Srijan-Srivastava/webtext-super-tiny
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Srijan-Srivastava/webtext-super-tiny
下载链接
链接失效反馈官方服务:
资源简介:
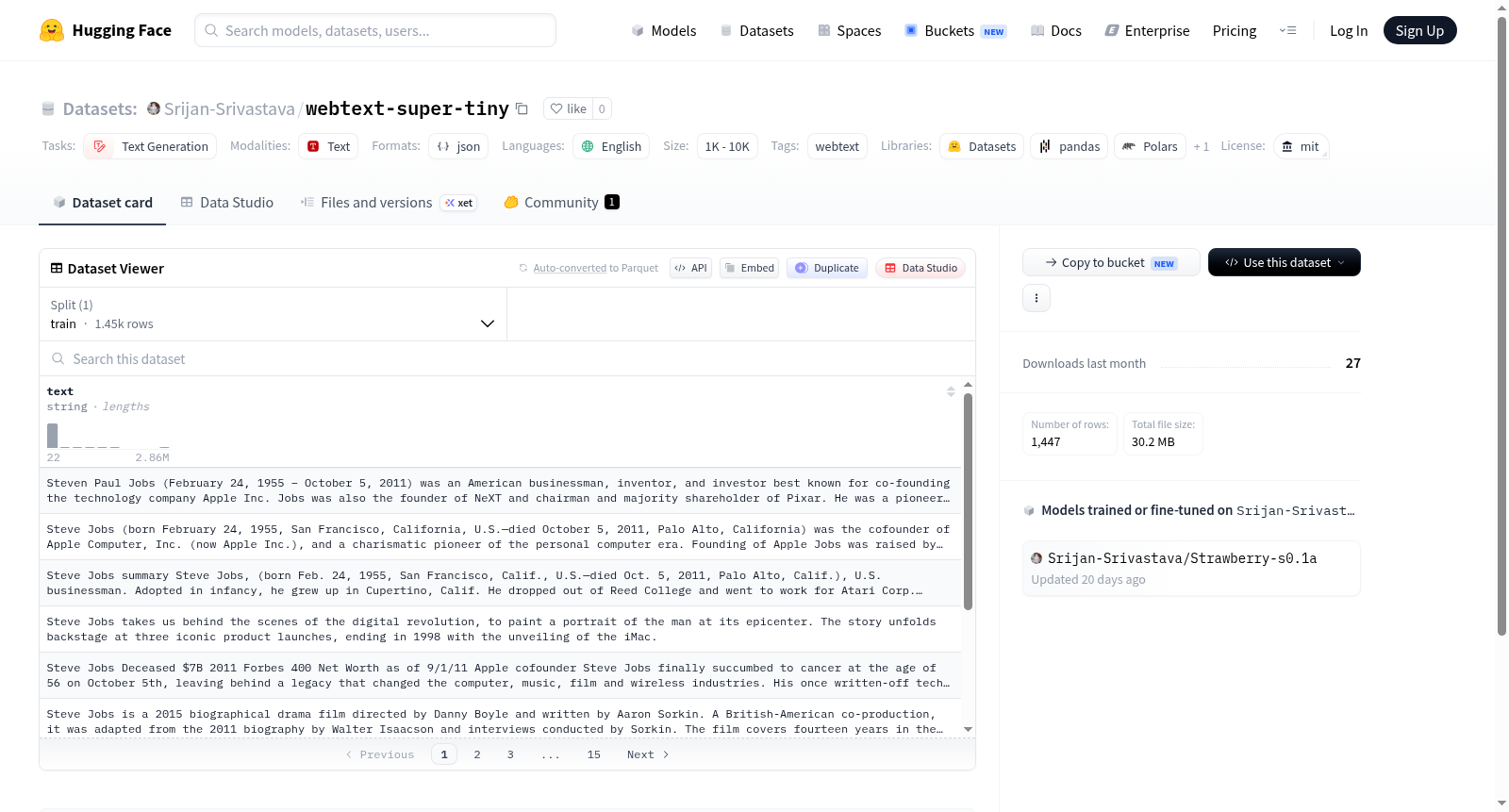
Webtext-Super-Tiny是一个小型英语文本生成数据集,基于网络文本构建,适用于自然语言处理任务,特别是文本生成。数据集规模在1,000到10,000个样本之间,采用MIT许可证发布。
Webtext-Super-Tiny is a small English text generation dataset built from webtext, suitable for natural language processing tasks, particularly text generation. The dataset size ranges between 1,000 and 10,000 samples and is released under the MIT license.
