facebook/xnli
收藏Hugging Face2024-01-05 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/facebook/xnli
下载链接
链接失效反馈官方服务:
资源简介:
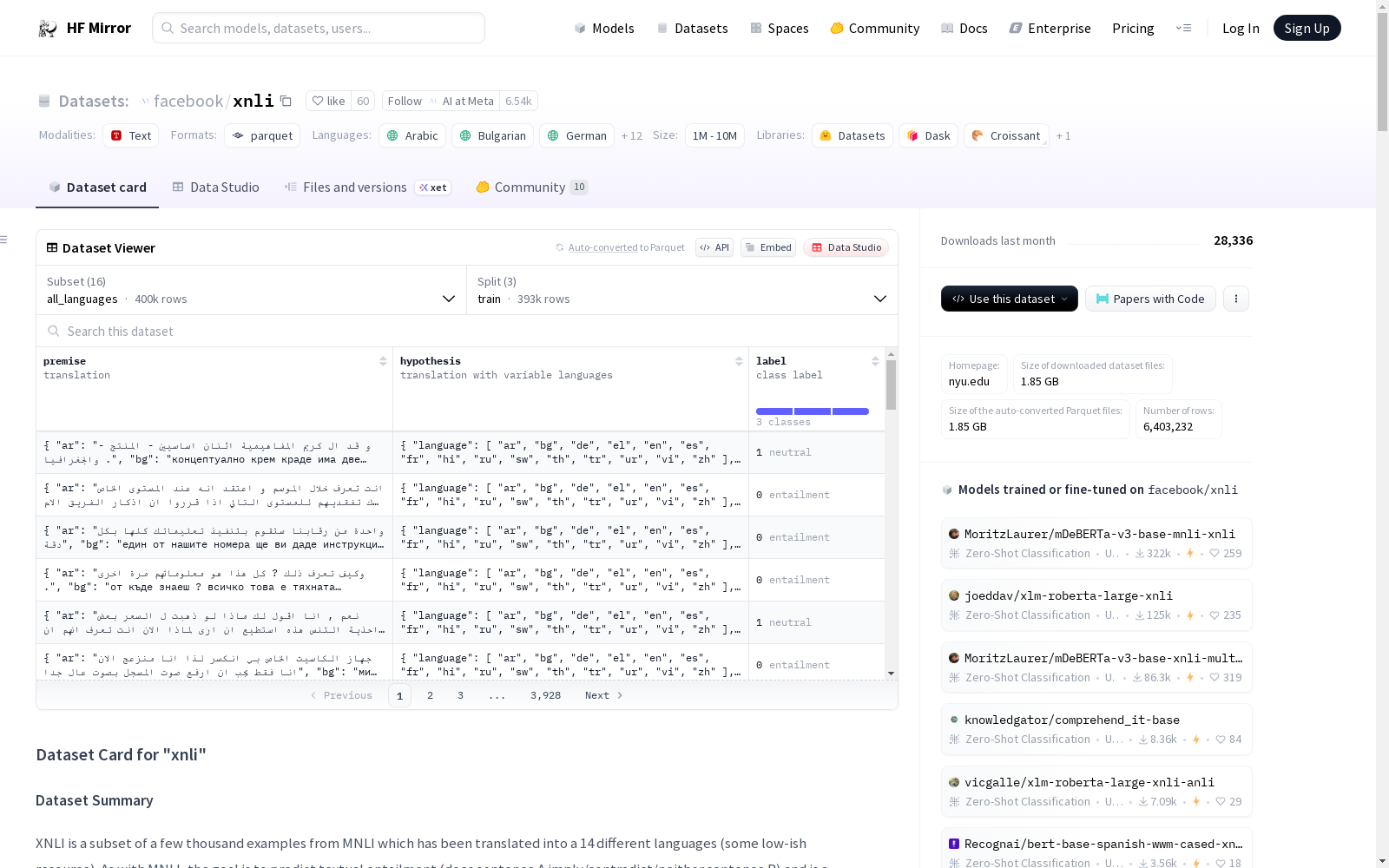
XNLI数据集是MNLI数据集的一个子集,包含数千个例子,已被翻译成14种不同的语言(包括一些资源较少的语言)。与MNLI一样,目标是预测文本蕴含关系(句子A是否蕴含/矛盾/中立于句子B),这是一个分类任务(给定两个句子,预测三个标签之一)。数据集支持15种语言,包括阿拉伯语、保加利亚语、德语、希腊语、英语、西班牙语、法语、印地语、俄语、斯瓦希里语、泰语、土耳其语、乌尔都语、越南语和中文。
The XNLI dataset is a subset of the MNLI dataset, containing thousands of examples translated into 14 distinct languages, including some low-resource languages. Similar to MNLI, its objective is to predict textual entailment (whether Sentence A entails, contradicts, or is neutral towards Sentence B), which is a classification task where given two sentences, one of three labels is predicted. The dataset supports 15 languages in total, including Arabic, Bulgarian, German, Greek, English, Spanish, French, Hindi, Russian, Swahili, Thai, Turkish, Urdu, Vietnamese, and Chinese.
