russian_assistant_to_serbian
收藏Hugging Face2026-02-12 更新2026-02-13 收录
下载链接:
https://huggingface.co/datasets/mkrstic8/russian_assistant_to_serbian
下载链接
链接失效反馈官方服务:
资源简介:
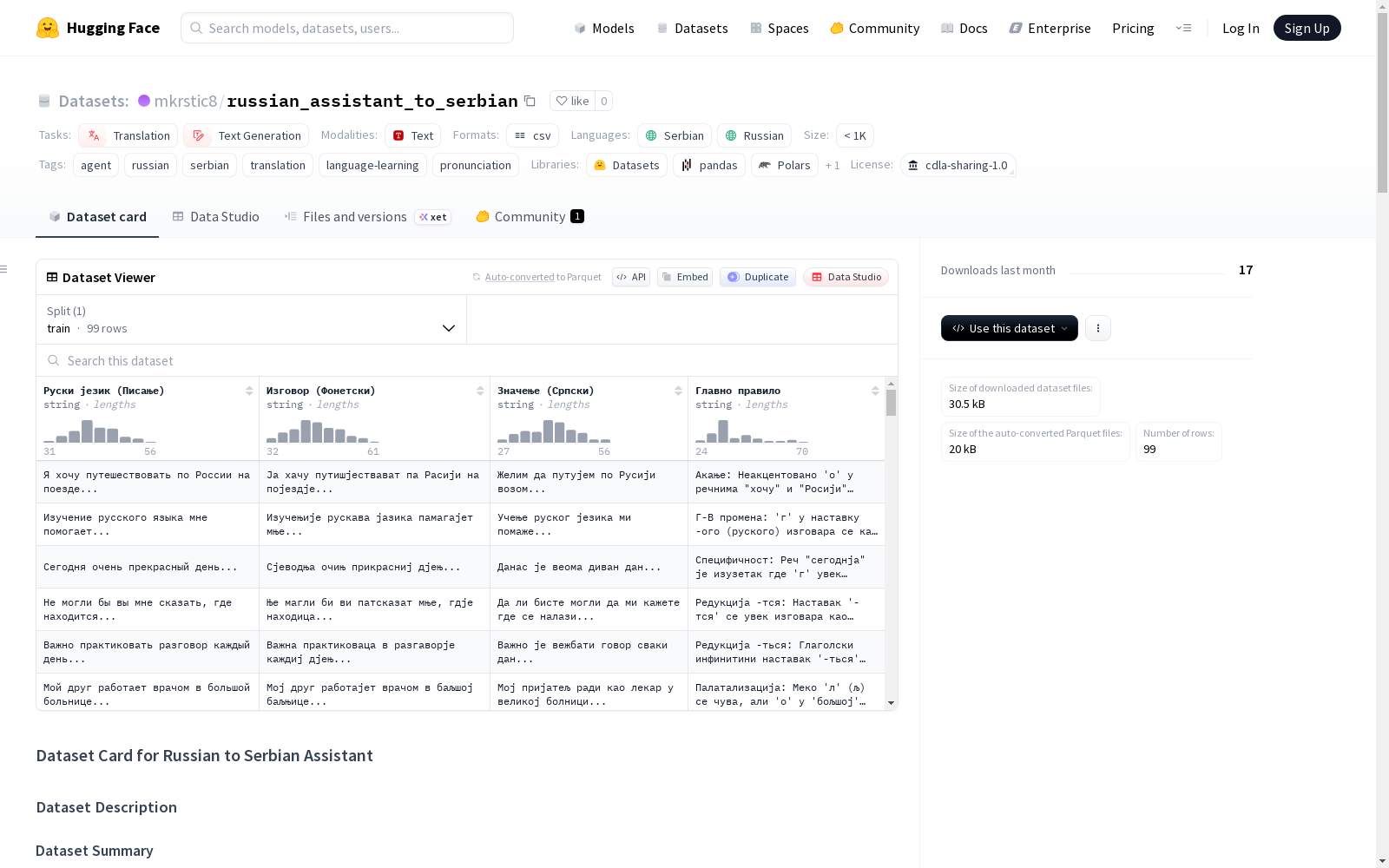
俄语到塞尔维亚语助手数据集是一个教育性数据集,旨在帮助塞尔维亚语使用者学习俄语。该数据集包含俄语短语及其针对塞尔维亚语优化的音标转写、塞尔维亚语翻译以及详细的发音语法规则。数据集采用西里尔字母,涵盖俄语(ru)和塞尔维亚语(sr)两种语言。每个数据实例包含四个字段:俄语原文(russian_original)、塞尔维亚语音标转写(quasi_russian_serbian)、塞尔维亚语翻译(serbian_meaning)以及发音规则说明(pronunciation_rules)。目前数据集规模小于1000个样本,未划分训练/验证/测试集。该数据集特别适合用于:1) 俄语学习辅助工具开发;2) 语音转换AI助手训练;3) 生成发音练习材料;4) 教育类聊天机器人开发。数据集采用CDLA-Sharing 1.0协议许可,主要优势在于为塞尔维亚学习者提供了俄语发音的系统性指导,但需注意其样本量有限且主要针对塞尔维亚语使用者的局限性。
创建时间:
2026-02-08
原始信息汇总
数据集概述:Russian to Serbian Assistant
数据集简介
Russian to Serbian Assistant 是一个面向学习俄语的塞尔维亚语使用者的教育数据集。该数据集包含俄语短语及其适配塞尔维亚语发音的语音转写、塞尔维亚语翻译,以及详细的发音语法规则。
支持的任务
- 俄语学习:帮助塞尔维亚语使用者掌握俄语。
- 语音转写:将俄语文本转换为塞尔维亚语语音转写。
- 语法规则生成:创建俄语单词的发音规则。
- 语言学习AI助手:训练用于辅助俄语学习的聊天助手。
语言
数据集包含以下语言:
- 俄语 (ru) - 西里尔字母
- 塞尔维亚语 (sr) - 西里尔字母
数据集结构
数据实例示例
一个数据样本示例如下: json { "russian_original": "Я хочу путешествовать по России на поезде...", "quasi_russian_serbian": "Ја хачу путишјествават па Расији на појездје...", "serbian_meaning": "Желим да путујем по Русији возом...", "pronunciation_rules": "Акање: Неакцентовано о у речнима "хочу" и "Росији" прелази у а." }
数据字段
