VisionArena-Chat
收藏魔搭社区2026-05-09 更新2025-04-26 收录
下载链接:
https://modelscope.cn/datasets/lmarena-ai/VisionArena-Chat
下载链接
链接失效反馈官方服务:
资源简介:

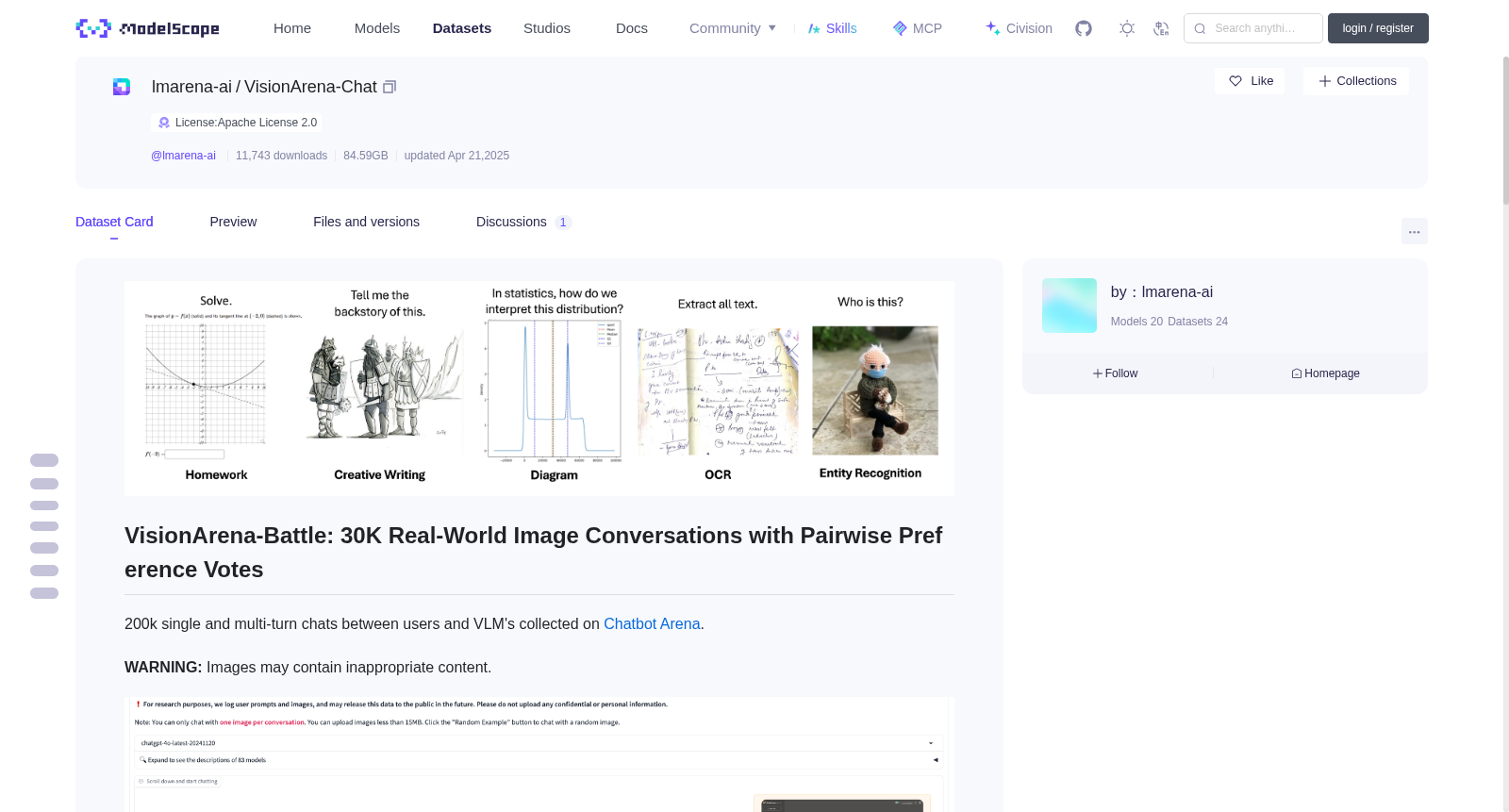
# VisionArena-Battle: 30K Real-World Image Conversations with Pairwise Preference Votes
200k single and multi-turn chats between users and VLM's collected on [Chatbot Arena](https://lmarena.ai/).
