ADSKAILab/Zero-To-CAD-100k
收藏Hugging Face2026-05-03 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/ADSKAILab/Zero-To-CAD-100k
下载链接
链接失效反馈官方服务:
资源简介:
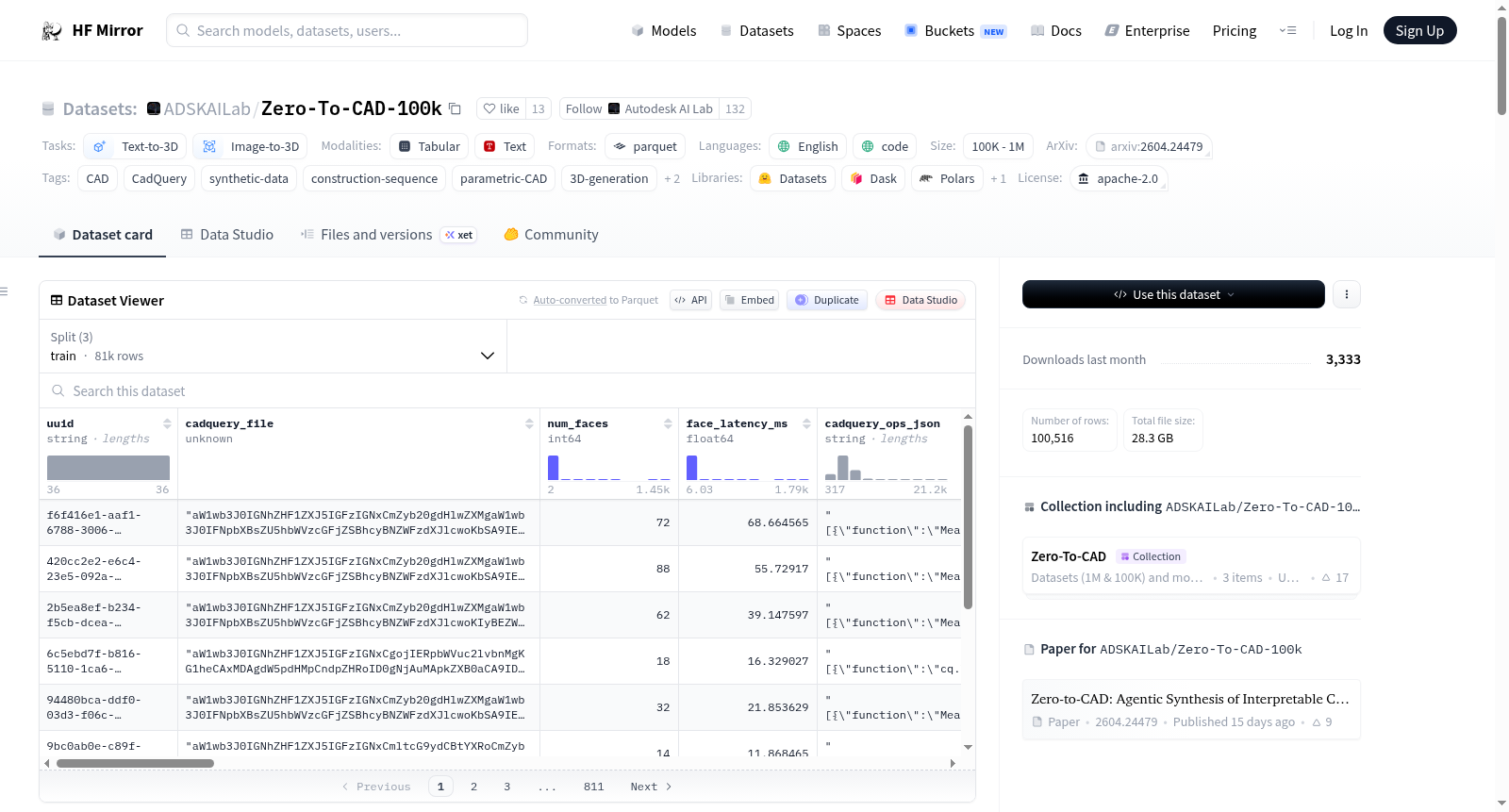
这是Zero-to-CAD的精选100K子集,旨在为计算资源有限的研究者提供一个易于访问的入口。样本从完整的1M数据集中选出,以确保最大的几何多样性。通过视觉嵌入(使用DINOv3特征)、聚类(K-means)和选择(每个簇中选择最接近中心的样本)的过程,确保子集涵盖了1M数据集中所有零件类型、操作和几何复杂性的完整分布。数据集包含81,015个训练样本、9,734个验证样本和9,767个测试样本,每个样本包含唯一标识符、可执行的CadQuery Python源代码、B-Rep面数、CAD操作列表、渲染视图、STL和STEP文件等字段。
This is the curated 100K subset of Zero-to-CAD, designed as an accessible entry point for researchers working with limited compute. The samples are selected for maximum geometric diversity from the full 1M dataset. Through a process of visual embedding (using DINOv3 features), clustering (K-means), and selection (choosing the nearest-to-centroid exemplar from each cluster), the subset spans the full distribution of part types, operations, and geometric complexity present in the 1M dataset. The dataset includes 81,015 training samples, 9,734 validation samples, and 9,767 test samples, each containing fields such as a unique identifier, executable CadQuery Python source code, B-Rep face count, CAD operation list, rendered views, STL, and STEP files.
