mediomatix-raw
收藏Hugging Face2025-08-20 更新2025-08-22 收录
下载链接:
https://huggingface.co/datasets/ZurichNLP/mediomatix-raw
下载链接
链接失效反馈官方服务:
资源简介:
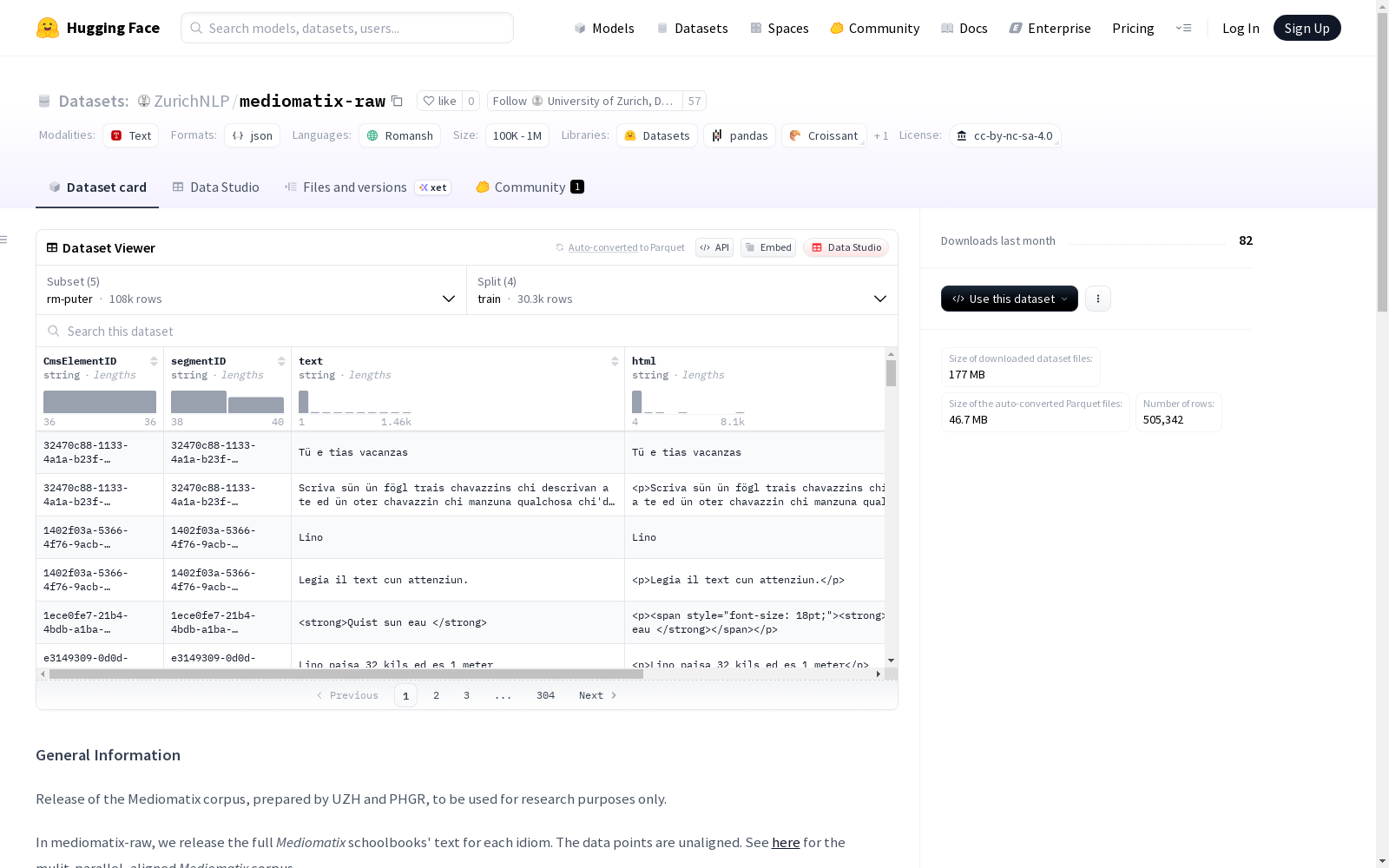
Mediomatix数据集是由UZH和PHGR准备的罗曼什语学校课本文本数据集,包含Sursilvan、Sutsilvan、Surmiran、Puter和Vallader五种方言的子集。每个子集分为训练集、验证集、测试集,以及特定年级范围的no_surmiran子集。数据集适用于研究目的,包含文本段落的标识、文本内容、HTML标记、章节名称和课本编码等信息。
提供机构:
University of Zurich, Department of Computational Linguistics
创建时间:
2025-08-20
搜集汇总
数据集介绍
构建方式
在罗曼什语教育资源数字化进程中,mediomatix-raw数据集系统采集了瑞士格劳宾登州官方教材内容。该数据集依据五种罗曼什语变体(Sursilvan、Sutsilvan、Surmiran、Puter、Vallader)划分语料子集,每个子集按照教材年级层级进行结构化分割:二年级和三年级课文构成训练集,四年级课文作为验证集,五年级课文作为测试集,六至九年级课文则单独形成非Surmiran变体的补充语料。所有文本均保留原始HTML标记与纯文本双版本,并标注了章节来源和教材编码信息。
特点
本数据集的核心价值在于其多维度标注体系与语言多样性。每个数据点包含CMS元素ID、段落ID、纯文本、带HTML标记的文本、章节名称和教材编码六重元数据,其中教材编码采用“年级-卷次-类型”的标准化命名规则,精确标识文本的教学层级属性。数据集覆盖五种罗曼什语变体,除Surmiran变体外均包含延伸年级语料,为研究罗曼什语的语言演变和跨方言比较提供了独特资源。
使用方法
