定(no_memoir_grounding)的五个变体。每个配置均包含100条带有精细心理剖面描述的虚拟人物数据,涵盖年龄、性别、教育背景、民族、婚姻状况等人口学特征,以及外貌、行为、语言、情绪与情感、认知功能等心理学维度。所有数据以统一结构存储,并支持通过HuggingFace Datasets库按配置名称加载。
特点
该数据集的核心特色在于其系统性的消融实验设计,通过控制不同上下文锚定信息的缺失,为探究心理人格描述中各组件对生成模型行为的影响提供了标准化测试平台。每条记录包含结构化的人口学信息、丰富的自由文本回忆录及其叙事摘要、原型人物描述,以及详尽的心理评估字段(如思维内容、洞察力、社会功能等)。此外,数据集提供了persona_string、concat_field及对应的嵌入向量,便于进行基于向量的相似性分析与下游任务适配。
使用方法
用户可通过HuggingFace Datasets库轻松调用该数据集,指定配置名称(如'full'或'no_memoir_grounding')加载对应消融版本的训练分割。数据可高效转换为DataFrame进行统计与可视化探索,也可直接利用concat_embedding字段构建检索或生成式实验。研究人员尤其适用于对比不同消融条件下模型的心理人格推理能力,或基于该数据集微调大语言模型以增强其对人类个性特征的模拟表现。
背景与挑战
背景概述
ablation_psychometrics_personas数据集是专为心理测量学与人格建模研究设计的高质量结构化语料库,由人工智能与心理学交叉领域的研究团队创建,旨在通过消融实验系统探究不同人设特征对大语言模型心理测量结果的影响。该数据集包含100个详细个体档案,涵盖人口统计学、教育背景、心理病理学及人格原型等30余个维度,并提供了完整、无原型、无属性注入、无人统计锚定、无回忆锚定五种消融配置。其诞生填补了精细人格建模在AI伦理与心理评估评估数据上的空白,为人机交互、计算精神病学及负责任AI发展提供了关键基准,推动了可解释人格生成与模型心理一致性验证领域的进展。
当前挑战
该领域核心挑战在于如何构建真实、多样且无偏的心理测量锚定样本。一方面,现有通用人格数据集缺乏临床心理维度(如思维内容、判断力)与消融实验支持,难以分离不同特征对模型行为的贡献;另一方面,构建过程中人工撰写个体档案面临一致性代价高昂与原型偏移风险,100条样本需在30余维特征间保持心理现实性与逻辑连贯性。此外,消融配置(如移除人口学锚点)可能引发生成人格的分布漂移或语义断裂,而跨文化背景与性别、年龄等特征的组合膨胀更增加了表征复杂性,使模型在心理测量情境下的鲁棒性评估面临挑战。
常用场景
经典使用场景
在计算社会科学与心理学交叉研究中,ablation_psychometrics_personas数据集被广泛用于生成具有精细化心理剖面和人口统计学特征的人工智能角色。研究者常利用该数据集构建具备完整‘大五人格’、认知模式、情感状态及社会功能描述的数字分身,从而在受控实验中模拟真实人类在心理评估、行为预测等场景下的反应。通过配置不同的消融变体(如去除原型约束或记忆锚定),学者能够系统探究各人格组件对模型行为一致性与现实感的贡献,为心理测量学与生成式AI的融合提供标准化基准。
衍生相关工作
基于该数据集的消融特性,衍生了若干里程碑式研究:部分工作聚焦于‘人格锚定消融分析’,通过剥离‘原型描述’或‘人生回忆’字段,揭示大型语言模型在角色扮演中产生刻板印象的根源;另一系列研究利用其多维度嵌入(concat_embedding)开发了心理状态可控的文本生成框架,实现情绪与认知模式的动态调节。此外,该数据集启发了‘反事实人格推演’任务,推动模型在保持合理性的前提下探索极端心理状况下的行为边界,为人机安全交互奠定方法论基础。
数据集最近研究
最新研究方向
在人工智能与心理学交叉领域,ablation_psychometrics_personas数据集的出现标志着人格建模研究迈入了精细化消融分析的新阶段。该数据集通过构建包含人口统计学、自传体记忆、原型特征及临床心理学评估的多维人物画像,并设计全量版与五种消融配置(如去除原型锚定、属性注入、人口统计锚定或记忆锚定),为探究大语言模型人格一致性的核心影响因素提供了系统性的实验框架。伴随学术界对AI角色扮演中人格深度与可信度的高度关注,该数据集精准呼应了当前热点——即通过消融实验识别出对人格表征贡献最大的关键语义模块,从而推动模型从表面模仿走向心理真实的模拟。其研究意义在于,这一方法论能够揭示不同心理维度对合成人格的内在权重,为开发更具共情力和稳定性的AI互动体奠定可解释的基石,同时为人机交互中的个性化叙事生成与心理评估工具的设计开辟了严谨的实证路径。
以上内容由遇见数据集搜集并总结生成