提供机构:
facebook
原始信息汇总
数据集概述
数据集描述
语言
- 支持的语言包括:阿拉伯语(ar)、保加利亚语(bg)、德语(de)、希腊语(el)、英语(en)、西班牙语(es)、法语(fr)、印地语(hi)、俄语(ru)、斯瓦希里语(sw)、泰语(th)、土耳其语(tr)、乌尔都语(ur)、越南语(vi)、中文(zh)。
数据集信息
-
配置名称:all_languages
- 特征:
- premise:多语言字符串变量,支持的语言包括:阿拉伯语、保加利亚语、德语、希腊语、英语、西班牙语、法语、印地语、俄语、斯瓦希里语、泰语、土耳其语、乌尔都语、越南语、中文。
- hypothesis:多语言字符串变量,支持的语言包括:阿拉伯语、保加利亚语、德语、希腊语、英语、西班牙语、法语、印地语、俄语、斯瓦希里语、泰语、土耳其语、乌尔都语、越南语、中文。
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)。
- 分割:
- train:392702个样本,1581471691字节
- test:5010个样本,19387432字节
- validation:2490个样本,9566179字节
- 下载大小:963942271字节
- 数据集大小:1610425302字节
- 特征:
-
配置名称:ar
- 特征:
- premise:字符串
- hypothesis:字符串
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)。
- 分割:
- train:392702个样本,107399614字节
- test:5010个样本,1294553字节
- validation:2490个样本,633001字节
- 下载大小:59215902字节
- 数据集大小:109327168字节
- 特征:
-
配置名称:bg
- 特征:
- premise:字符串
- hypothesis:字符串
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)。
- 分割:
- train:392702个样本,125973225字节
- test:5010个样本,1573034字节
- validation:2490个样本,774061字节
- 下载大小:66117878字节
- 数据集大小:128320320字节
- 特征:
-
配置名称:de
- 特征:
- premise:字符串
- hypothesis:字符串
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)。
- 分割:
- train:392702个样本,84684140字节
- test:5010个样本,996488字节
- validation:2490个样本,494604字节
- 下载大小:55973883字节
- 数据集大小:86175232字节
- 特征:
-
配置名称:el
- 特征:
- premise:字符串
- hypothesis:字符串
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)。
- 分割:
- train:392702个样本,139753358字节
- test:5010个样本,1704785字节
- validation:2490个样本,841226字节
- 下载大小:74551247字节
- 数据集大小:142299369字节
- 特征:
数据字段
-
all_languages:
- premise:多语言字符串变量
- hypothesis:多语言字符串变量
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)
-
ar:
- premise:字符串
- hypothesis:字符串
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)
-
bg:
- premise:字符串
- hypothesis:字符串
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)
-
de:
- premise:字符串
- hypothesis:字符串
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)
-
el:
- premise:字符串
- hypothesis:字符串
- label:分类标签,可能的值包括:entailment(0)、neutral(1)、contradiction(2)
数据分割
