K-MMBench
收藏Hugging Face2024-12-05 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/NCSOFT/K-MMBench
下载链接
链接失效反馈官方服务:
资源简介:
K-MMBench 是一个韩语版本的视觉-语言模型评估数据集,专门用于评估模型在韩语环境下的表现。它包含了20个评估维度的问题,如身份推理、图像情感和属性识别,并采用了 MMBench 提出的 CircularEval Strategy 进行公平评估。
创建时间:
2024-11-26
原始信息汇总
K-MMBench 数据集概述
基本信息
- 语言: 韩语 (ko)
- 许可证: CC BY-NC 4.0
数据集结构
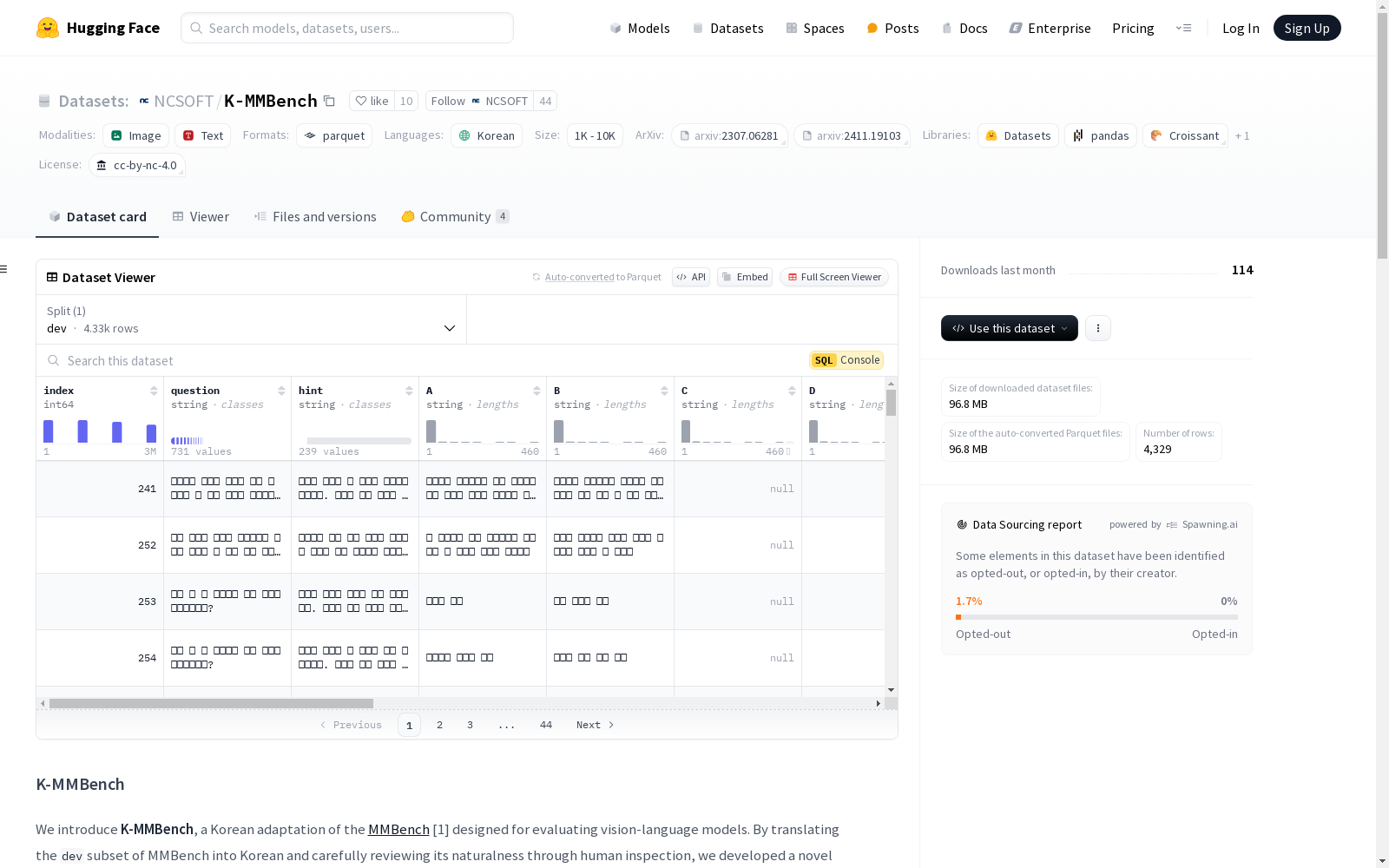
特征
- index: 整数类型 (int64)
- question: 字符串类型 (string)
- hint: 字符串类型 (string)
- A: 字符串类型 (string)
- B: 字符串类型 (string)
- C: 字符串类型 (string)
- D: 字符串类型 (string)
- answer: 字符串类型 (string)
- category: 字符串类型 (string)
- image: 图像类型 (image)
- source: 字符串类型 (string)
- l2-category: 字符串类型 (string)
- comment: 字符串类型 (string)
- split: 字符串类型 (string)
数据分割
- dev: 包含 4329 个样本,大小为 103023727.794 字节
文件信息
- 下载大小: 96835472 字节
- 数据集大小: 103023727.794 字节
配置
- config_name: default
- data_files:
- split: dev
- path: data/dev-*
- data_files:
数据集描述
K-MMBench 是 MMBench 的韩语改编版本,专门用于评估视觉-语言模型。该数据集通过将 MMBench 的 dev 子集翻译成韩语,并通过人工检查确保其自然性,从而开发出一个针对韩语的鲁棒评估基准。K-MMBench 包含跨越 20 个评估维度的问答,如身份推理、图像情感和属性识别,允许对模型在韩语中的表现进行全面评估。
评估策略
采用 MMBench 基准提出的 CircularEval Strategy 进行公平评估。
引用
如果使用 K-MMBench 进行研究,请引用以下内容: bibtex @misc{ju2024varcovisionexpandingfrontierskorean, title={VARCO-VISION: Expanding Frontiers in Korean Vision-Language Models}, author={Jeongho Ju and Daeyoung Kim and SunYoung Park and Youngjune Kim}, year={2024}, eprint={2411.19103}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2411.19103}, }
搜集汇总
数据集介绍
构建方式
