The global industrial value-added dataset under different global change scenarios (2010, 2030, and 2050)
收藏DataCite Commons2025-04-27 更新2025-05-18 收录
下载链接:
https://www.scidb.cn/detail?dataSetId=969db5cf6cb442dbb580fbeff3136ac0
下载链接
链接失效反馈官方服务:
资源简介:
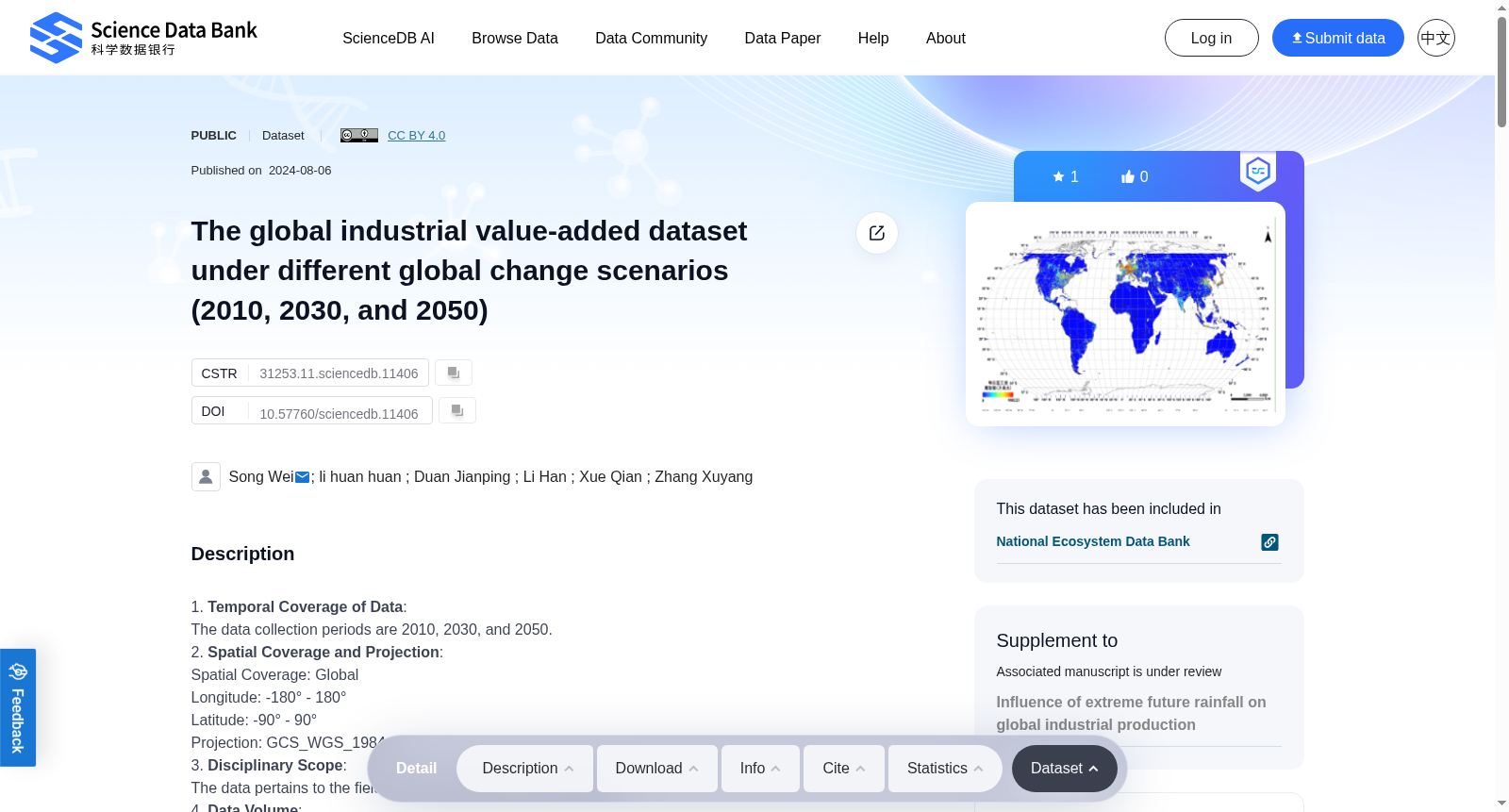
1. Temporal Coverage of Data: The data collection periods are 2010, 2030, and 2050.2. Spatial Coverage and Projection:Spatial Coverage: GlobalLongitude: -180° - 180°Latitude: -90° - 90°Projection: GCS_WGS_19843. Disciplinary Scope: The data pertains to the fields of Earth Sciences and Geography.4. Data Volume: The total data volume is approximately 31.5 MB.5. Data Type: Raster (GeoTIFF)6. Thumbnail (illustrating dataset content or observation process/scene): · 7. Field (Feature) Name Explanation:a. Name Explanation:IND: Industrial Value Addedb. Unit of Measurement:Unit: US Dollars (USD)8. Data Source Description:a. Remote Sensing Data:2010 Global Vegetation Index data (Enhanced Vegetation Index, EVI, from MODIS monthly average data) and 2010 Nighttime Light Remote Sensing data (DMSP/OLS)b. Meteorological Data:From the CMCC-CM model in the Fifth International Coupled Model Intercomparison Project (CMIP5) published by the United Nations Intergovernmental Panel on Climate Change (IPCC)c. Statistical Data:From the World Development Indicators dataset of the World Bank and various national statistical agenciesd. Gross Domestic Product Data:Sourced from the project "Study on the Harmful Processes of Population and Economic Systems under Global Change" under the National Key R&D Program "Mechanisms and Assessment of Risks in Population and Economic Systems under Global Change," led by Researcher Sun Fubao at the Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciencese. Other Data:Rivers, roads, settlements, and DEM, sourced from the National Oceanic and Atmospheric Administration (NOAA), Global Risk Data Platform, and Natural Earth9. Data Processing Methods(1) Spatialization of Baseline Industrial Value Added: Using 2010 global EVI vegetation index data and nighttime light remote sensing data, we addressed the oversaturation issue in nighttime light data by constructing an adjusted nighttime light index to obtain the optimal global light data. The EANTIL model was developed using NTL, NTLn, and EVI data, with the following formula:Here, EANTLI represents the adjusted nighttime light index, NTL represents the original nighttime light intensity value, and NTLn represents the normalized nighttime light intensity value. Based on the optimal light index EANTLI and the industrial value-added data from the World Bank, we constructed a regression allocation model to derive industrial value added (I), generating the global 2010 industrial value-added data with the formula:Here, I represents the industrial value added for each grid cell, and Ii represents the industrial value added for each country, EANTLi derived from ArcGIS statistical analysis and the regression allocation model.