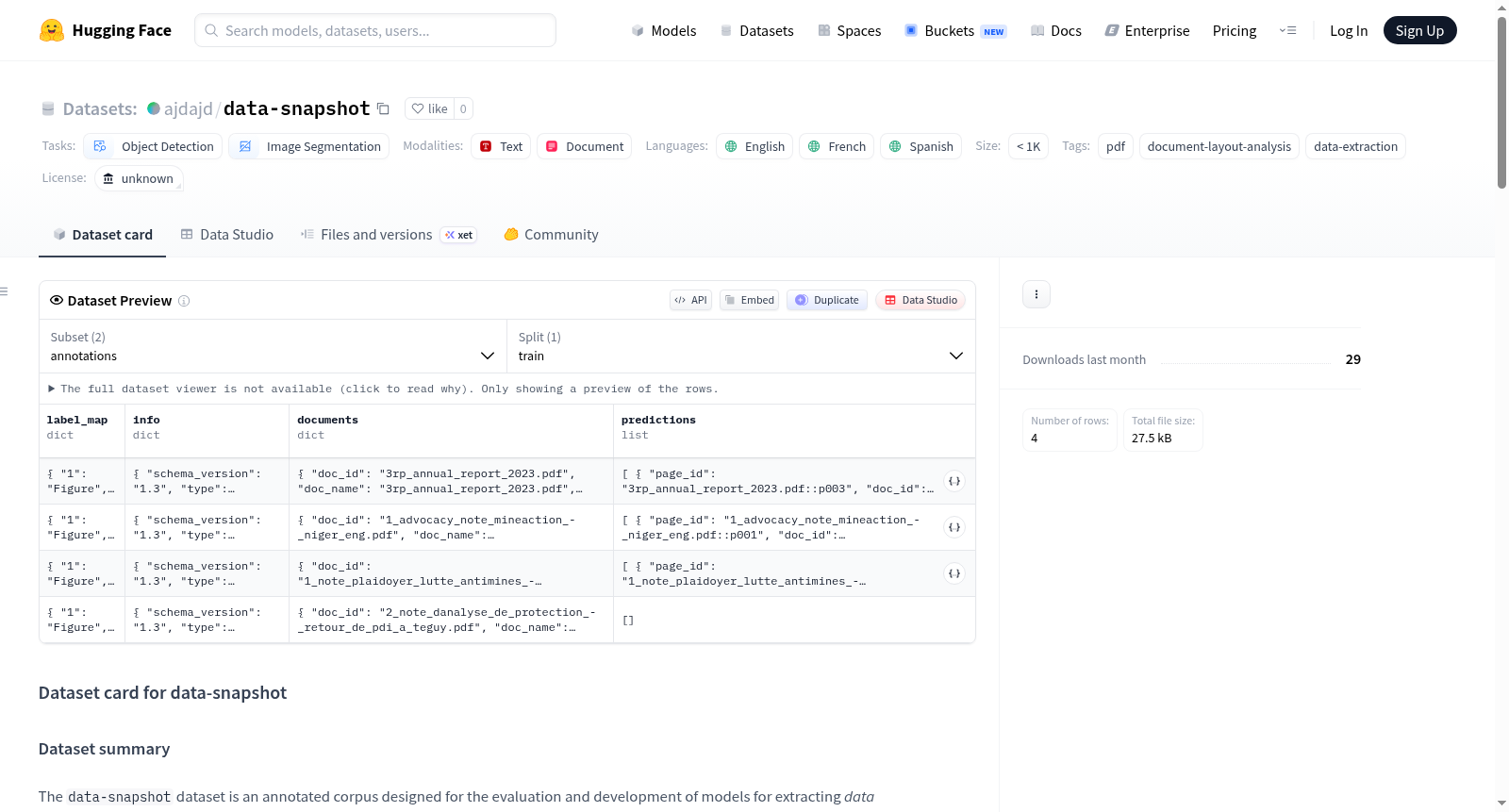
data-snapshot
收藏数据集卡片:data-snapshot
数据集概述
data-snapshot 是一个用于评估和开发从 PDF 文档中提取数据快照(data snapshot)模型的标注语料库。数据快照定义为包含来自统计数据、指标或结构化数据源的定量数据的图表或表格。
任务类型
- 目标检测(object-detection)
- 图像分割(image-segmentation)
标签
- document-layout-analysis
- data-extraction
语言
- 英语(en)
- 法语(fr)
- 西班牙语(es)
数据规模
- n<1K(样本数量小于1000)
数据集结构
仓库目录组织结构如下:
ai4data/data-snapshot/ ├── annotations/<source>/per_document/.json # 每个文档的标注文件 ├── annotations/<source>/combined/.json # 按来源合并的JSON文件 ├── documents/<source>/.pdf # 原始PDF文件 ├── metadata/<source>/.json # 文档级元数据 ├── schemas/data-snapshot-eval-v1.3.schema.json # 标注文件模式 └── README.md
子集
- annotations(标注)
- JSON文件,包含数据快照信息:对象类别(Figure / Table)和边界框位置(归一化的
[x1, y1, x2, y2]格式,左上角原点) - 遵循
data-snapshot-eval-v1.3.schema.json模式 - 提供按文档分开的文件或按来源合并的JSON文件
- JSON文件,包含数据快照信息:对象类别(Figure / Table)和边界框位置(归一化的
- metadata(元数据)
- 按文档提供
数据来源
- UNHCR(联合国难民署)
- PRWP(WIP)(世界银行政策研究工作论文,进行中)
- Refugee(WIP)(难民相关,进行中)
标注模式(Schema v1.3)
标注文件遵循数据快照评估格式 v1.3。简化示例: json { // 标签映射 "label_map": { "1": "Figure", "2": "Table" }, // 文件元信息 "info": { "schema_version": "1.3", "type": "ground_truth", "dataset_id": "data-snapshot_unhcr", "created_at": "2026-04-17T12:00:00Z", "coordinate_system": { "type": "normalized_xyxy", "range": [0.0, 1.0], "origin": "top_left" } }, // 文档列表 "documents": [ { "doc_id": "1_advocacy_note_mineaction_-niger_eng.pdf", "doc_name": "1_advocacy_note_mineaction-niger_eng.pdf", "doc_path": "pdf_input/1_advocacy_note_mineaction-niger_eng.pdf" } ], // 逐页标注 "predictions": [ { "page_id": "1_advocacy_note_mineaction-niger_eng.pdf::p001", "doc_id": "1_advocacy_note_mineaction-niger_eng.pdf", "page_index": 0, "image": { "width_px": 2481, "height_px": 3508, "path": "images/1_advocacy_note_mineaction-_niger_eng.pdf_p001.png" }, "objects": [ { "id": "obj_001", "label": "Figure", "bbox": [0.1, 0.2, 0.8, 0.6] } ] } ] }
数据集创建
标注通过人工使用 Label Studio 工具生成。
许可信息
待定(TBD)
引用信息
待定(TBD)