有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
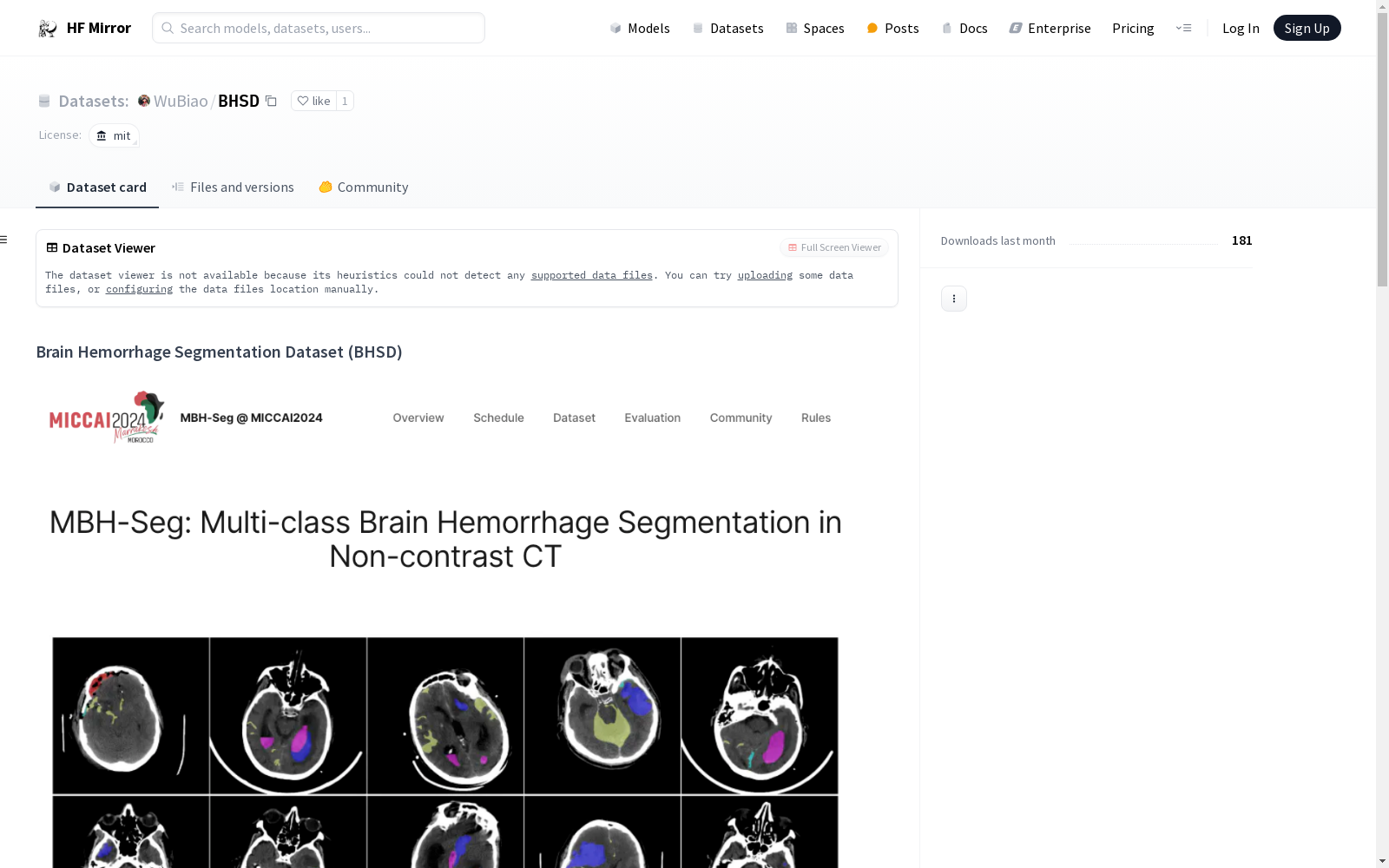
Brain Hemorrhage Segmentation Dataset (BHSD) 是一个用于颅内出血(ICH)的3D多类分割数据集。颅内出血是一种病理状况,其特点是颅骨或脑内出血,可能由多种因素引起。准确识别、定位和量化ICH对于临床诊断和治疗至关重要。我们的数据集包含192个带有像素级标注的体积和1980个未标注的体积,涵盖五类ICH。
该数据集包括以下两个压缩文件:
该数据集主要用于支持深度学习技术在医学图像分割任务中的应用,特别是多类颅内出血分割。它可用于监督和半监督的ICH分割任务,并提供了最先进模型的实验结果作为参考基准。
所有体积数据均存储在常用的医学影像格式中(如DICOM、NIFTI)。
该数据集现已公开可用,并正在最新的MICCAI竞赛中使用。有兴趣使用该数据集的研究人员可以下载并必须遵守相关的使用条款和版权信息。
该数据集受版权法保护。请在使用前确保遵守相关许可条款。
如需更多信息或申请访问数据集,请联系我们:
中国劳动力动态调查
“中国劳动力动态调查” (China Labor-force Dynamics Survey,简称 CLDS)是“985”三期“中山大学社会科学特色数据库建设”专项内容,CLDS的目的是通过对中国城乡以村/居为追踪范围的家庭、劳动力个体开展每两年一次的动态追踪调查,系统地监测村/居社区的社会结构和家庭、劳动力个体的变化与相互影响,建立劳动力、家庭和社区三个层次上的追踪数据库,从而为进行实证导向的高质量的理论研究和政策研究提供基础数据。
中国学术调查数据资料库 收录
OpenSonarDatasets
OpenSonarDatasets是一个致力于整合开放源代码声纳数据集的仓库,旨在为水下研究和开发提供便利。该仓库鼓励研究人员扩展当前的数据集集合,以增加开放源代码声纳数据集的可见性,并提供一个更容易查找和比较数据集的方式。
