plantvillage-full
收藏Hugging Face2026-05-19 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/geraldmc/plantvillage-full
下载链接
链接失效反馈官方服务:
资源简介:
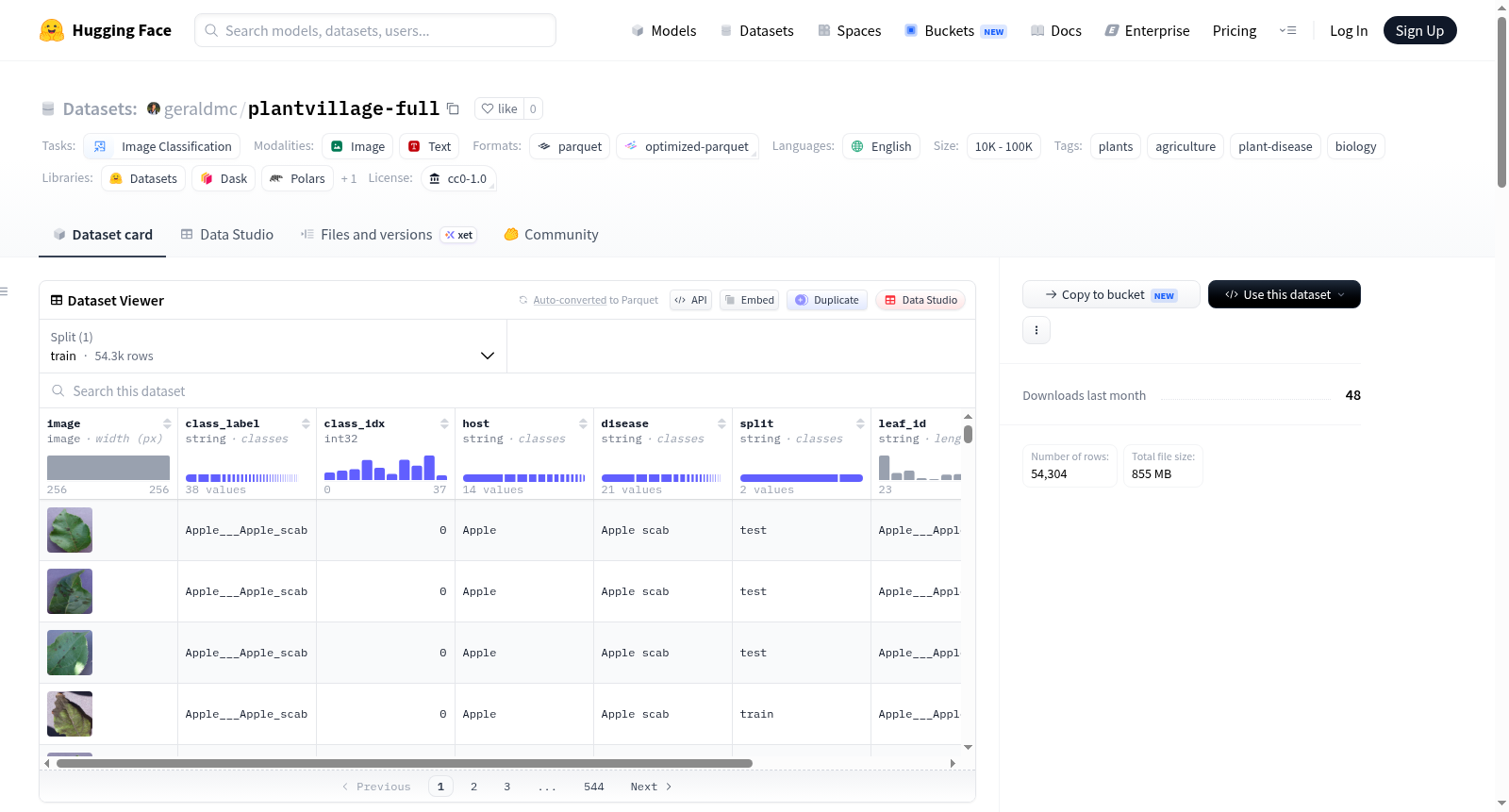
PlantVillage (full) 是一个经过整理并重新发布的植物病害图像数据集,源自2016年发布的原始PlantVillage数据集。该数据集包含54,304张在受控光照和纯色背景下拍摄的植物叶片图像,涵盖38个不同类别,每个类别对应一种特定的宿主植物物种及其所患的病害或健康状态。数据集提供了结构化元数据层,包括对宿主植物和病害名称的解析、基于物理叶片来源的分组(通过`leaf_id`标识),以及一个确定性的训练集与测试集划分(约80/20比例,实际为43,356张训练图像和10,948张测试图像),确保同一片叶子的所有图像仅出现在训练集或测试集之一,避免了数据泄露。数据以Parquet分片格式打包,便于快速流式访问。每个样本包含图像(统一为256x256像素的RGB JPEG格式)、类别标签(如“Apple___Apple_scab”)、类别索引(0-37)、解析出的宿主植物名称、病害名称、划分标记(“train”或“test”)、叶片ID以及一个指示叶片ID是否源自上游分组元数据的布尔标志。该数据集主要用于图像分类任务,特别是在农业和植物病理学领域的植物疾病自动检测研究,许可证为CC0 1.0(公共领域奉献)。
PlantVillage (full) is a curated and repackaged plant disease image dataset derived from the original PlantVillage dataset released by Mohanty, Hughes, and Salathé in 2016. It contains 54,304 images of plant leaves captured under controlled lighting and plain backgrounds, covering 38 distinct categories, each corresponding to a specific host plant species and its disease (or healthy status). The dataset contributes a structured metadata layer, including parsed host plant and disease names, grouping based on physical leaf source (`leaf_id`), and a deterministic train/test split (approximately 80/20 ratio, specifically 43,356 training images and 10,948 test images) that ensures all images of the same leaf appear only in either the training or test set, preventing data leakage. The dataset is packaged in Parquet shards for fast streaming access. Each data sample includes an image (uniformly 256x256 pixel RGB JPEG), a class label (e.g., Apple___Apple_scab), a class index (0-37), parsed host plant name, disease name, split marker (train or test), leaf ID, and a boolean flag indicating whether the leaf ID originates from upstream grouping metadata. The dataset is primarily used for image classification tasks, especially in automated plant disease detection research in agriculture and plant pathology, with a CC0 1.0 license (public domain dedication).
创建时间:
2026-05-19
搜集汇总
数据集介绍
构建方式
植物病害图像数据集PlantVillage-full源自Mohanty等人于2016年发布的开源资源,经由系统性重构与元数据增强而形成。构建流程始于对上游仓库指定提交版本的浅克隆,继而遍历raw/color/目录以枚举图像并解析类别标签。针对其中30个具备filtered_leafmaps/ CSV文件的类别,通过关联叶片来源元数据生成全局唯一的leaf_id标识符,并设置leaf_grouped为True;其余8个类别则赋予各图像独立的合成leaf_id,leaf_grouped标记为False。在此基础上,采用固定随机种子对leaf_id进行洗牌,实施基于叶片的80/20分层划分,确保同一物理叶片的所有图像被完整分配至训练集或测试集,最终将数据打包为Parquet分片以实现高效流式访问。
特点
该数据集包含54,304幅在受控光照条件下以纯色背景拍摄的植物叶片图像,覆盖38个类别,每个类别由宿主植物物种与病害状态(含健康)的唯一组合构成。其核心贡献在于精密的元数据层,包括宿主与病害名称的解析字段、叶片来源分组信息,以及确定性划分的训练/测试集标识。特别地,基于叶片的划分策略保证了模型评估时从未见过被测试叶片的任何图像,显著提升了泛化能力评估的严谨性。数据集统一采用256×256像素的JPEG RGB格式,并提供层级化的类标签(字符串形式与整数索引),便于多维度分析与应用。
使用方法
数据集可通过HuggingFace Datasets库便捷加载,指定版本号与拆分名称即可获取,返回的每条记录包含PIL图像对象及class_label、host、disease等结构化元数据字段。用户可直接使用其内置的'train' HF拆分,但实际训练与测试分离信息位于split元数据列中。对于PyTorch生态的开发者,可通过配套irilab2026库的封装函数获得元数据DataFrame与Dataset包装器。数据以Parquet分片格式存储,支持流式读取,适合大规模训练流程。需注意,Tomato___Target_Spot类别虽存在叶片映射文件,但实际查找均失败,数据分组有效性需额外验证。
背景与挑战
背景概述
PlantVillage数据集由Sharada P. Mohanty、David P. Hughes和Marcel Salathé于2016年创建,旨在推动基于深度学习的植物病害图像识别研究。该数据集包含54,304张在受控光照和纯色背景下拍摄的植物叶片图像,覆盖38个类别,每类由宿主植物物种与病害(或健康)组合而成。作为农业人工智能领域的重要基准,PlantVillage在植物病害自动诊断、细粒度图像分类等任务中发挥了关键作用,为智能农业生产提供了数据基础。本次重构版本由Gerald McCollam为iResearch Institute 2026虚拟实验室项目精心策划,新增了结构化元数据、叶片来源分组和确定性训练/测试划分,进一步提升了数据集的可用性和评估可靠性。
当前挑战
数据集面临的核心挑战包括领域问题与构建难题。领域方面,PlantVillage解决的是植物病害自动检测这一农业视觉识别问题,但受控环境下的图像与真实田间场景存在较大差异,模型在野外复杂背景、光照多变、病害多样条件下泛化能力不足。构建过程中,挑战源自数据整合与质量控制:上游仓库中`Tomato___Target_Spot`类别的叶片地图文件与当前图像版本不匹配,导致1,404次文件名查找全部失败,实际有效分组的类别数从预期的30类降至29类。此外,原始论文报告的图像数量为54,303张,而当前仓库包含54,304张,这一差异的来源尚未追溯,可能影响依赖精确计数的分析任务。
常用场景
经典使用场景
PlantVillage-full数据集在植物病理学与计算机视觉交叉领域扮演着基准测试的重要角色,其最经典的使用场景是作为植物叶片病害图像分类任务的标准化评测平台。该数据集囊括了54,304张在受控光照和单色背景下拍摄的植物叶片图像,横跨14种宿主植物与38类健康或病害类别,为深度卷积神经网络从宏观叶片表观特征中自动判别病原体类别提供了高质量的训练与验证素材。研究者通常利用该数据集的固定训练/测试划分来评估模型在病害识别任务上的泛化能力,进而推动农业影像智能解析技术的发展。
衍生相关工作
PlantVillage-full数据集的发布催生了一系列具有深远影响的衍生研究工作。在模型架构革新方面,研究者基于该数据集提出了轻量化病害识别网络如PlantXception与LeafNet,以及融合注意力机制的Transformer变体,显著提升了计算效率与识别鲁棒性。在跨域泛化研究领域,该数据集被整合为PlantDoc等大规模评测基准的核心组件,驱动了从受控环境到野外场景的图像域自适应算法的发展。在知识蒸馏与生成式AI方向,学者利用该数据集训练教师网络并抽取病斑语义特征,开发出可迁移至新兴作物病害诊断的少样本学习框架,进一步拓展了植物病理学与深度学习融合的边界。
数据集最近研究
最新研究方向
当前,植物病害智能识别领域正迈向精细化与可复现性并重的研究范式。PlantVillage-full数据集作为经典植物叶片病害图像库的精细化重发布版本,其前沿价值不仅在于保留了38类、超5.4万幅标准化图像的规模,更核心地引入了基于叶片个体来源的分组划分与结构化元数据层。这一设计使得模型评估时能严格避免同一叶片图像同时出现在训练集与测试集中,从而有效消除数据泄露隐患,显著提升实验结论的可靠性。该数据集配合同步发布的轻量级调试子集,降低了研究者复现前沿对比实验的门槛,呼应了农业人工智能领域对数据集构建透明性与公平性日益高涨的诉求。其Parquet分片存储格式亦顺应了大规模数据流式处理的趋势,为植物表型组学与精准农业中的跨模型泛化性研究提供了坚实的数据基础。
以上内容由遇见数据集搜集并总结生成