**WARNING:** Images may contain inappropriate content.

## Dataset Details
* 200K conversations
* 45 VLM's
* 138 languages
* ~43k unique images
* Question Category Tags (Captioning, OCR, Entity Recognition, Coding, Homework, Diagram, Humor, Creative Writing, Refusal)
### Dataset Description
200,000 conversations where users interact with two anonymized VLMs,collected through the open-source platform [Chatbot Arena](https://lmarena.ai/), where users chat with LLMs and VLMs through direct chat, side-by-side, or anonymous side-by-side chats. Users provide preference votes for responses, which are aggregated using the Bradley-Terry model to compute [leaderboard rankings](https://lmarena.ai/?leaderboard). Data for anonymous side-by-side chats can be found [here](https://huggingface.co/datasets/lmarena-ai/VisionArena-Battle).
The dataset includes conversations from February 2024 to September 2024. Users explicitly agree to have their conversations shared before chatting. We apply an [NSFW](https://learn.microsoft.com/en-us/azure/ai-services/content-moderator/image-moderation-api), [CSAM](https://www.microsoft.com/en-us/photodna?oneroute=true), PII ([text](https://learn.microsoft.com/en-us/azure/search/cognitive-search-skill-pii-detection), and face detectors ([1](https://cloud.google.com/vision/docs/detecting-faces), [2](https://github.com/ageitgey/face_recognition)) to remove any inappropriate images, personally identifiable images/text, or images with human faces. These detectors are not perfect, so such images may still exist in the dataset.
### Dataset Sources
- **Repository:** https://github.com/lm-sys/FastChat
- **Paper:** https://arxiv.org/abs/2412.08687
- **Chat with the lastest VLMs and contribute your vote!** https://lmarena.ai/
Images are stored in byte format, you can decode with `Image.open(BytesIO(img["bytes"]))`
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
* **model** - model identity.
* **images** - image (note: these are single image conversations only)
* **conversation**- conversation with each model
* **user_id** - hash of user id, based on IP address
* **categories** - category labels (note: a question can belong to multiple categories)
* **num_turns** - number of conversation turns
* **tstamp** timestamp of when the conversation took place
* **is_preset** - if the image is from the "random image button"
* **dataset_preset** - which dataset the preset image is from. This can be either [NewYorker](https://huggingface.co/datasets/jmhessel/newyorker_caption_contest), [WikiArt](https://huggingface.co/datasets/huggan/wikiart), [TextVQA](https://huggingface.co/datasets/facebook/textvqa), [ChartQA](https://huggingface.co/datasets/lmms-lab/ChartQA), [DocQA](https://huggingface.co/datasets/lmms-lab/DocVQA), or [realworldqa](https://x.ai/blog/grok-1.5v)
## Bias, Risks, and Limitations
This dataset contains a large amount of STEM related questions, OCR tasks, and general problems like captioning. This dataset contains less questions which relate to specialized domains outside of stem.
**If you find your face or personal information in this dataset and wish to have it removed, or if you find hateful or inappropriate content,** please contact us at lmarena.ai@gmail.com or lisabdunlap@berkeley.edu. See licensing agreement below for more details.
**BibTeX:**
```
@article{chou2024visionarena,
title={VisionArena: 230K Real World User-VLM Conversations with Preference Labels},
author={Christopher Chou and Lisa Dunlap and Koki Mashita and Krishna Mandal and Trevor Darrell and Ion Stoica and Joseph E. Gonzalez and Wei-Lin Chiang},
year={2024},
eprint={2412.08687},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2412.08687},
}
```
## LMArena VisionArena dataset License Agreement
This Agreement contains the terms and conditions that govern your access and use of the LMArena VisionArena dataset (as defined above). You may not use the LMArena VisionArena dataset if you do not accept this Agreement. By clicking to accept, accessing the LMArena VisionArena dataset, or both, you hereby agree to the terms of the Agreement. If you are agreeing to be bound by the Agreement on behalf of your employer or another entity, you represent and warrant that you have full legal authority to bind your employer or such entity to this Agreement. If you do not have the requisite authority, you may not accept the Agreement or access the LMArena VisionArena dataset on behalf of your employer or another entity.
* Safety and Moderation: This dataset contains unsafe conversations that may be perceived as offensive or unsettling. User should apply appropriate filters and safety measures before utilizing this dataset for training dialogue agents.
* Non-Endorsement: The views and opinions depicted in this dataset do not reflect the perspectives of the researchers or affiliated institutions engaged in the data collection process.
* Legal Compliance: You are mandated to use it in adherence with all pertinent laws and regulations.
