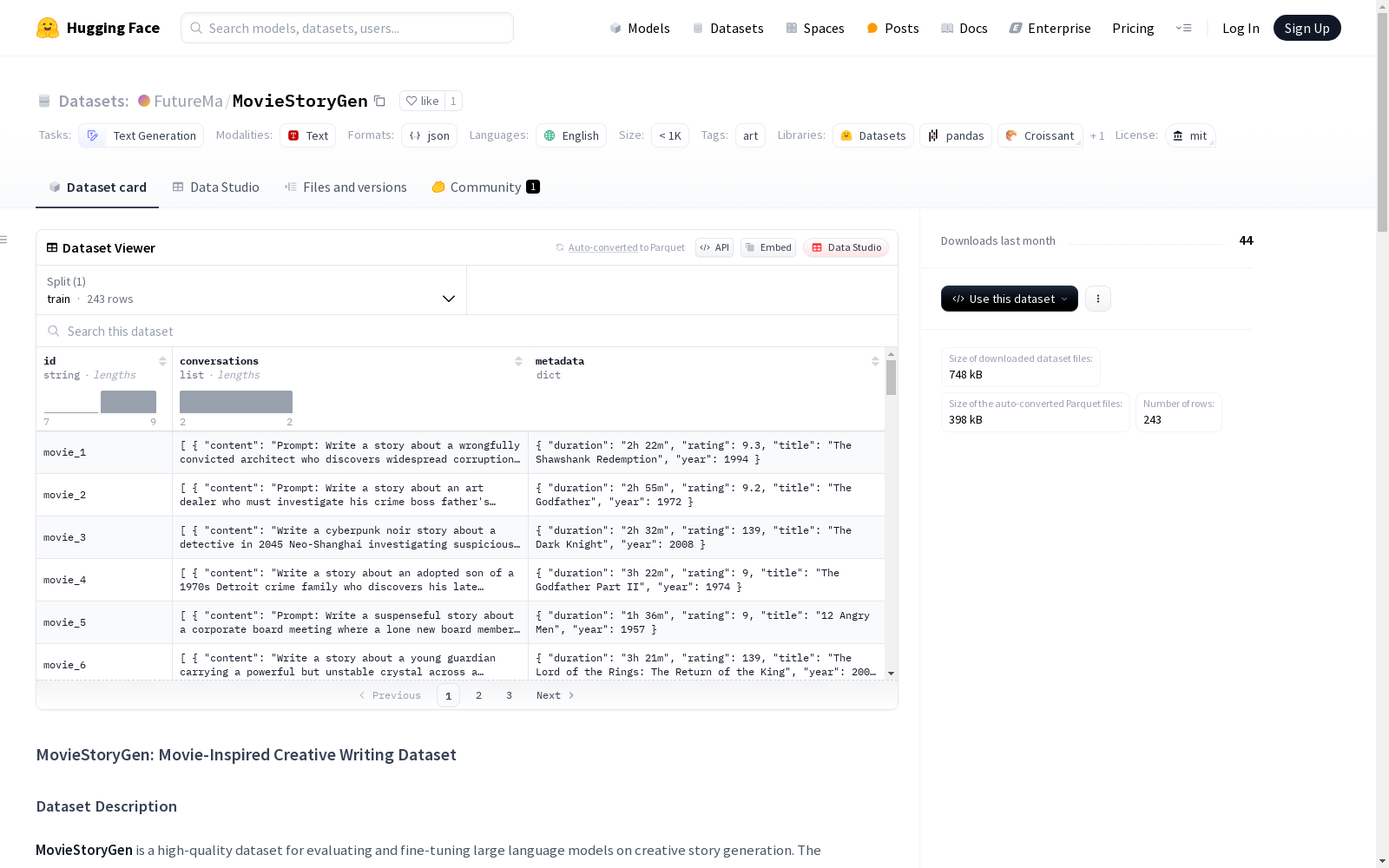
MovieStoryGen
收藏MovieStoryGen: 电影启发的创意写作数据集
数据集描述
- 名称: MovieStoryGen
- 用途: 评估和微调大型语言模型在创意故事生成方面的能力
- 内容: 包含结构化写作提示与详细故事响应的配对,灵感来自IMDb Top 250电影
- 特点: 每个条目包含创意写作提示和相应精心制作的故事,将经典电影精髓重新构想于新背景中
数据集结构
- 人类提示: 结构化创意写作提示,捕捉著名电影的精髓
- 助手响应: 丰富的创意故事,展示语言模型如何构建引人入胜的叙事
- 元数据: 包括原始电影标题、年份、IMDb评分和时长
使用场景
- 评估大型语言模型的创意讲故事能力
- 微调模型以提高叙事连贯性、情节发展和创意写作
- 跨不同模型的故事生成能力基准测试
- 创意任务提示工程研究
- 探索模型如何将电影主题转化为书面叙事
数据集创建
- 提示精心设计以捕捉IMDb高评分电影的核心主题和情节元素
- 响应代表高质量创意故事,展示:
- 清晰的叙事弧线
- 复杂的角色发展
- 主题深度
- 情节转折和叙事张力
- 对熟悉故事的创意重构
示例条目
提示:
Write a story about a wrongfully convicted architect who discovers widespread corruption in a state prison while helping the elderly prison librarian digitize old records, leading to both their redemptions.
响应:
"The Echo of Innocence"
Thomas Chen, a brilliant architect, is sentenced to 25 years in Blackwater State Penitentiary for allegedly murdering his business partner. Despite maintaining his innocence, all evidence points to him, including security footage showing him leaving his partners office the night of the murder.
[... full story ...]
元数据:
"title": "The Shawshank Redemption", "year": 1994, "rating": 9.3, "duration": "2h 22m"
引用与致谢
bibtex @misc{moviestorygen2025, author = {Shijian}, title = {MovieStoryGen: Movie-Inspired Creative Writing Dataset}, year = {2025}, howpublished = {Hugging Face Dataset}, url = {https://huggingface.co/datasets/FutureMa/MovieStoryGen} }
加载数据集
python from datasets import load_dataset
dataset = load_dataset("FutureMa/MovieStoryGen")
Access the first example
example = dataset["train"][0] prompt = example["conversations"][0]["content"] story = example["conversations"][1]["content"] metadata = example["metadata"]
print(f"Prompt: {prompt[:100]}...") print(f"Story begins with: {story[:100]}...") print(f"Based on: {metadata[title]} ({metadata[year]})")
基本信息
- 许可证: MIT
- 任务类别: 文本生成
- 语言: 英语
- 标签: 艺术