| 名称 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| all_languages | 392702 | 2490 | 5010 |
| ar | 392702 | 2490 | 5010 |
| bg | 392702 | 2490 | 5010 |
| de | 392702 | 2490 | 5010 |
| el | 392702 | 2490 | 5010 |
搜集汇总
数据集介绍
构建方式
该数据集的构建方式主要是从MNLI数据集中选取了一部分例子,并将其翻译成了14种不同的语言,涵盖了阿拉伯语、保加利亚语、德语、希腊语、英语、西班牙语、法语、希伯来语、俄语、斯瓦希里语、泰语、土耳其语、乌尔都语、越南语和中文。这些例子被用于预测文本蕴含关系,即判断句子A是否蕴含、矛盾或与句子B无关。数据集包含了前提、假设和标签三个字段,其中标签字段包含了三种可能值:蕴含、无关和中立。
特点
该数据集的特点在于其跨语言性,可以用于评估跨语言句子表示的能力。数据集包含了多种语言的例子,为研究者提供了在不同语言环境下进行文本蕴含关系预测的机会。此外,数据集的构建方式也具有一定的代表性,涵盖了多种语言和文化背景,有助于研究者更好地理解不同语言之间的蕴含关系。
使用方法
使用该数据集时,首先需要下载并解压数据集文件。然后,可以按照数据集的结构进行数据的读取和预处理。数据集包含了前提、假设和标签三个字段,其中前提和假设字段包含了不同语言的翻译版本,标签字段包含了三种可能值:蕴含、无关和中立。在处理数据时,可以根据需要选择使用全部语言或特定语言的例子。此外,数据集还包含了训练集、验证集和测试集,可以用于模型的训练、验证和测试。
背景与挑战
背景概述
在自然语言处理领域,跨语言自然语言推理(Cross-lingual Natural Language Inference,简称XNLI)是一个重要的研究方向。XNLI数据集由Facebook AI Research(FAIR)团队创建,旨在评估跨语言句子表示的有效性。该数据集基于MNLI数据集的数千个示例,并将其翻译成14种不同的语言,包括阿拉伯语、保加利亚语、德语、希腊语、英语、西班牙语、法语、印地语、俄语、斯瓦希里语、泰语、土耳其语、乌尔都语、越南语和中文。XNLI数据集的主要研究人员包括Alexis Conneau、Ruty Rinott、Guillaume Lample、Adina Williams、Samuel R. Bowman、Holger Schwenk和Veselin Stoyanov。XNLI数据集的核心研究问题是预测文本蕴含关系,即判断句子A是否蕴含、矛盾或与句子B无关。XNLI数据集对相关领域的影响力主要体现在提供了跨语言自然语言推理的基准数据集,推动了跨语言句子表示和自然语言推理技术的发展。
当前挑战
XNLI数据集面临的挑战主要包括:1) 所解决的领域问题,即跨语言自然语言推理的挑战。跨语言自然语言推理需要处理不同语言之间的语义差异和文化背景差异,对模型的泛化能力提出了更高的要求。2) 构建过程中所遇到的挑战。XNLI数据集需要将MNLI数据集中的示例翻译成多种语言,翻译质量对数据集的质量和有效性有重要影响。此外,数据集的标注过程也需要考虑不同语言的特点和差异,确保标注的准确性和一致性。
常用场景
经典使用场景
在自然语言处理领域,facebook/xnli数据集被广泛应用于评估跨语言句子表示模型。它包含了从MNLI数据集中抽取的数千个示例,并被翻译成了14种不同的语言,旨在预测文本蕴含关系,即判断句子A是否蕴含、矛盾或与句子B无关。此数据集的经典使用场景包括跨语言的自然语言推理模型训练和评估,以及研究语言模型在不同语言环境下的表现。
实际应用
facebook/xnli数据集在实际应用中具有广泛的前景。例如,在机器翻译、信息检索、文本摘要等领域,跨语言自然语言处理技术发挥着重要作用。facebook/xnli数据集可以帮助研究人员开发出更准确的跨语言句子蕴含关系预测模型,从而提高这些应用领域的性能。此外,该数据集还可以用于开发多语言问答系统、跨语言推荐系统等,为用户提供更便捷的语言交流服务。
衍生相关工作
facebook/xnli数据集的发布推动了跨语言自然语言处理领域的研究,并衍生出一系列相关的工作。例如,一些研究利用facebook/xnli数据集评估和比较了不同跨语言句子表示模型,探索了不同模型在不同语言环境下的表现。此外,还有一些研究利用facebook/xnli数据集开发出了新的跨语言句子蕴含关系预测模型,为跨语言自然语言处理技术提供了新的思路和方法。这些相关工作的开展,有助于推动跨语言自然语言处理技术的发展,并为相关领域的应用提供更准确、高效的模型支持。
以上内容由遇见数据集搜集并总结生成