* Model Specific Terms: When leveraging direct outputs of a specific model, users must adhere to its corresponding terms of use.
* Non-Identification: You must not attempt to identify the identities of individuals or infer any sensitive personal data encompassed in this dataset.
* Prohibited Transfers: You should not distribute, copy, disclose, assign, sublicense, embed, host, or otherwise transfer the dataset to any third party.
* Right to Request Deletion: At any time, we may require you to delete all copies of the conversation dataset (in whole or in part) in your possession and control. You will promptly comply with any and all such requests. Upon our request, you shall provide us with written confirmation of your compliance with such requirement.
* Termination: We may, at any time, for any reason or for no reason, terminate this Agreement, effective immediately upon notice to you. Upon termination, the license granted to you hereunder will immediately terminate, and you will immediately stop using the LMArena VisionArena dataset and destroy all copies of the LMArena VisionArena dataset and related materials in your possession or control.
* Limitation of Liability: IN NO EVENT WILL WE BE LIABLE FOR ANY CONSEQUENTIAL, INCIDENTAL, EXEMPLARY, PUNITIVE, SPECIAL, OR INDIRECT DAMAGES (INCLUDING DAMAGES FOR LOSS OF PROFITS, BUSINESS INTERRUPTION, OR LOSS OF INFORMATION) ARISING OUT OF OR RELATING TO THIS AGREEMENT OR ITS SUBJECT MATTER, EVEN IF WE HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
* Subject to your compliance with the terms and conditions of this Agreement, we grant to you, a limited, non-exclusive, non-transferable, non-sublicensable license to use the LMArena VisionArena dataset, including the conversation data and annotations, to research, develop, and improve software, algorithms, machine learning models, techniques, and technologies for both research and commercial purposes.

# VisionArena-Battle:3万条带成对偏好投票的真实世界图像对话
从[Chatbot Arena](https://lmarena.ai/)平台收集的20万条用户与视觉语言模型(VLM)的单轮及多轮对话。
**警告:** 数据集中的图像可能包含不当内容。

## 数据集详情
* 20万条对话
* 45款视觉语言模型
* 覆盖138种语言
* 约4.3万张独特图像
* 问题分类标签(图像描述、光学字符识别(OCR)、实体识别、代码生成、作业解答、图表分析、幽默创作、创意写作、拒绝响应)
### 数据集说明
本数据集包含20万条用户与两款匿名视觉语言模型的交互对话,均通过开源平台[Chatbot Arena](https://lmarena.ai/)收集而来。该平台支持用户以直接聊天、并排对比或匿名并排对比的方式与大语言模型(LLM)及视觉语言模型交互。用户可为模型生成的回复提供偏好投票,投票结果通过布拉德利-特里(Bradley-Terry)模型聚合,用于计算[排行榜排名](https://lmarena.ai/?leaderboard)。匿名并排对比聊天的数据集可通过[此链接](https://huggingface.co/datasets/lmarena-ai/VisionArena-Battle)获取。
本数据集涵盖2024年2月至2024年9月期间的对话数据。用户在开始聊天前已明确同意共享其对话内容。我们通过[不适内容识别(NSFW)](https://learn.microsoft.com/en-us/azure/ai-services/content-moderator/image-moderation-api)、[儿童性虐待材料检测(CSAM)](https://www.microsoft.com/en-us/photodna?oneroute=true)、个人可识别信息(PII,含文本)检测工具([1](https://cloud.google.com/vision/docs/detecting-faces), [2](https://github.com/ageitgey/face_recognition))以及人脸检测器,对不当图像、含个人可识别信息的图像/文本以及含人脸的图像进行过滤移除。但上述检测工具并非完美无缺,因此数据集中仍可能存在此类图像。
