sdoh-nli
收藏Hugging Face2025-01-01 更新2025-01-02 收录
下载链接:
https://huggingface.co/datasets/presencesw/sdoh-nli
下载链接
链接失效反馈官方服务:
资源简介:
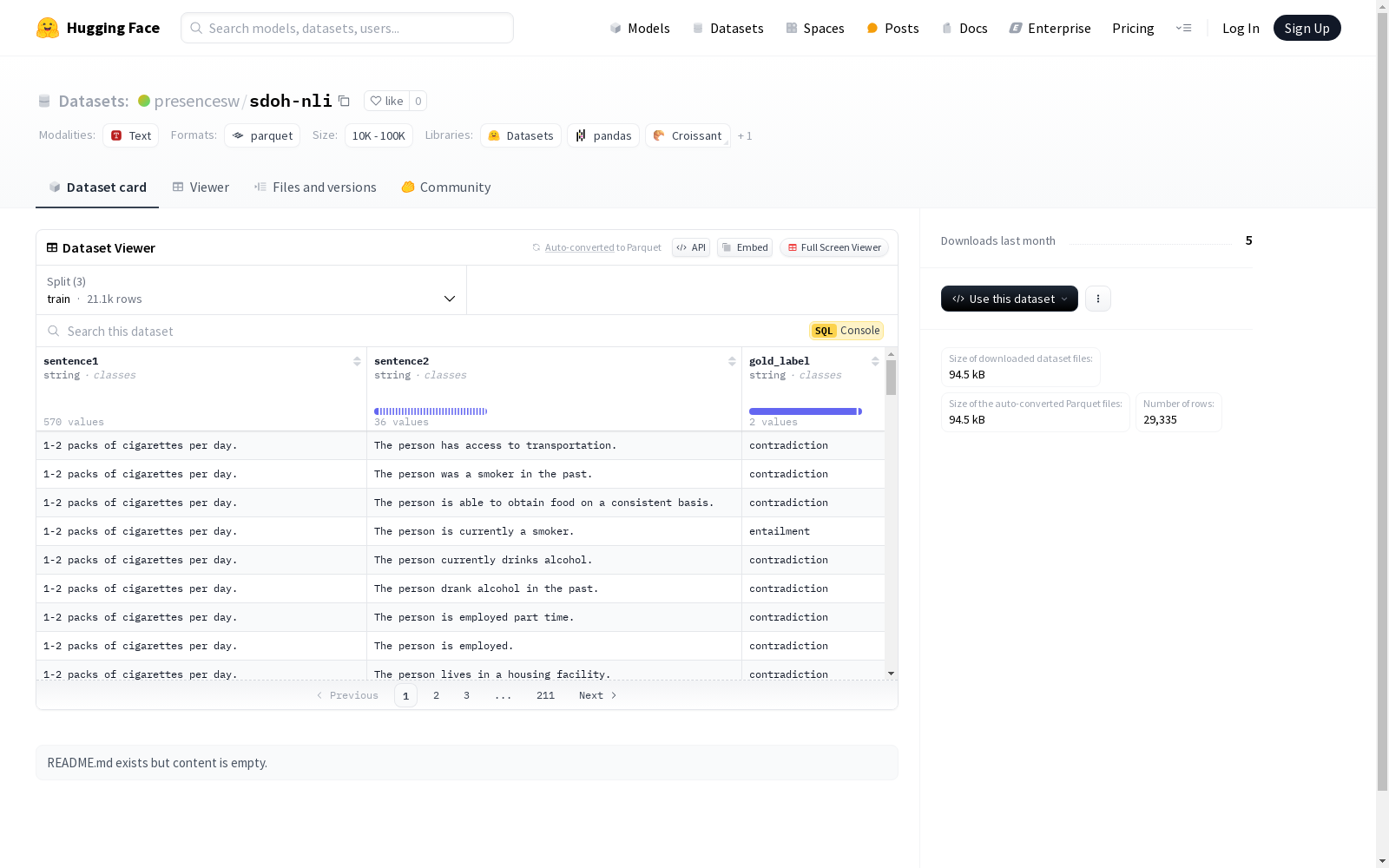
该数据集包含两个句子(sentence1和sentence2)以及一个标签(gold_label),通常用于文本对任务,如自然语言推理或句子相似度判断。数据集分为训练集、验证集和测试集,分别包含21090、4033和4212个样本。
创建时间:
2025-01-01
搜集汇总
数据集介绍
构建方式
sdoh-nli数据集的构建基于自然语言推理(NLI)任务,旨在通过句子对的形式捕捉社会决定因素(SDoH)的语义关系。该数据集从广泛的文本资源中提取句子对,并通过人工标注或自动化工具为每对句子分配一个黄金标签,以指示它们之间的逻辑关系。数据集的划分遵循标准的机器学习实践,分为训练集、验证集和测试集,确保模型能够在不同阶段进行有效的训练和评估。
特点
sdoh-nli数据集的特点在于其专注于社会决定因素领域,提供了丰富的句子对样本,涵盖了多样化的语义关系。每个样本包含两个句子(sentence1和sentence2)以及一个黄金标签(gold_label),标签用于指示句子之间的逻辑关系,如蕴含、矛盾或中立。数据集的规模适中,包含超过25,000个样本,分为训练、验证和测试三部分,适合用于模型开发和性能评估。
使用方法
使用sdoh-nli数据集时,研究人员可以将其应用于自然语言推理任务,特别是与社会决定因素相关的语义分析。数据集的标准划分允许用户直接在训练集上训练模型,在验证集上进行超参数调优,并在测试集上评估模型性能。通过加载数据集中的句子对和标签,用户可以构建和优化NLI模型,探索社会决定因素在文本中的表达和推理机制。
背景与挑战
背景概述
