MultiOCR-QA
收藏arXiv2025-02-24 更新2025-02-26 收录
下载链接:
https://github.com/DataScienceUIBK/MultiOCR-QA
下载链接
链接失效反馈官方服务:
资源简介:
MultiOCR-QA是一个多语言问答数据集,由因斯布鲁克大学创建,包含英语、法语和德语三种语言,共有60K个问题-答案对。数据集由经过OCR处理的历史文本构成,旨在评估OCR噪声对问答系统性能的影响。数据集涵盖了从OCR文本中直接生成的原始文本(RawOCR)和经过校正的文本(CorrectedOCR),使得可以在不同文本质量条件下直接比较问答性能。
MultiOCR-QA is a multilingual question answering dataset developed by the University of Innsbruck. It covers three languages: English, French and German, with a total of 60K question-answer pairs. The dataset is built from OCR-processed historical texts, and its core goal is to evaluate the impact of OCR-induced noise on the performance of question answering systems. It includes two types of texts: raw OCR-processed texts (RawOCR) and corrected texts (CorrectedOCR), which enables direct comparison of question answering performance under different text quality conditions.
提供机构:
因斯布鲁克大学
创建时间:
2025-02-24
搜集汇总
数据集介绍
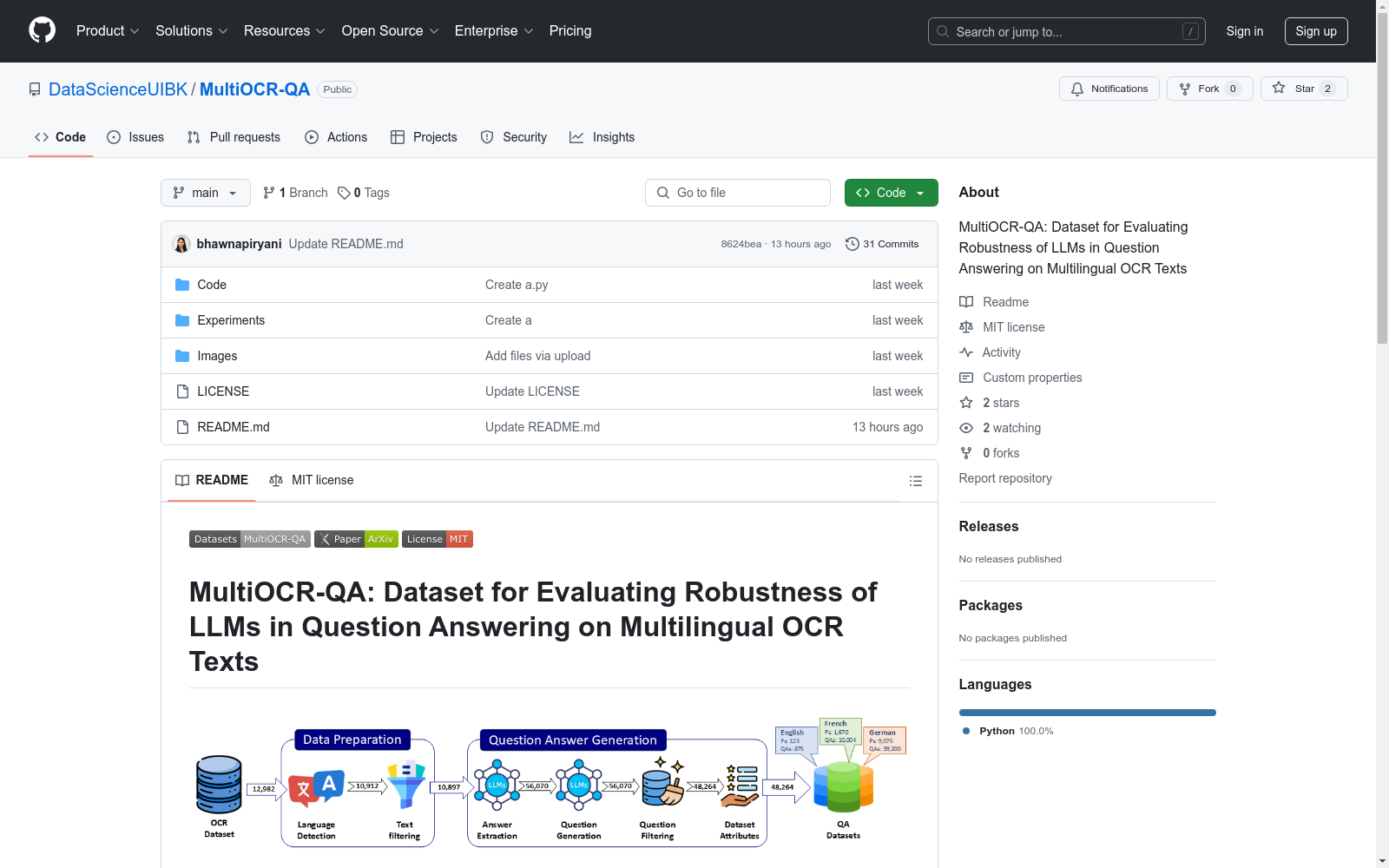
构建方式
MultiOCR-QA数据集的构建过程主要分为数据收集和问答生成两个阶段。数据收集阶段,研究人员从ICDAR 2019 POST-OCR Text Correction数据集中选取了英语、法语和德语三种语言的历史文本。然后,通过语言检测和过滤,确保文档中包含正确的目标语言文本。问答生成阶段,研究人员使用预训练的大语言模型(LLM)针对每种语言进行指令微调,以从正确的OCR文本中自动生成问答对。为了确保问答对的质量和一致性,研究人员还进行了数据过滤,移除了不符合要求的问题。
使用方法
MultiOCR-QA数据集可以用于评估大型语言模型(LLM)在处理带有噪声的OCR文本时的问答性能。研究人员可以在这个数据集上训练和评估LLM,以改进它们对OCR错误的认识和鲁棒性。此外,该数据集还可以用于研究问答模型在处理低资源语言时的多语言处理能力。使用该数据集时,研究人员可以针对不同类型的OCR错误和噪声级别进行实验,以评估不同模型在处理噪声OCR文本时的性能。
背景与挑战
背景概述