### 数据集来源
- **代码仓库:** https://github.com/lm-sys/FastChat
- **学术论文:** https://arxiv.org/abs/2412.08687
- **与最新视觉语言模型对话并贡献你的投票!** https://lmarena.ai/
图像以字节格式存储,可通过`Image.open(BytesIO(img["bytes"]))`进行解码。
## 数据集结构
<!-- 本节将对数据集字段进行说明,并补充数据集结构相关信息,如划分数据集的标准、数据点间的关联关系等。 -->
* **model**:模型标识
* **images**:图像(注:仅适用于单图像对话场景)
* **conversation**:与对应模型的对话内容
* **user_id**:基于IP地址生成的用户ID哈希值
* **categories**:分类标签(注:单个问题可归属多个类别)
* **num_turns**:对话轮次数量
* **tstamp**:对话发生的时间戳
* **is_preset**:标识图像是否来自“随机图像按钮”功能
* **dataset_preset**:预设图像所属的源数据集,可选范围包括[NewYorker漫画标题竞赛数据集](https://huggingface.co/datasets/jmhessel/newyorker_caption_contest)、[WikiArt艺术数据集](https://huggingface.co/datasets/huggan/wikiart)、[TextVQA数据集](https://huggingface.co/datasets/facebook/textvqa)、[ChartQA图表问答数据集](https://huggingface.co/datasets/lmms-lab/ChartQA)、[DocQA文档问答数据集](https://huggingface.co/datasets/lmms-lab/DocVQA)以及[realworldqa数据集](https://x.ai/blog/grok-1.5v)
## 偏差、风险与局限性
本数据集包含大量与理工科(STEM)相关的问题、光学字符识别任务以及图像描述等通用型任务。相较于理工科领域,涉及其他专业领域的问题占比较少。
**若您发现数据集中包含您的人脸或个人信息并希望移除,或发现仇恨性或不当内容,** 请通过lmarena.ai@gmail.com或lisabdunlap@berkeley.edu联系我们。详细条款请参阅下文的许可协议。
**BibTeX引用格式:**
@article{chou2024visionarena,
title={VisionArena: 230K Real World User-VLM Conversations with Preference Labels},
author={Christopher Chou and Lisa Dunlap and Koki Mashita and Krishna Mandal and Trevor Darrell and Ion Stoica and Joseph E. Gonzalez and Wei-Lin Chiang},
year={2024},
eprint={2412.08687},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2412.08687},
}
## LMArena VisionArena数据集许可协议
本协议规定了您访问和使用LMArena VisionArena数据集(定义见上文)的条款与条件。若您不接受本协议,则不得使用该数据集。通过点击接受按钮、访问该数据集或同时进行上述两项操作,即视为您同意受本协议约束。若您代表雇主或其他实体签署本协议,则您声明并保证您拥有充分的法定权限可约束该雇主或实体受本协议条款约束;若无该等权限,则您不得代表雇主或其他实体接受本协议或访问该数据集。
* **安全与审核:** 本数据集包含可能被视为冒犯性或令人不适的不安全对话。用户在将该数据集用于训练对话智能体前,应采取适当的过滤与安全措施。
* **非背书声明:** 数据集中呈现的观点与意见并不代表参与数据收集的研究人员或其附属机构的立场。
* **合规要求:** 您必须遵守所有相关法律法规使用本数据集。
* **模型专属条款:** 若使用特定模型的直接输出结果,用户必须遵守该模型对应的使用条款。
* **非识别要求:** 您不得尝试识别数据集中个人的身份,或推断数据集中包含的任何敏感个人信息。
* **禁止转让:** 您不得向任何第三方分发、复制、披露、转让、再许可、嵌入、托管或以其他方式转移本数据集。
* **删除请求权:** 我们可随时要求您删除所有由您持有或控制的该对话数据集的全部或部分副本。您应及时遵守所有此类要求,并应我们的请求提供已遵守该要求的书面确认。
* **协议终止:** 我们可随时以任何理由或无理由终止本协议,通知您后立即生效。协议终止后,您在此获得的许可将立即终止,您应立即停止使用LMArena VisionArena数据集,并销毁所有由您持有或控制的该数据集及相关材料的副本。
* **责任限制:** 即使我们已被告知存在此类损害的可能性,我们也绝不会对因本协议或其标的事项引起或相关的任何间接、附带、惩戒性、惩罚性、特殊性或后果性损害(包括利润损失、业务中断或信息丢失造成的损害)承担责任。
* **许可授予:** 在您遵守本协议条款与条件的前提下,我们授予您有限的、非排他的、不可转让的、不可再许可的许可,允许您为研究和商业目的使用LMArena VisionArena数据集(包括对话数据与标注信息),以研究、开发并改进软件、算法、机器学习模型、技术及相关科技。
提供机构:
maas
创建时间:
2025-04-21
搜集汇总
数据集介绍
背景与挑战
背景概述
VisionArena-Chat数据集包含20万条用户与视觉语言模型的真实对话,涵盖45种模型和138种语言,涉及约4.3万张独特图像,并包含用户偏好投票和问题类别标签。数据集主要用于研究和开发对话代理,但需注意可能包含不适当内容。
以上内容由遇见数据集搜集并总结生成