sdoh-nli数据集专注于社会决定因素(Social Determinants of Health, SDoH)与自然语言推理(Natural Language Inference, NLI)的交叉领域。该数据集由相关领域的研究人员或机构创建,旨在通过句子对的形式,探索社会决定因素对健康影响的推理关系。其核心研究问题在于如何通过自然语言处理技术,理解和推理社会决定因素与健康结果之间的复杂关系。该数据集的发布为健康信息学、公共卫生以及自然语言处理领域的研究提供了重要的数据支持,推动了跨学科研究的深入发展。
当前挑战
sdoh-nli数据集在解决社会决定因素与健康推理关系的过程中面临多重挑战。首先,社会决定因素涉及广泛且复杂的领域,如经济、教育、环境等,如何准确捕捉这些因素与健康结果之间的关联性是一个难题。其次,自然语言推理任务本身具有较高的复杂性,要求模型能够理解句子的语义并做出逻辑推理,这对数据标注和模型训练提出了更高的要求。此外,数据集的构建过程中,如何确保句子对的多样性和代表性,以及如何平衡不同社会决定因素的覆盖范围,也是构建者需要克服的技术挑战。
常用场景
经典使用场景
在自然语言处理领域,sdoh-nli数据集被广泛应用于文本推理任务的研究。通过提供成对的句子及其对应的标签,该数据集为研究者提供了一个标准化的平台,用于训练和评估模型在理解句子间逻辑关系方面的能力。特别是在社会决定因素健康(SDOH)相关文本的分析中,该数据集帮助模型更好地捕捉和理解复杂的语义关系。
解决学术问题
sdoh-nli数据集有效解决了自然语言推理任务中的语义理解难题。通过提供大量标注数据,研究者能够开发出更精确的模型,用于判断句子间的逻辑关系,如蕴含、矛盾或中立。这不仅推动了文本推理技术的发展,还为SDOH相关研究提供了新的视角,帮助研究者更深入地理解健康与社会因素之间的复杂关联。
衍生相关工作
基于sdoh-nli数据集,研究者们开发了多种先进的自然语言推理模型,如BERT和RoBERTa的变体。这些模型在多个公开的文本推理任务中取得了显著的成绩,进一步推动了自然语言处理技术的发展。此外,该数据集还激发了跨学科研究,如健康信息学和社会科学,促进了不同领域之间的知识融合与创新。
以上内容由遇见数据集搜集并总结生成