提供机构:
Srijan-Srivastava
搜集汇总
数据集介绍
构建方式
Webtext-Super-Tiny数据集源自大规模的Webtext语料库,通过精心筛选与压缩流程构建而成。其原始数据采集自互联网公开文本,涵盖新闻、论坛、博客等多类来源,经去重、清洗及质量过滤后,随机抽取极小规模子集形成本数据集。最终样本数量介于1000至10000条之间,保留了原始语料的多样性与语言风格,适用于轻量级文本生成任务的研究与验证。
特点
该数据集以“超小规模”为核心特点,在保持文本生成领域典型任务标签(text-generation)的同时,实现了极低的存储与计算开销。所有样本均为英文,采用MIT开源协议发布,便于学术与工业界快速集成。其小巧体积使其成为模型原型测试、教学演示及性能基准调试的理想选择,尤其适合资源受限场景下的快速迭代。
使用方法
使用Webtext-Super-Tiny时,可直接通过Hugging Face Datasets库加载,调用load_dataset('webtext-super-tiny')即可获取数据。数据集默认适用于文本生成任务,用户可根据需要将样本作为自回归语言模型的输入输出对,或用于微调预训练模型。其轻量特性支持在单机CPU环境下进行快速实验,亦可在少量迭代周期内验证模型生成效果与收敛性。
背景与挑战
背景概述
Webtext-Super-Tiny数据集诞生于自然语言处理领域中文本生成任务蓬勃发展的时期,旨在为研究者提供一个轻量级、易于使用的基准测试资源。该数据集由开源社区构建,采用MIT许可证发布,其核心研究问题聚焦于评估和微调文本生成模型在有限数据规模下的性能表现。尽管数据量微小(1K至10K样本),但作为Webtext系列的简化版本,它承载了推动模型可复现性与快速迭代的重要使命,特别适用于原型验证和教学场景,在小型实验环境中展现出独特价值。
当前挑战
该数据集面临的挑战主要体现在领域问题层面:文本生成任务要求模型捕捉长程依赖与语义连贯性,而极小的数据量(不超过万条样本)极易导致过拟合,难以代表Web文本的多样性与复杂性,限制了模型泛化能力的评估。构建过程中,尽管数据采集自网络文本,但如何从海量原始内容中筛选出既符合语言规范又具有代表性的样本,同时保证标注一致性与格式清洁,在资源有限条件下成为关键难题。此外,数据规模过小使得统计显著性测试难以实施,加剧了结果可靠性的不确定性。
常用场景
经典使用场景
Webtext-Super-Tiny 数据集作为文本生成领域的微型样本集,常被用于语言模型的快速原型验证与教学演示场景。由于其规模极小(介于1千至1万条样本之间),研究者可借助该数据集在有限计算资源下快速测试生成式模型的架构设计、采样策略或损失函数调优,避免大规模训练带来的时间开销。在自然语言处理课程与学术入门教程中,该数据集亦扮演着标准测试用例的角色,帮助学习者直观理解自回归语言模型从数据预处理到文本输出的完整流程。
衍生相关工作
围绕Webtext-Super-Tiny 衍生的经典工作包括:将数据增强技术与极小样本结合,探索基于提示微调(Prompt Tuning)在少样本场景下的鲁棒性边界;此外,基于该数据集对比不同压缩算法(如权重共享与低秩分解)对生成质量的影响,推动了模型轻量化理论的发展。学界还利用该数据集作为标准化评测单元,归因分析不同随机种子与束搜索宽度对文本多样性-质量权衡的敏感度,这些工作为后续大规模数据集上的实验设计提供了方法论参考。
数据集最近研究
最新研究方向
Webtext-Super-Tiny数据集作为轻量级文本生成基准,正推动小型语言模型在资源受限场景下的前沿应用。当前研究方向聚焦于利用该数据集进行高效微调与知识蒸馏实验,特别是在边缘计算与实时交互系统中,以极少量样本验证生成模型在低资源环境下的泛化能力。该数据集的精简规模与MIT开源许可,极大促进了快速原型开发与学术复现,为NLP领域在模型压缩、零样本学习等热点议题提供了标准化测试床,其影响在于降低了研究门槛,加速了从实验到部署的转化周期。
以上内容由遇见数据集搜集并总结生成


