DEEPTRACEREWARD
收藏arXiv2025-09-27 更新2025-09-30 收录
下载链接:
https://deeptracereward.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
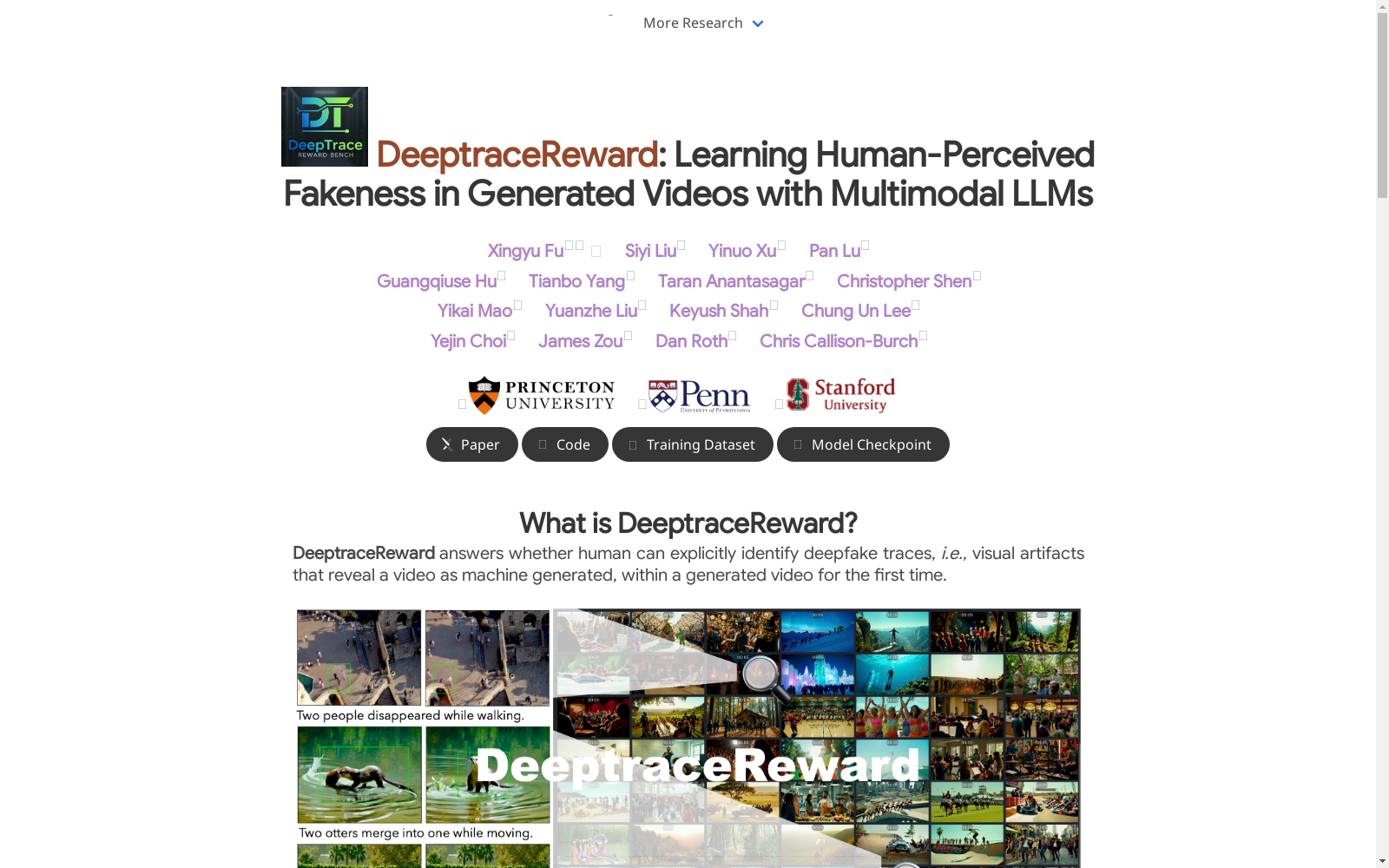
DEEPTRACEREWARD 是首个针对视频生成奖励的细粒度、时空感知基准数据集,用于标注人类感知到的虚假痕迹。数据集包含 3.3K 高质量生成的视频和 4.3K 详细标注,每个标注提供自然语言解释,定位包含感知痕迹的边界框区域,并标记精确的起始和结束时间戳。数据集将标注的深度伪造痕迹分为 9 个主要类别,用于训练多模态语言模型 (LM) 作为奖励模型,以模拟人类判断和定位。
DEEPTRACEREWARD is the first fine-grained, spatio-temporal-aware benchmark dataset for video generation reward, dedicated to annotating human-perceived deepfake traces. The dataset encompasses 3.3K high-quality synthetic videos and 4.3K detailed annotations, where each annotation includes a natural language explanation, locates the bounding box regions housing perceptual traces, and records precise start and end timestamps. The dataset classifies the annotated deepfake traces into 9 primary categories, facilitating the training of multimodal language models (LMs) as reward models to simulate human judgment and localization capabilities.
提供机构:
普林斯顿大学,宾夕法尼亚大学,斯坦福大学
创建时间:
2025-09-27
原始信息汇总
DeeptraceReward 数据集概述
数据集简介
DeeptraceReward 是首个细粒度、时空感知的基准数据集,用于标注人类感知的伪造痕迹以进行视频生成奖励。
核心特性
- 研究目标:探索人类是否能识别AI生成视频中的伪造痕迹,并提供基于证据的判断理由