在数字化历史和多种语言文档的过程中,光学字符识别(OCR)技术发挥着至关重要的作用。然而,由于历史文档的退化和OCR技术的局限性,OCR生成的文本常常包含错误,如字符插入、删除和替换等。这些错误可能会严重影响下游任务,如问答(QA)系统的性能。为了评估OCR噪声对QA系统性能的影响,Bhawna Piryani等人于2018年创建了MultiOCR-QA数据集。该数据集包括来自英语、法语和德语的60K个问答对,是从经过OCR处理的历史文档中整理而成的。MultiOCR-QA数据集的创建旨在提供一个评估LLMs在处理真实世界数字化错误时的鲁棒性的平台,对于相关领域的研究具有深远的影响。
当前挑战
MultiOCR-QA数据集面临的挑战主要涉及OCR噪声对QA系统性能的影响。具体挑战包括:1) OCR错误类型,如插入、删除和替换,对QA性能的影响;2) 构建过程中遇到的挑战,如数据收集、QA对生成和OCR错误量化等。这些挑战需要研究人员在处理历史文档和多种语言时,开发更鲁棒的QA系统,并提高OCR错误纠正能力。
常用场景
经典使用场景
MultiOCR-QA数据集主要用于评估大型语言模型(LLMs)在处理多语言OCR文本时的鲁棒性。该数据集由60K个问答对组成,涵盖了英语、法语和德语三种语言,并包含了OCR错误文本和正确文本,从而可以在不同文本质量条件下进行直接比较。该数据集是专门为分析OCR噪声对问答系统性能的影响而设计的,这对于处理历史文本和档案材料等任务至关重要。
解决学术问题
MultiOCR-QA数据集解决了OCR错误对问答系统性能的影响这一学术研究问题。通过包含OCR错误文本和正确文本,该数据集允许研究人员直接比较不同文本质量条件下的问答性能,从而深入理解OCR噪声对问答系统的影响。此外,该数据集还提供了不同类型和级别的OCR错误,使研究人员能够评估这些错误对问答性能的个别影响,并为处理OCR相关挑战提供见解。
实际应用
MultiOCR-QA数据集在实际应用中可用于训练LLMs,以提高其错误校正能力,增强其对OCR不准确的鲁棒性,同时保留古语言结构。此外,该数据集还可用于扩展LLMs的多语言处理能力,通过在多语言OCR文本上进行训练,提高低资源语言的准确性。这对于处理历史文本和档案材料等任务至关重要,这些任务通常涉及多种语言和复杂的文本结构。
数据集最近研究
最新研究方向
在多语言光学字符识别(OCR)文本上进行问答(QA)任务的鲁棒性评估是当前自然语言处理(NLP)领域的前沿研究方向。MultiOCR-QA数据集的引入填补了这一领域的空白,为评估大型语言模型(LLM)在面对OCR噪声时的性能提供了一个全面的平台。该数据集不仅包含了三种语言的原始和校正后的OCR文本,还包含了由历史文本生成的QA对,使得研究人员能够系统地分析不同类型的OCR错误对QA系统性能的影响。此外,MultiOCR-QA还展示了LLM在不同噪声水平下的性能变化,揭示了LLM在处理噪声文本时的局限性和优势。未来的研究可以进一步探索OCR错误校正策略的整合,以及针对低资源语言的LLM训练方法,以提升LLM在处理历史文档和低资源语言文本时的鲁棒性和准确性。
相关研究论文
- 1MultiOCR-QA: Dataset for Evaluating Robustness of LLMs in Question Answering on Multilingual OCR Texts因斯布鲁克大学 · 2025年
以上内容由遇见数据集搜集并总结生成