github 收录
BatteryLife
BatteryLife数据集是由香港科技大学(广州)等机构提出的一个全面电池寿命预测数据集。该数据集整合了16个数据集,包含超过90,000个样本,是迄今为止最大的电池寿命数据集。它提供了包括锂离子、锌离子和钠离子电池在内的多种类型电池,覆盖了8种格式、80种化学系统、12种操作温度和646种充放电协议,具有前所未有的多样性。该数据集既包括实验室测试数据,也包括工业测试数据,为电池寿命预测研究提供了丰富的资源。
arXiv 收录
HazyDet
HazyDet是由解放军工程大学等机构创建的一个大规模数据集,专门用于雾霾场景下的无人机视角物体检测。该数据集包含383,000个真实世界实例,收集自自然雾霾环境和正常场景中人工添加的雾霾效果,以模拟恶劣天气条件。数据集的创建过程结合了深度估计和大气散射模型,确保了数据的真实性和多样性。HazyDet主要应用于无人机在恶劣天气条件下的物体检测,旨在提高无人机在复杂环境中的感知能力。
arXiv 收录
CODrone
CODrone 是一个为无人机设计的全面定向目标检测数据集,它准确反映了真实世界条件。该数据集包含来自多个城市在不同光照条件下的广泛标注图像,增强了基准的逼真度。CODrone 包含超过 10,000 张高分辨率图像,捕获自五个城市的真实无人机飞行,涵盖了各种城市和工业环境,包括港口和码头。为了提高鲁棒性和泛化能力,它包括在正常光线、低光和夜间条件下相同场景的图像。我们采用了三种飞行高度和两种常用的相机角度,从而产生了六个不同的视角配置。所有图像都针对 12 个常见对象类别进行了定向边界框标注,总计超过 590,000 个标记实例。总体而言,这项工作构建了一个综合数据集和基准,用于城市无人机场景中的定向目标检测,旨在满足该领域的研究和实践应用需求。
arXiv 收录