- 标注内容:提供自然语言解释、包含感知痕迹的边界框区域定位、精确的开始和结束时间戳标记
数据集规模
- 总标注数量:4,300条详细标注
- 覆盖视频数量:3,300个高质量生成视频
- 伪造视频数量:4,334个(来自六个最先进的文本到视频模型)
- 真实视频数量:3,318个(源自LLaVA-Video-178K)
数据特征
- 视频质量:仅包含高质量生成视频
- 运动要求:所有视频必须包含运动内容
- 分辨率多样性:在分辨率上具有显著多样性
- 时长多样性:在时间持续时间上具有显著多样性
分类体系
- 伪造痕迹类别:9个主要的深度伪造痕迹类别
模型性能
- 7B奖励模型:在伪造线索识别、定位和解释方面平均超越GPT-5达34.7%
- 性能梯度:二元分类最容易,自然语言解释次之,空间定位较难,时间标记最难
搜集汇总
数据集介绍
构建方式
在视频生成技术快速发展的背景下,DEEPTRACEREWARD数据集通过两阶段流程精心构建。首先采用GPT-4生成自然场景提示词,经人工筛选后输入七大前沿视频生成模型(包括Kling、Sora、Pika等)合成候选视频。随后通过严格的人工过滤保留3,318个高质量动态视频,确保样本具备运动特征且无明显视觉缺陷。标注环节依托LabelBox平台,由专业标注者逐帧检测时空伪影,最终形成4,334条包含边界框定位、时间戳标记和自然语言解释的细粒度标注。
特点
该数据集最显著的特点是建立了首个细粒度时空感知的深度伪造痕迹标注体系。通过系统化分析将人类感知的伪造痕迹归纳为九大运动相关类别,包括物体形变、突然模糊、异常轨迹等典型模式。数据集涵盖不同分辨率和时长的视频样本,平均视频时长5.7秒,伪造痕迹持续4.0秒。特别值得注意的是62.7%的标注包含详细文字说明,为模型训练提供了丰富的语义监督信号,同时通过多轮交叉验证机制保障标注质量的一致性。
使用方法
该数据集主要服务于视频生成模型的奖励训练与评估任务。研究人员可采用监督微调方法,以VideoLLaMA 3或Qwen 2.5 VL等基础模型为起点,利用数据集提供的三元组监督信号(空间定位、时间标记、语义解释)进行端到端训练。评估阶段设置七项指标全面衡量模型性能,包括真假分类准确率、边界框交并比、时间距离等。实验表明,基于该数据集训练的7B参数奖励模型在深伪痕迹检测任务上显著优于GPT-5等基线模型34.7%,展现出强大的实用价值。
背景与挑战
背景概述