提供机构:
ADSKAILab
搜集汇总
数据集介绍
构建方式
Zero-To-CAD-100k是从百万级合成CAD数据集Zero-To-CAD-1M中精心筛选出的子集,旨在为计算资源有限的科研人员提供一座便捷的入门桥梁。构建过程采用基于视觉表征的聚类采样策略:首先将每个CAD模型从八个视角渲染并利用DINOv3特征编码,通过对多视角特征取均值获得鲁棒的表征向量;随后利用K-means算法将海量嵌入空间划分为十万个聚类,并从每个聚类中选取距离质心最近的样本作为代表。这一方法确保了子集在几何形状、零件类型、操作序列复杂度等多个维度上完整保留了原始数据集的分布特征。
特点
该数据集共含十万条样本,划分为训练集、验证集和测试集,每个样本均包含可执行的CadQuery源代码、八张256×256分辨率的多视角渲染图像、精确的边界表示面数以及完整的CAD操作序列日志。数据覆盖了丰富的几何操作词汇,涵盖草图图元、三维构造、布尔运算、特征修饰与阵列模式等。尤为突出的是,该数据集中所有样本均经过几何多样性最大化的筛选,能够有效支撑文本到三维、图像到三维以及可解释CAD程序生成的建模任务,同时为智能体式AI的自动程序设计研究提供了结构化、多样化的训练材料。
使用方法
研究人员可通过HuggingFace Datasets库便捷地加载数据,支持流式读取以降低内存开销。加载后的样本可直接获取二进制格式的CAD程序代码,经UTF-8解码后得到可执行的CadQuery脚本,借助Python的exec函数即可在CadQuery环境中重建三维实体模型。配合IPython的display接口,能够实现模型的可视化交互呈现。此外,原始百万级数据集中预计算的高维DINOv3嵌入向量与FAISS索引文件均可直接复用,使得基于欧氏距离的相似性检索或k近邻分析在本子集上同样适用,为快速原型验证与模型评测提供了完整的数据基础设施。
背景与挑战
背景概述
计算机辅助设计(CAD)作为现代工程与制造业的基石,其核心在于通过参数化与构造序列生成可编辑、可解释的3D模型。然而,现有大规模3D数据集多聚焦于不可直接编辑的网格或点云表示,缺乏对CAD构造逻辑的忠实还原。在此背景下,Autodesk Research团队于2026年发布了Zero-To-CAD-100k数据集,由Mohammadmehdi Ataei等人创建,旨在为文本和图像到CAD的生成任务提供高质量、几何多样化的训练与评估基准。作为百万级Zero-To-CAD-1M的精选子集,该数据集通过视觉嵌入聚类与最近质心采样策略,从超过81,015个训练样本中保留了最为丰富的零件类型与操作模式,为可解释CAD程序生成领域提供了标准化数据支撑,显著推动了从非结构化输入到结构化构造序列的技术演进。
当前挑战
该数据集的核心挑战在于双重维度:一者,领域问题层面,需解决从文本或图像等非结构化输入中生成可执行、可编辑的CAD程序,这要求模型同时理解几何拓扑、构造逻辑与操作语义,其复杂度远超传统的静态3D生成任务。二者,构建过程面临数据稀缺与多样性矛盾——真实CAD数据因商业保密难以获取,合成数据又易陷入模式单一;本研究通过感知驱动的聚类选择策略,从百万级候选池中筛选出几何覆盖最广的样本,但如何确保筛选过程不丢失稀有构造模式,仍是一项精心调谐的平衡。此外,数据字段中多视角渲染、多格式导出(STL/STEP)与构造操作链的精确对齐,对管线鲁棒性与计算效率提出了严苛要求。
常用场景
经典使用场景
在计算机辅助设计与三维视觉交叉研究领域,Zero-To-CAD-100k数据集为从文本或图像到可执行参数化CAD程序的高效生成提供了理想的研究平台。其经典使用场景聚焦于训练和评估能够将自然语言描述或二维视觉输入转化为结构化、可编辑的CadQuery代码序列的深度学习模型。研究人员利用该数据集中包含的八视角渲染图像、完整的CAD构建脚本及丰富的操作元数据,可系统性地探索程序化三维内容生成任务,尤其适用于在计算资源受限环境下快速验证模型架构与训练策略。
解决学术问题
该数据集旨在攻克三维模型生成领域长期存在的核心学术难题:如何在不依赖大规模真实人工标注数据的前提下,实现高几何多样性、可解释且程序化的CAD模型合成。传统方法多受限于低效的网格表示或依赖昂贵的手工CAD标注,而Zero-To-CAD-100k通过创新的代理式合成管线,以百万规模生成了包含完整构建序列的参数化CAD程序,为从非结构化输入到结构化程序映射的研究提供了方法论基石。其意义在于推动了程序化三维内容生成从经验驱动向数据驱动的范式转变,显著降低了该领域对真实人工数据的依赖。
衍生相关工作
围绕Zero-To-CAD-100k数据集,学术界已衍生出一系列卓有影响力的研究工作。其中,基于该数据集微调的Qwen3-VL-2B视觉语言模型展示了多模态输入直接驱动CAD程序生成的前沿能力,为多模态学习与程序合成的深度融合开辟了新路径。此外,伴随数据集发布的高质量DINOv3特征嵌入和FAISS索引,催生了一系列关于程序化CAD模型的几何多样性度量、聚类分析与相似性检索的后续探索。这些工作共同构建了一个从数据构建、模型训练到性能评估的完整研究生态,不断推动着可解释三维内容生成领域的边界拓展。
以上内容由遇见数据集搜集并总结生成