(2) Spatial Boundaries for Future Industrial Value Added: Using the Logistic-CA-Markov simulation principle and global land use data from 2010 and 2015 (from the European Space Agency), we simulated national land use changes for 2030 and 2050 and extracted urban land data as the spatial boundaries for future industrial value added. To comprehensively characterize the influence of different factors on land use and considering the research scale, we selected elevation, slope, population, GDP, distance to rivers, and distance to roads as land use driving factors. Accuracy validation using global 2015 land use data showed an average accuracy of 91.89%.(3) Estimation of Future Industrial Value Added: Based on machine learning and using the random forest model, we constructed spatialization models for industrial value added under different climate change scenarios:Here, tem represents temperature, prep represents precipitation, GDP represents national economic output, L represents urban land, D represents slope, and P represents population. The random forest model was constructed using factors such as 2010 industrial value added, urban land distribution, elevation, slope, distances to rivers, roads, railways (considering transportation), and settlements (considering noise and environmental pollution from industrial buildings), along with temperature and precipitation as climate scenario data. Except for varying temperature and precipitation values across scenarios, other variables remained constant. The model comprised 100 decision trees, with each iteration randomly selecting 90% of the samples for model construction and using the remaining 10% as test data, achieving a training sample accuracy of 0.94 and a test sample accuracy of 0.81.By analyzing the proportion of industrial value added to GDP (average from 2000 to 2020, data from the World Bank) and projected GDP under future Shared Socioeconomic Pathways (SSPs), we derived future industrial value added for each country under different SSP scenarios. Using these projections, we constructed regression models to allocate future industrial value added proportionally, resulting in spatial distribution data for 2030 and 2050 under different SSP scenarios.10. Applications and Achievements of the Dataseta. Primary Application Areas: This dataset is mainly applied in environmental protection, ecological construction, pollution prevention and control, and the prevention and forecasting of natural disasters.b. Achievements in Application (Awards, Published Reports and Articles):Achievements: Developed a method for downscaling national-scale industrial value-added data by integrating DMSP/OLS nighttime light data, vegetation distribution, and other data. Published the global industrial value-added dataset.
1. 数据时间覆盖范围:数据采集时段为2010年、2030年及2050年。
2. 空间覆盖范围与投影:
空间覆盖范围:全球;经度范围:-180°~180°;纬度范围:-90°~90°;投影坐标系:GCS_WGS_1984
3. 学科覆盖范围:本数据集涉及地球科学与地理学领域。
4. 数据体量:总数据体量约31.5 MB。
5. 数据类型:栅格数据(GeoTIFF)
6. 缩略图(用于展示数据集内容、观测过程或场景):·
7. 字段(要素)名称说明:
a. 名称释义:IND:工业增加值
b. 计量单位:单位:美元(USD)
8. 数据源说明:
a. 遥感数据:2010年全球植被指数数据(增强型植被指数(Enhanced Vegetation Index, EVI),源自中分辨率成像光谱仪(Moderate Resolution Imaging Spectroradiometer, MODIS)月均数据集)及2010年夜间灯光遥感数据(国防气象卫星计划/线扫描系统(Defense Meteorological Satellite Program/Operational Linescan System, DMSP/OLS))
b. 气象数据:源自联合国政府间气候变化专门委员会(Intergovernmental Panel on Climate Change, IPCC)发布的第五次国际耦合模式比较计划(Coupled Model Intercomparison Project Phase 5, CMIP5)中的CMCC-CM模式数据
c. 统计数据:源自世界银行世界发展指标数据集及各国官方统计机构
d. 国内生产总值(GDP)数据:源自中国科学院地理科学与资源研究所孙富宝研究员牵头承担的国家重点研发计划“全球变化下人口与经济系统风险机制与评估”下属课题“全球变化下人口与经济系统有害过程研究”
e. 其他数据:河流、道路、居民点及数字高程模型(Digital Elevation Model, DEM),源自美国国家海洋和大气管理局(National Oceanic and Atmospheric Administration, NOAA)、全球风险数据平台及Natural Earth
9. 数据处理方法:
(1) 基准期工业增加值空间化:采用2010年全球增强型植被指数数据与夜间灯光遥感数据,通过构建修正夜间灯光指数解决夜间灯光数据的过饱和问题,以获取最优全球灯光数据。基于原始夜间灯光强度值(NTL)、归一化夜间灯光强度值(NTLn)及增强型植被指数数据构建EANTIL模型,公式如下:
此处EANTLI代表修正后夜间灯光指数,NTL代表原始夜间灯光强度值,NTLn代表归一化夜间灯光强度值。基于最优灯光指数EANTLI及世界银行公布的工业增加值数据,构建回归分配模型以推导工业增加值(I),生成2010年全球工业增加值数据集,公式如下:
此处I代表单个栅格单元的工业增加值,Ii代表单个国家的工业增加值,EANTLi通过ArcGIS统计分析及回归分配模型获取。
(2) 未来工业增加值空间边界:采用Logistic-CA-Markov模拟原理,结合欧洲空间局(European Space Agency, ESA)发布的2010年、2015年全球土地利用数据,模拟2030年、2050年各国土地利用变化,并提取城镇用地数据作为未来工业增加值的空间约束边界。为全面表征不同要素对土地利用的影响,结合研究尺度,选取高程、坡度、人口、GDP、距河流距离及距道路距离作为土地利用驱动因子。采用2015年全球土地利用数据进行精度验证,平均精度达91.89%。
(3) 未来工业增加值估算:基于机器学习方法,采用随机森林模型构建不同气候变化情景下的工业增加值空间化模型:
此处tem代表气温,prep代表降水,GDP代表国民经济总产出,L代表城镇用地面积,D代表坡度,P代表人口总量。
以2010年工业增加值、城镇用地分布、高程、坡度、距河流、道路、铁路的距离(考虑交通通达性因素)及居民点(考虑工业建筑产生的噪声与环境污染)等要素,结合气温与降水等气候情景数据,构建随机森林模型。除不同情景下气温与降水取值存在差异外,其余变量均保持恒定。该模型包含100棵决策树,每次迭代随机选取90%的样本用于模型训练,剩余10%作为测试集,训练样本精度达0.94,测试样本精度达0.81。
通过分析工业增加值占GDP的比重(2000-2020年平均值,数据源自世界银行)及未来共享社会经济路径(Shared Socioeconomic Pathways, SSPs)下的GDP预测值,推导不同SSP情景下各国的未来工业增加值。基于上述预测结果构建回归分配模型进行比例分配,最终生成不同SSP情景下2030年、2050年的工业增加值空间分布数据。
10. 数据集应用与成果:
a. 主要应用领域:本数据集主要应用于环境保护、生态建设、污染防治及自然灾害预防与预警等领域。
b. 应用成果(奖项、已发表报告与学术论文):
成果:提出了一种整合DMSP/OLS夜间灯光数据、植被分布等多源数据的国家级工业增加值数据降尺度方法,已发布全球工业增加值数据集。
提供机构:
Science Data Bank
创建时间:
2024-08-06
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含全球工业增加值在2010年、2030年和2050年的空间分布数据,采用GeoTIFF格式,数据量约31.5 MB。数据结合了遥感、气象和统计信息,通过随机森林模型和回归分配方法生成,主要应用于环境保护、生态建设和自然灾害预测等领域。
以上内容由遇见数据集搜集并总结生成


