zygaireasearch2025and2026
收藏Hugging Face2025-11-03 更新2025-11-04 收录
下载链接:
https://huggingface.co/datasets/ZygAI/zygaireasearch2025and2026
下载链接
链接失效反馈官方服务:
资源简介:
ZygAI Research 2025–2026是一个多语言的开源数据集集合,专注于立陶宛,包括其技术、历史、语言、社会和文化。该数据集是在MIT许可下创建的,用于研究、教育和AI模型训练。数据集包含多个主题,如地理、文化、语言、人物、技术、历史、自然科学、兴趣爱好、同理心与心理学以及其他杂项主题。数据集的目的是为构建一个以立陶宛为中心的AI模型ZygAI GPT提供一个公开的、道德获取的数据基础。
创建时间:
2025-10-31
原始信息汇总
ZygAI Research 2025–2026 数据集概述
基本信息
- 数据集名称: ZygAI Research 2025–2026
- 许可证: MIT
- 支持语言: 英语(en)、立陶宛语(lt)
- 数据规模: 1K<n<10K
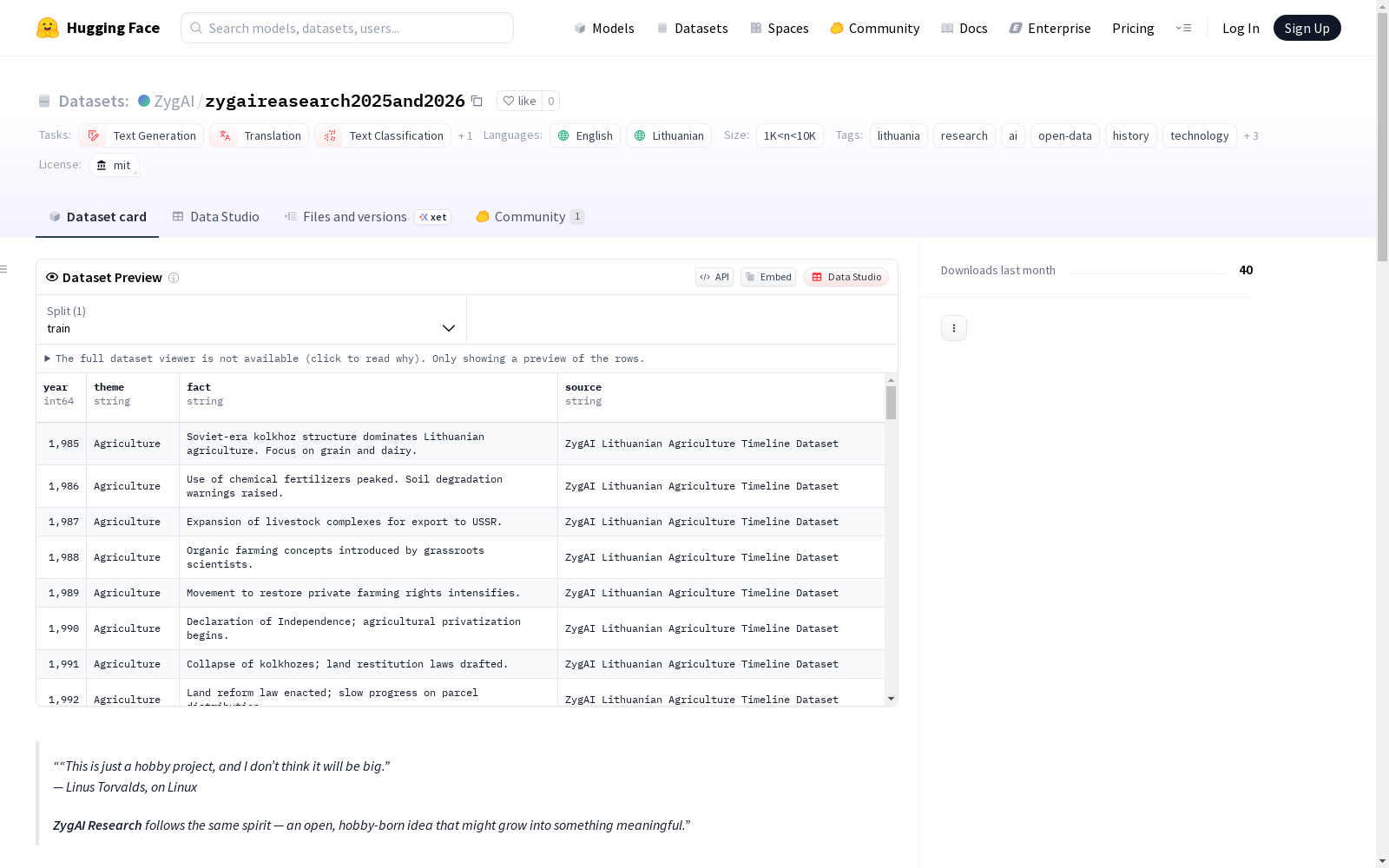
数据集内容
文件构成
| 文件名 | 描述 |
|---|---|
| zygai_lithuania_wikipedia_research_v2.json | 150篇关于立陶宛的双语维基百科风格文章 |
| zygai_technology_research_v1.json | 120个关于人工智能、初创企业、绿色技术、基础设施和创新的条目 |
| zygai_history_timeline_v1.json | 68个从公元1009年到2024年的历史事件及元数据 |
| zygai_regional_traditions_v1.json | 80多条关于立陶宛地区习俗和民俗的记录 |
| zygai_soviet_lithuania_life_sources.json | 苏联时期文化、日常生活和口述历史资料 |
| zygvlogs_lithuanian_nlp_research_sources.json | 立陶宛自然语言处理和语言学研究资料 |
主题分布
- 50%: 立陶宛(地理、文化、语言、人民)
- 10%: 技术(人工智能、Linux、创新、基础设施)
- 10%: 历史(含地理背景)
- 10%: 自然科学/生物学
- 10%: 爱好和一般兴趣
- 5%: 同理心与心理学
- 5%: 杂项主题
技术规格
- 格式: JSON
- 典型字段: topic, text_lt, text_en, category, source, keywords
- 任务类别: 文本生成、翻译、文本分类、问答
用途
- 自然语言处理微调(文本生成、翻译、摘要)
- 教育和文化研究
- 人工智能对齐和伦理实验
- 历史和社会学分析
项目愿景
开发开放式的立陶宛人工智能模型和知识库,供所有人使用。
搜集汇总
数据集介绍
构建方式