研究者可通过指定罗曼什语变体代码加载对应子集,例如使用rm-sursilv参数加载Sursilvan语料。数据集支持按标准划分获取训练集、验证集和测试集,非Surmiran变体还可额外获取六至九年级的扩展语料。每个数据条目包含原始HTML和纯文本双版本,便于进行文本挖掘与语言分析。通过章节和教材元数据,研究者可进一步实现按教学年级或教材类型的精细化数据筛选。
背景与挑战
背景概述
在罗曼什语语言资源稀缺的背景下,苏黎世大学(UZH)与格劳宾登教育学院(PHGR)联合构建了mediomatix-raw数据集,专注于罗曼什语五大方言变体的文本收集。该数据集源自瑞士格劳宾登州中小学教材,按年级划分训练、验证与测试集,旨在为低资源语言的自然语言处理研究提供重要基础语料。其多方言平行文本结构为语言比较研究、机器翻译模型训练及教育语言学分析提供了前所未有的数据支持,对保护欧洲濒危语言文化遗产具有深远意义。
当前挑战
该数据集核心挑战在于解决低资源语言处理中数据稀缺与方言差异性问题,具体包括五大方言间语法结构和词汇体系的对齐难题。构建过程中面临原始教材HTML标记清理、跨年级文本语义连贯性保持,以及方言变体标注一致性等工程技术挑战。此外,Surmiran方言高年级语料的缺失进一步增加了数据平衡与模型泛化难度,需通过特殊采样策略弥补语料分布不均的缺陷。
常用场景
经典使用场景
在罗曼什语语言资源稀缺的背景下,mediomatix-raw数据集为计算语言学提供了珍贵的原始语料。该数据集最经典的使用场景是作为罗曼什语五大方言的机器翻译模型训练基础,研究者通过其分年级的教材文本构建跨方言的神经机器翻译系统,特别适用于低资源语言对之间的平行语料挖掘和翻译质量评估。
实际应用
在实际应用层面,该数据集支撑了瑞士格劳宾登州的多语种教育系统开发。教育机构利用其分级教材文本开发智能语言学习工具,支持罗曼什语方言的标准化教学。文化保护组织则借助该数据集构建数字语言档案馆,为濒危语言的代际传承提供可持续的数字化解决方案。
衍生相关工作
基于该数据集衍生的经典工作包括苏黎世联邦理工学院开发的RomanshBERT预训练模型,该模型首次实现了罗曼什语多方言的统一表示学习。后续研究团队在此基础上构建了跨方言语义检索系统,并开发了基于课程学习的方言适应框架,为其他濒危语言保护提供了可复用的技术范式。
以上内容由遇见数据集搜集并总结生成