随着视频生成技术的迅猛发展,如Sora、Veo3等模型已能生成高度逼真的视频内容,但现有评估方法多聚焦于预设的视觉指标,忽视了人类对生成视频中伪造痕迹的感知能力。2025年,普林斯顿大学、宾夕法尼亚大学及斯坦福大学的研究团队联合推出了DEEPTRACEREWARD数据集,旨在系统化标注人类在AI生成视频中感知到的时空伪造痕迹。该数据集包含来自七种先进视频生成模型的3.3千个高质量生成视频,并提供了4.3千条细粒度注释,涵盖自然语言解释、空间定位框及时间戳信息。其核心研究问题在于探索人类如何识别并定位视频中的伪造线索,从而推动生成模型向更可信、社会感知的方向发展,填补了视频生成评估中人类感知维度的空白。
当前挑战
DEEPTRACEREWARD面临的挑战主要体现在两方面:其一,在领域问题层面,视频生成模型需克服细粒度伪造痕迹检测的复杂性,例如物体变形、突然模糊、运动轨迹异常等九类常见伪造线索的精准识别与定位,这要求模型不仅具备二进制真伪分类能力,还需实现时空维度的细粒度解析;其二,在构建过程中,数据标注面临主观歧义与语言一致性问题,例如不同注释者对相似伪造类型的判断存在差异,且自然语言解释的风格不一,团队通过共识工作流与后处理标准化缓解了这些挑战,但时空标注的高成本与复杂性仍限制了数据规模的扩展。
常用场景
经典使用场景
在视频生成技术快速发展的背景下,DEEPTRACEREWARD数据集为评估AI生成视频的真实性提供了精细化的基准平台。该数据集通过专家标注的4300余条时空定位注释,系统捕捉人类视觉感知中的深度伪造痕迹,包括物体扭曲、运动轨迹异常等九大类视觉伪影。其典型应用场景聚焦于训练多模态语言模型识别视频中的人工智能生成特征,为视频真实性检测建立标准化评估框架。
衍生相关工作
该数据集的发布催生了系列创新研究,其中最具代表性的是基于VideoLLaMA架构的奖励模型优化工作。研究团队通过监督微调实现了在伪造痕迹检测任务上34.7%的性能提升,同时揭示了多模态任务中存在的难度梯度规律。这些发现推动了视频理解模型在细粒度时空推理方向的发展,为后续视频生成模型的对抗训练提供了重要参照基准。
数据集最近研究
最新研究方向
随着生成式人工智能在视频合成领域的迅猛发展,DEEPTRACEREWARD数据集聚焦于人类视觉感知与AI生成视频之间的检测鸿沟,开辟了细粒度深度伪造痕迹分析的前沿方向。该数据集通过专家标注的时空定位信息与自然语言解释,系统揭示了九类主要伪造痕迹,如物体形变、运动轨迹异常等,为多模态大语言模型的奖励机制训练提供了关键基准。当前研究热点集中于利用该数据集提升模型在伪造线索识别、空间定位与时间标注等方面的能力,显著推动了可信视频生成与人类感知对齐的技术演进,对构建社会责任感强的人工智能系统具有深远意义。
相关研究论文
- 1Learning Human-Perceived Fakeness in AI-Generated Videos via Multimodal LLMs普林斯顿大学,宾夕法尼亚大学,斯坦福大学 · 2025年
以上内容由遇见数据集搜集并总结生成


