naidu1999/tourism-data
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/naidu1999/tourism-data
下载链接
链接失效反馈官方服务:
资源简介:
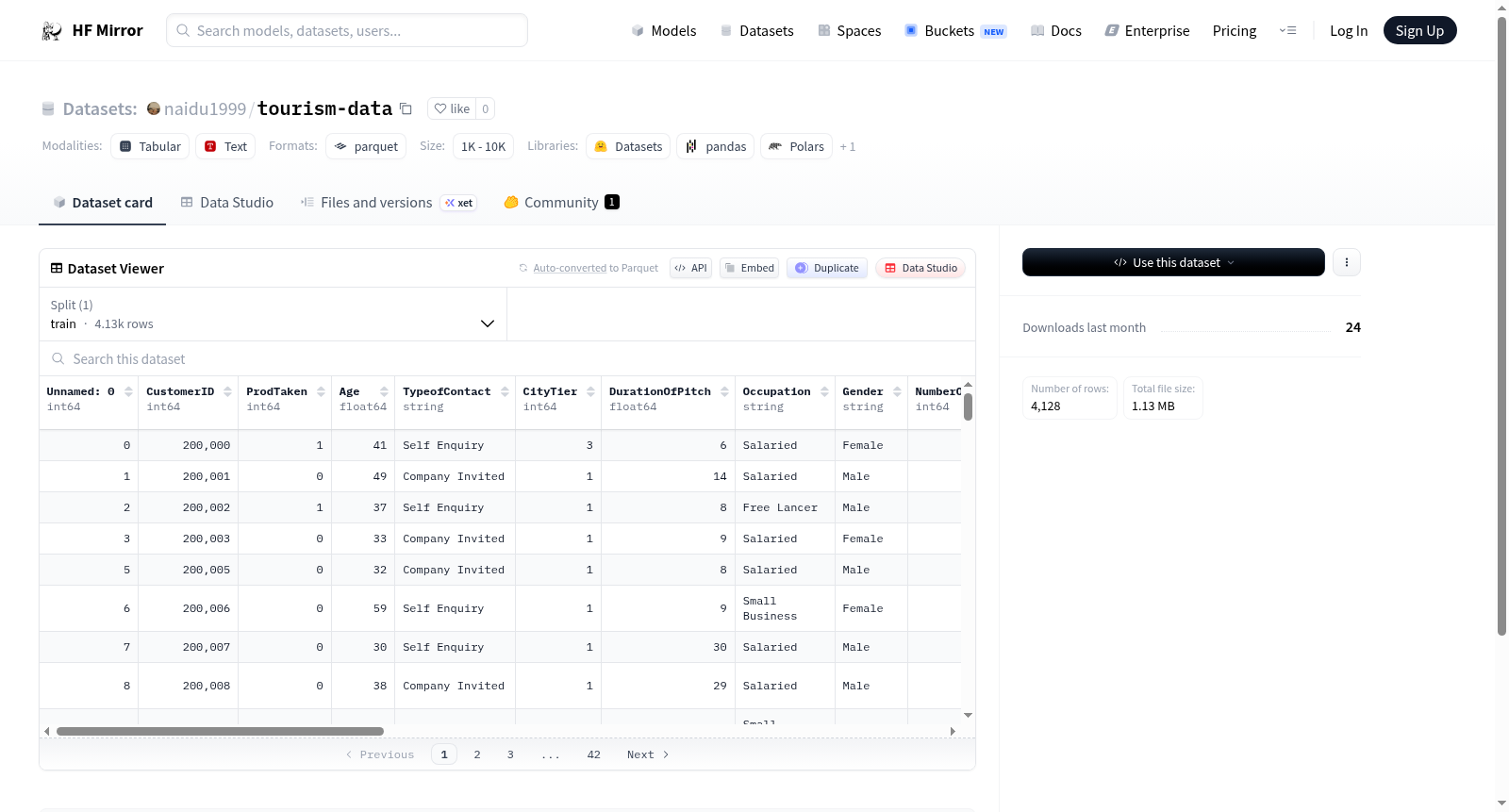
该数据集是一个旅游产品推销相关的客户数据集,包含4128个训练样本。特征涉及客户基本信息(如CustomerID、Age、Gender、MaritalStatus、Occupation、Designation、MonthlyIncome、CityTier、OwnCar、Passport)、旅游行为(如ProdTaken、TypeofContact、DurationOfPitch、ProductPitched、PreferredPropertyStar、NumberOfPersonVisiting、NumberOfFollowups、NumberOfTrips、NumberOfChildrenVisiting、PitchSatisfactionScore)等。数据集用于分析客户是否接受旅游产品推销(ProdTaken),可能支持分类或预测任务。
This dataset is a customer dataset related to tourism product promotion, containing 4128 training samples. The features include basic customer information (such as CustomerID, Age, Gender, MaritalStatus, Occupation, Designation, MonthlyIncome, CityTier, OwnCar, Passport) and tourism behaviors (such as ProdTaken, TypeofContact, DurationOfPitch, ProductPitched, PreferredPropertyStar, NumberOfPersonVisiting, NumberOfFollowups, NumberOfTrips, NumberOfChildrenVisiting, PitchSatisfactionScore). The dataset is used to analyze whether customers accept tourism product promotions (ProdTaken), potentially supporting classification or prediction tasks.