在数字人文与计算社会科学交叉领域,ZygAI Research 2025–2026数据集通过系统化采集多源异构数据构建而成。其核心内容涵盖立陶宛的技术发展、历史脉络、文化传统及社会形态,采用双语平行语料架构,每个条目均包含立陶宛语与英语的双向文本对照。数据来源融合了维基百科式结构化条目、技术文献摘录、历史年表事件及民俗田野记录,并通过主题分类、关键词标注与元数据嵌入实现多维语义关联。所有数据均遵循开放获取原则,以JSON格式保存并配备完整的来源追溯信息。
特点
该数据集最显著的特征在于其立陶宛中心化的知识覆盖体系,其中约50%内容聚焦于立陶宛的地理文化、语言习俗及社会变迁。数据呈现多模态特性,既包含技术领域的创新动态与历史事件的时空坐标,又融入了区域传统习俗的口述史料与自然科学的交叉视角。其语言资源兼具立陶宛语与英语的双语平行语料,支持跨语言语义对齐研究。数据集规模控制在千至万级别,既保障了内容的深度与多样性,又避免了海量数据带来的处理负担,特别适合中小规模模型的精细化训练。
使用方法
研究者可通过解析JSON文件中的结构化字段(如topic、text_lt、text_en、category等)直接调用数据。该数据集支持多任务自然语言处理应用,包括文本生成、机器翻译、主题分类与问答系统构建。在文化计算领域,可结合历史时间线与地域标签进行社会演变分析;技术类条目则适用于AI伦理对齐实验与创新趋势挖掘。教育场景中,双语对照文本可作为语言学习与跨文化研究的素材库。所有使用均需遵循MIT许可协议,允许学术、商业及个人用途的二次开发与传播。
背景与挑战
背景概述
在数字人文与多语言人工智能技术蓬勃发展的背景下,ZygAI Research 2025–2026数据集于2025年由立陶宛研究者Žygimantas Mažeika主导创建,作为一项开源倡议,旨在系统整合立陶宛的技术、历史、语言、社会与文化等多维度知识。该数据集以MIT许可证发布,覆盖双语文本生成、翻译、分类及问答等自然语言处理任务,核心目标是为构建立陶宛中心化AI模型(ZygAI GPT)提供伦理化数据基础,推动教育、文化研究与技术创新的跨领域融合。
当前挑战
该数据集致力于解决立陶宛语资源稀缺性挑战,尤其在低资源语言处理与多模态知识融合方面存在技术瓶颈;构建过程中面临多源数据整合的复杂性,包括历史文献的跨时代语义对齐、文化术语的双语一致性维护,以及非结构化口头传统的标准化转换,这些因素均对数据的质量与可扩展性构成考验。
常用场景
经典使用场景
在自然语言处理领域,ZygAI Research数据集凭借其双语结构和丰富主题,常被用于训练多语言文本生成模型。研究者通过其涵盖立陶宛历史、科技与文化的150篇维基百科式文章,能够有效提升模型对特定文化语境的理解能力,尤其在跨语言文本生成和语义对齐任务中展现出独特价值。
衍生相关工作
基于该数据集衍生的经典工作包括立陶宛理工大学开发的ZygGPT语言模型,该模型在理解立陶宛方言习语方面取得突破。同时催生了《波罗的海区域AI伦理框架》白皮书,以及维尔纽斯大学利用苏维埃时期生活史料开展的数字化口述历史项目,这些成果持续推动着东欧地区人工智能与人文研究的深度融合。
数据集最近研究
最新研究方向
在立陶宛历史文化与人工智能交叉领域,该数据集正推动多语言模型的本土化研究。前沿探索聚焦于利用双语语料构建文化敏感的生成式AI系统,尤其在低资源语言保护与数字传承方面展现出独特价值。随着欧盟对文化多样性技术的重视,相关研究已延伸至历史事件的可解释性分析与技术伦理评估,为小语种区域的AI治理提供实证基础。
以上内容由遇见数据集搜集并总结生成


