fairnlp/weat
收藏数据集卡片:词嵌入关联测试(WEAT)
数据集详情
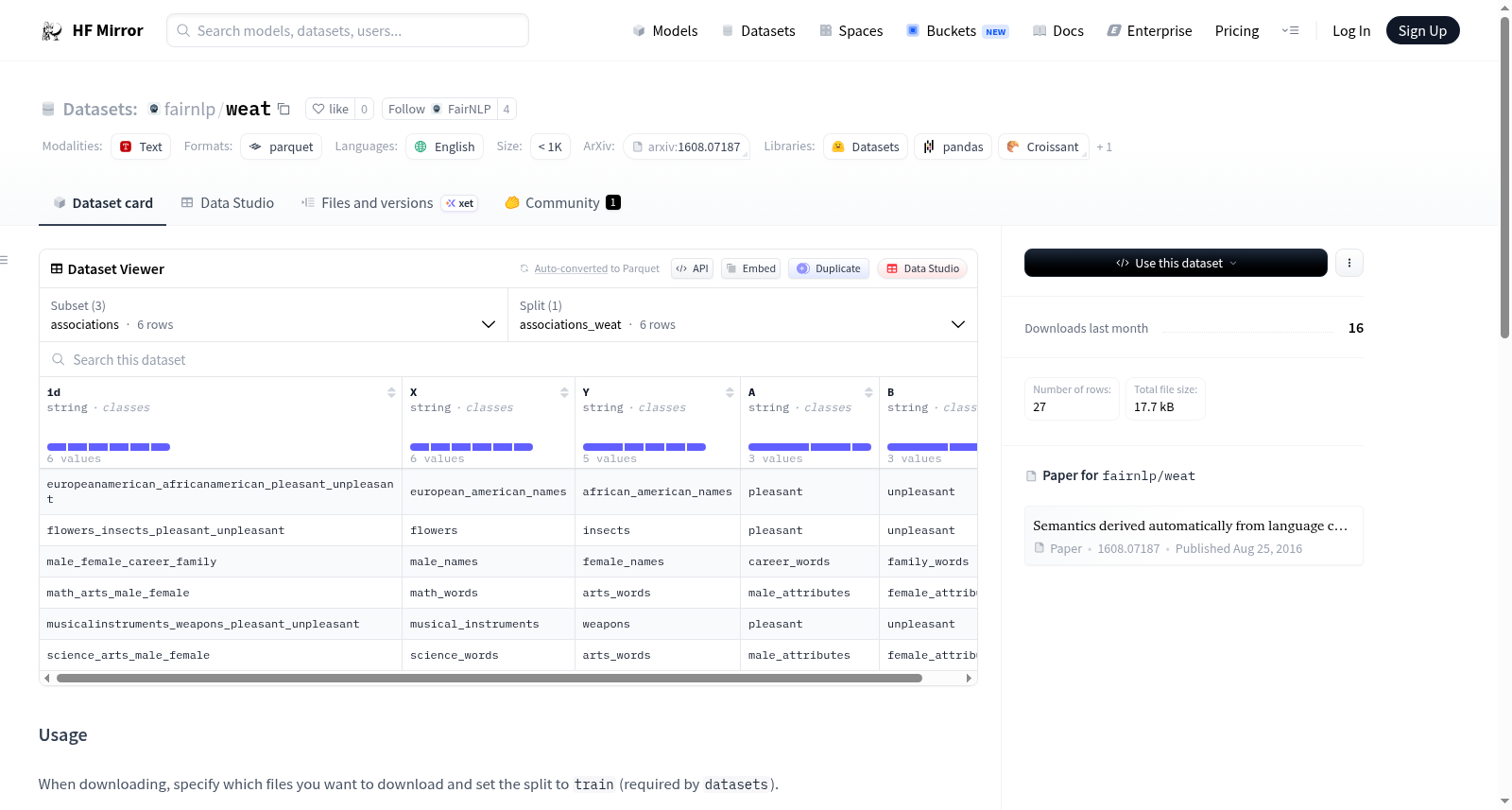
该数据集包含原始词嵌入关联测试(WEAT)的源词,如Caliskan等人在2016年所述。数据集包含用于计算不同嵌入关联的多个WEAT分数的词列表和属性列表。有关方法论的详细信息,请参阅原始论文。该数据集作为FairNLP fairscore库中WEAT实现的一部分贡献给Hugging Face。
数据集来源
- 论文 [可选]: lcs.bath.ac.uk/~jjb/ftp/CaliskanSemantics-Arxiv.pdf
BibTeX:
bibtex @article{DBLP:journals/corr/IslamBN16, author = {Aylin Caliskan Islam and Joanna J. Bryson and Arvind Narayanan}, title = {Semantics derived automatically from language corpora necessarily contain human biases}, journal = {CoRR}, volume = {abs/1608.07187}, year = {2016}, url = {http://arxiv.org/abs/1608.07187}, eprinttype = {arXiv}, eprint = {1608.07187}, timestamp = {Sat, 23 Jan 2021 01:20:12 +0100}, biburl = {https://dblp.org/rec/journals/corr/IslamBN16.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }