TDDBench
收藏arXiv2024-11-05 更新2024-11-08 收录
下载链接:
https://anonymous.4open.science/r/TDDBench-8078
下载链接
链接失效反馈官方服务:
资源简介:
TDDBench是由中国科学技术大学和香港科技大学联合创建的综合性训练数据检测基准,涵盖图像、表格和文本三种数据模态。该数据集包含13个子数据集,总样本数超过40万,旨在评估训练数据检测算法在不同模态和模型架构下的性能。数据集的创建过程包括收集和整理现有数据集,以及引入新的包含隐私和版权敏感信息的数据集。TDDBench主要应用于版权验证、模型遗忘验证和训练数据记忆性调查等领域,旨在解决训练数据泄露和模型透明度不足的问题。
TDDBench is a comprehensive training data detection benchmark jointly developed by the University of Science and Technology of China and The Hong Kong University of Science and Technology, covering three core data modalities: image, tabular, and text. This benchmark includes 13 sub-datasets with over 400,000 samples in total, and its core purpose is to evaluate the performance of training data detection algorithms across diverse modalities and model architectures. The construction of TDDBench involves collecting and curating existing datasets, as well as introducing new datasets that contain privacy and copyright-sensitive information. TDDBench is mainly applied in fields such as copyright verification, model forgetting verification, and training data memorization investigation, aiming to address the issues of training data leakage and insufficient model transparency.
提供机构:
中国科学技术大学
创建时间:
2024-11-05
搜集汇总
数据集介绍
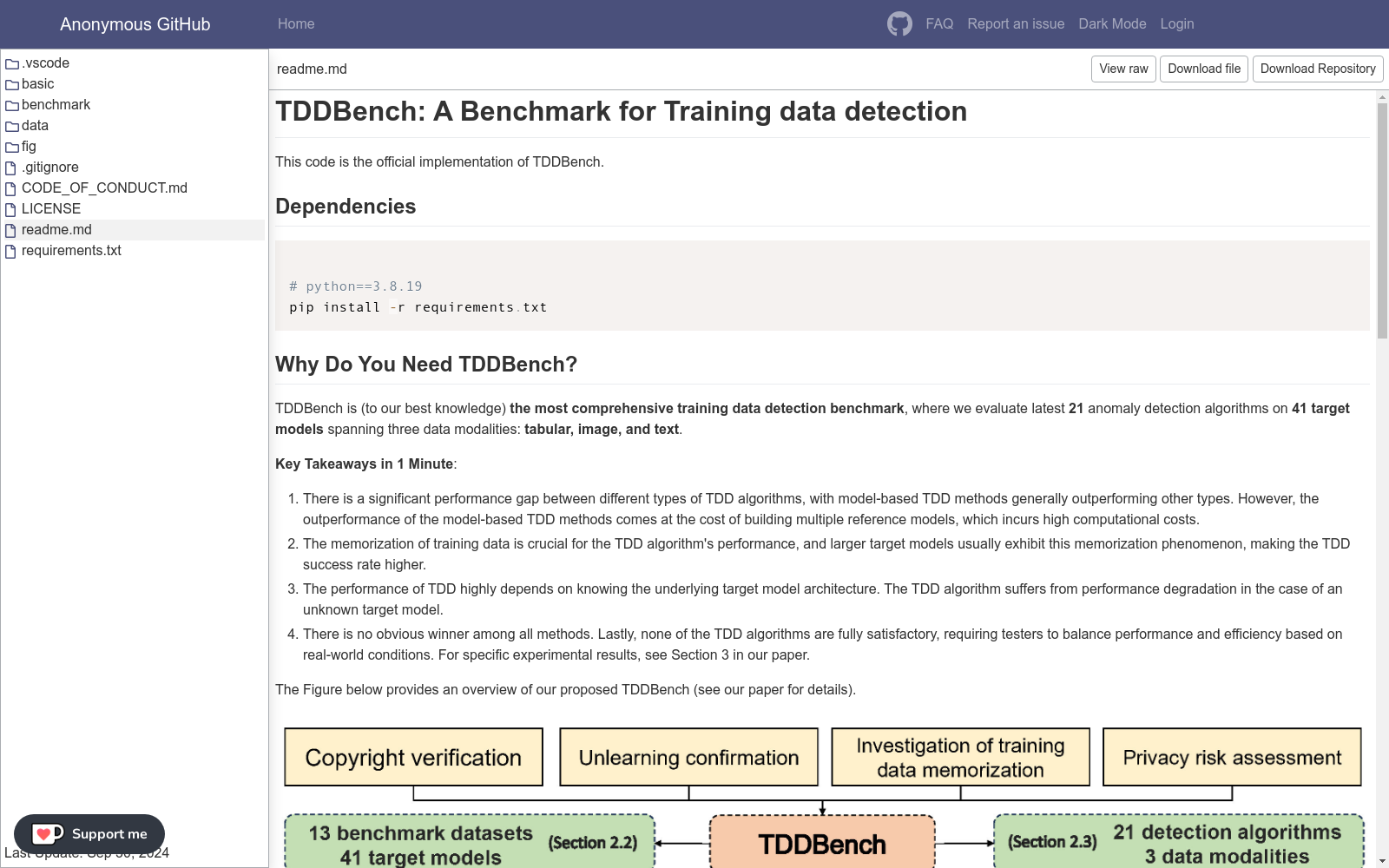
构建方式
TDDBench的构建方式体现了其跨模态和多维度的特点。该数据集包含了13个数据集,涵盖了图像、表格和文本三种数据模态,并针对每种模态设计了多种目标模型。此外,TDDBench还实现了21种最先进的训练数据检测(TDD)算法,这些算法被分为四类:基于度量的、基于学习的、基于模型的和基于查询的。通过这种方式,TDDBench不仅提供了丰富的数据资源,还为研究人员和从业者提供了一个全面的评估平台,以测试和比较不同TDD算法在各种条件下的性能。
特点
TDDBench的主要特点在于其全面性和多样性。首先,它跨越了图像、表格和文本三种数据模态,使得研究者可以在不同类型的数据上评估TDD算法的有效性。其次,TDDBench包含了41种不同的目标模型,这些模型在结构和复杂性上各不相同,从而能够更真实地模拟实际应用场景。此外,该数据集还提供了21种最先进的TDD算法,这些算法在设计理念和实现方式上各有特色,为研究者提供了广泛的比较和分析基础。最后,TDDBench的开放源代码特性确保了其可重复性和可访问性,促进了学术界和工业界的广泛应用。
使用方法
TDDBench的使用方法灵活多样,适用于不同的研究需求和应用场景。首先,研究者可以通过该数据集对现有的TDD算法进行基准测试,评估其在不同数据模态和目标模型下的性能表现。其次,TDDBench提供了详细的实验设置和评估协议,帮助研究者进行系统化的实验设计和结果分析。此外,数据集的开源特性使得研究者可以自由地扩展和修改现有的算法,以适应特定的研究需求。对于从业者而言,TDDBench提供了一个实用的工具,帮助他们在实际应用中选择和优化TDD算法,确保数据隐私和安全。
背景与挑战
背景概述
TDDBench,由中國科學技術大學和香港科技大學的研究團隊開發,是一個專注於訓練數據檢測(Training Data Detection, TDD)的綜合基準。TDD旨在確定特定數據實例是否用於訓練機器學習模型,這在計算機安全文獻中也被稱為成員推斷攻擊(Membership Inference Attack, MIA)。TDDBench包含13個跨圖像、表格和文本三種數據模式的數據集,並對21種不同的TDD方法進行了基準測試。該基準的引入旨在幫助研究人員識別TDD算法的瓶頸和改進領域,同時為實踐者提供在特定應用場景中選擇TDD算法的有效性和效率之間的權衡。
当前挑战
TDDBench面臨的主要挑戰包括:1) 現有基準主要集中在圖像數據的TDD算法,對其他模式如文本和表格數據的探索不足;2) 近年來開發的許多專注於深度學習和大語言模型(LLMs)的TDD方法未被納入這些基準;3) 目標模型對TDD算法的影響未得到充分研究;4) 當前評估主要關注檢測性能,而實際部署中的效率、內存消耗等實際考慮因素往往被忽視。此外,TDDBench的大規模基準測試揭示了不同數據集上TDD算法的普遍不滿意表現,顯示出在非圖像領域需要進一步改進。
常用场景
经典使用场景
TDDBench 数据集的经典使用场景在于评估训练数据检测(TDD)算法的效果。该数据集涵盖了图像、表格和文本三种数据模态,并包含了13个不同类型的数据集。通过在41个不同的目标模型上测试21种不同的TDD算法,TDDBench能够全面评估这些算法在不同数据集和模型架构下的性能,从而帮助研究人员识别TDD算法的瓶颈和改进方向。
衍生相关工作
TDDBench 数据集的推出催生了大量相关研究工作,特别是在训练数据检测算法的改进和优化方面。例如,研究人员基于TDDBench的评估结果,提出了多种新的TDD算法,旨在提高检测精度、减少计算复杂度或增强对不同模态数据的适应性。此外,TDDBench还促进了跨学科的研究合作,推动了数据隐私保护和机器学习安全领域的技术进步。
数据集最近研究
最新研究方向
在训练数据检测(TDD)领域,最新的研究方向集中在开发和评估针对不同数据模态(如图像、表格和文本)的TDD算法。研究者们通过引入TDDBench这一综合基准框架,对21种最先进的TDD算法进行了大规模的性能评估。研究结果揭示了不同类型TDD算法在检测性能、计算效率和内存消耗方面的优劣,特别是在处理大规模语言模型(LLMs)时的表现。此外,研究还探讨了目标模型的大小和训练数据记忆化对TDD算法性能的影响,以及在目标模型架构知识有限的情况下算法的鲁棒性。这些发现为未来TDD算法的设计和优化提供了重要的指导方向,特别是在提高算法对非图像数据模态的适应性和减少对目标模型特定知识的依赖方面。
相关研究论文
- 1TDDBench: A Benchmark for Training data detection中国科学技术大学 · 2024年
以上内容由遇见数据集搜集并总结生成