提供机构:
naidu1999
搜集汇总
数据集介绍
构建方式
旅游业作为全球经济的重要组成部分,其数据驱动决策日益受到重视。本数据集由包含4888个样本的单一训练集构成,涵盖21个特征字段,融合了客户基本信息、旅行偏好与行为记录。构建时整合了数值型变量(如年龄、月收入、跟进次数)与类别型变量(如职业、婚姻状况、联系方式类型),通过清洗与标准化处理,形成面向旅游产品购买预测的结构化数据体系。
特点
该数据集以客户为核心视角,汇聚了多元化的旅游行为指标,包括销售额状态、飞行演示时长、产品满意度评分、携带儿童数量等细粒度信息。值得注意的是,数据中包含了是否持有护照、是否拥有私家车等反映客户出行条件的特征,配合星级偏好与旅行次数等行为数据,为建模提供了丰富的维度支持,尤其适合分类与回归两类机器学习任务。
使用方法
使用者可通过HuggingFace Datasets库直接加载默认配置下的训练分割数据,利用Python的`load_dataset`函数快速获取结构化样本。数据适用于构建客户购买意向预测模型,可借助`ProdTaken`列作为标签进行监督学习任务。建议对`MonthlyIncome`、`NumberOfTrips`等含缺失值的数值特征进行插补,并对`TypeofContact`、`Occupation`等类别特征执行独热编码或标签编码,以适配不同算法需求。
背景与挑战
背景概述
旅游数据挖掘与分析是旅游管理领域的重要研究方向,尤其在个性化推荐与客户转化预测中具有关键作用。tourism-data数据集由相关研究机构创建,专注于记录客户旅游产品的购买行为与个人特征,核心研究问题包括通过消费者的年龄、职业、婚姻状况、月收入等属性,以及推销沟通次数、满意度评分等交互特征,预测其是否接受旅游产品。该数据集包含4128条训练样本,涵盖20个特征维度,为旅游营销中的客户分群与精准推荐提供了基础数据支撑,在旅游行为建模与营销策略优化领域具有显著影响力。
当前挑战
该数据集所解决的领域问题在于,旅游产品购买决策受多因素复杂交互影响,传统统计学方法难以捕捉非线性关联,同时数据呈现类别不平衡与高维稀疏特征,例如拥有护照的客户比例偏低,部分连续变量如年龄与月收入分布偏斜。构建过程中面临数据完整性的挑战,多项指标如推销时长、月收入存在缺失值,且消费意愿标签依赖历史记录而非实时行为,可能导致模型泛化能力受限。此外,特征工程中如何有效编码文本型字段如职业与职位,并平衡数值型与类别型变量的尺度差异,亦是实际建模中的关键难点。
常用场景
经典使用场景
在旅游与酒店管理领域,精准识别潜在客户并预测其购买意向一直是营销决策的核心挑战。tourism-data数据集包含客户的人口统计信息、旅行偏好、销售交互细节及产品采纳情况,为构建客户购买倾向预测模型提供了理想的数据基础。该数据集最经典的使用场景是基于监督学习算法(如逻辑回归、随机森林或梯度提升树)训练分类模型,以预测客户是否会购买旅游产品(ProdTaken),从而支持企业优化营销资源分配。
实际应用
在实际业务中,tourism-data数据集可助力旅游企业构建智能化的客户分层与推荐系统。例如,旅行社可基于模型预测结果,优先向高购买倾向的客户推送个性化旅游套餐,或针对低倾向客户设计激励方案(如折扣或附加服务)。此外,该数据集还可用于优化销售团队跟进策略,通过分析跟进次数与购买率的关系,合理分配客服精力,从而在降低成本的同时提升转化率。
衍生相关工作
tourism-data数据集衍生出了诸多经典研究工作,包括基于特征重要性分析的客户细分研究、利用集成学习方法提升预测鲁棒性的对比实验,以及结合神经网络探索特征非线性交互作用的探索性工作。此外,该数据集常被用于验证不平衡分类技术在营销数据中的有效性,并推动了解释性AI(如SHAP值分析)在旅游推荐场景中的应用,为学术与工业界的交叉创新提供了持续动力。
以上内容由遇见数据集搜集并总结生成