K-MMBench数据集的构建基于对MMBench数据集的韩语翻译与适应性调整。具体而言,研究团队将MMBench的dev子集翻译成韩语,并通过人工审查确保翻译的自然性与准确性。该数据集涵盖了20个评估维度,如身份推理、图像情感分析和属性识别等,旨在全面评估视觉-语言模型在韩语环境中的表现。为确保评估的公平性与一致性,K-MMBench采用了MMBench提出的循环评估策略(CircularEval Strategy),进一步提升了数据集的鲁棒性与可靠性。
使用方法
K-MMBench数据集适用于评估视觉-语言模型在韩语环境中的表现,尤其适用于多模态模型的性能测试。用户可以通过提供的推理提示模板,输入图像、提示信息和问题,模型将根据选项直接输出答案。数据集的评估结果可用于比较不同模型的性能,帮助研究者优化和改进模型设计。此外,K-MMBench的循环评估策略确保了评估过程的公平性与一致性,使得结果更具参考价值。
背景与挑战
背景概述
K-MMBench数据集是基于MMBench的多模态评估基准的韩语适配版本,由VARCO-VISION团队开发,旨在评估视觉-语言模型在韩语环境下的性能。该数据集通过对MMBench的dev子集进行韩语翻译,并通过人工审查确保其自然性,从而构建了一个专门针对韩语的鲁棒评估基准。K-MMBench涵盖了20个评估维度,如身份推理、图像情感和属性识别等,能够全面评估模型在韩语中的表现。该数据集的开发不仅推动了韩语视觉-语言模型的研究,还为多模态模型的跨语言评估提供了新的视角。
当前挑战
K-MMBench数据集在构建过程中面临的主要挑战包括:首先,如何确保韩语翻译的准确性和自然性,以避免翻译误差对模型评估结果的影响;其次,如何在多模态任务中保持评估的公平性和一致性,特别是在采用MMBench提出的CircularEval策略时。此外,该数据集还需要应对多模态模型在不同语言环境下的性能差异,以及如何通过评估维度设计来全面捕捉模型的多方面能力。这些挑战不仅涉及技术层面的优化,还要求对语言特性和文化背景有深入的理解。
常用场景
经典使用场景
K-MMBench数据集的经典使用场景主要集中在视觉-语言模型的评估上。通过提供多维度的问题,如身份推理、图像情感分析和属性识别等,该数据集能够全面评估模型在韩语环境下的表现。研究者可以利用K-MMBench对模型进行细致的性能测试,确保其在多种任务中的鲁棒性和准确性。
解决学术问题
K-MMBench数据集解决了视觉-语言模型在韩语环境下的评估难题。传统的评估基准往往忽视了语言的多样性,而K-MMBench通过引入韩语翻译和人工校验,确保了评估的自然性和准确性。这不仅推动了韩语视觉-语言模型的研究,也为多语言模型的跨文化评估提供了新的思路。
实际应用
在实际应用中,K-MMBench数据集可用于开发和优化面向韩语用户的视觉-语言模型。例如,在教育领域,该数据集可以帮助构建智能辅导系统,通过图像和文本的结合提供更丰富的学习体验。此外,在医疗、零售等行业,该数据集也能用于开发基于视觉和语言的多模态应用,提升用户体验和服务质量。
数据集最近研究
最新研究方向
K-MMBench数据集的最新研究方向主要集中在视觉-语言模型的评估与优化上。该数据集通过将MMBench的开发集翻译为韩语,并采用CircularEval策略,为韩国语言的视觉-语言模型提供了一个全面的评估基准。研究者们致力于通过K-MMBench对模型在多维度任务中的表现进行细致分析,如身份推理、图像情感和属性识别等,从而推动韩国视觉-语言模型在实际应用中的性能提升。此外,K-MMBench的引入也为跨语言视觉-语言模型的比较研究提供了新的视角,进一步促进了多模态学习领域的发展。
以上内容由遇见数据集搜集并总结生成