russian_original: 俄语原始短语或单词(西里尔字母),字符串类型。quasi_russian_serbian: 使用塞尔维亚语字母和语音的俄语文本语音转写,字符串类型。serbian_meaning: 塞尔维亚语翻译及含义,字符串类型。pronunciation_rules: 详细的塞尔维亚语发音语法规则,包括重音、软/辅音及语音细微差别,字符串类型。
数据划分
数据集目前包含少于1000个示例,未划分为训练集/验证集/测试集。
数据集创建
创建缘由
创建此数据集旨在:
- 帮助塞尔维亚语使用者学习俄语。
- 提供清晰、结构化的俄语单词发音规则。
- 支持训练专门用于俄语教学的AI助手。
- 弥合同源斯拉夫语言之间的语言差异。
数据来源
初始数据收集
数据集包含塞尔维亚语使用者学习俄语时常用的相关俄语短语、表达和词汇。
标注
每个条目包含:
- 原始俄语单词/短语
- 适配塞尔维亚语语音的语音转写
- 准确的翻译及使用语境
- 详细的语音和语法指南
个人与敏感信息
数据集不包含个人或敏感信息。
使用考量
社会影响
数据集有潜力:
- 为塞尔维亚语使用者简化俄语学习过程。
- 减少两个斯拉夫民族之间的语言障碍。
- 支持教育AI工具的开发。
- 保护斯拉夫语言之间的语言学联系。
偏见与局限
- 示例数量有限(< 1K)。
- 专注于塞尔维亚语使用者(对其他学习者可能用处较小)。
- 语音转写可能因塞尔维亚语方言而异。
- 建议:作为标准俄语课程之外的辅助工具使用。
推荐用途
数据集适用于:
- 训练语言学习对话式AI助手。
- 创建俄语学习应用程序。
- 生成语音和发音练习。
- 教育聊天机器人。
附加信息
许可信息
数据集采用 Community Data License Agreement - Sharing 1.0 许可协议。
使用案例
- 语言学习应用程序:集成到移动或Web应用程序中。
- AI导师:训练俄语虚拟导师。
- 语音助手:辅助正确发音的工具。
- 教育材料:生成练习和测验。
贡献
欢迎对数据集做出贡献。新增条目、修正语法规则或改进语音转写的建议均受欢迎。
联系
[待添加联系信息或GitHub仓库链接]
搜集汇总
数据集介绍
构建方式
在语言学习资源日益数字化的背景下,俄语到塞尔维亚语助手数据集的构建聚焦于为塞尔维亚语使用者提供结构化的俄语学习材料。其构建过程始于收集俄语常用短语和表达,这些内容经过精心筛选,以确保与学习者的实际需求紧密相关。随后,每条俄语条目均被赋予三项关键注释:采用塞尔维亚语语音规则进行音译的准俄语转写、准确的塞尔维亚语语义翻译,以及针对发音细节的详尽语法规则说明。这种多层次的标注策略旨在系统性地桥接两种斯拉夫语言在语音和语法上的差异,为后续的教育应用奠定坚实基础。
特点
该数据集的核心特点在于其专为塞尔维亚语使用者设计的语音辅助体系。它不仅提供标准的双语对照,更创造性地引入了基于塞尔维亚语字母和音系规则的准俄语音译,直观地展示了俄语发音在塞尔维亚语使用者听感中的近似形态。此外,每条数据均附有细致的发音规则解释,涵盖如元音弱化、软硬辅音等关键语音现象,将抽象的语言学知识转化为具体的学习指导。这种将原始文本、语音转写、语义翻译及规则解析融于一体的设计,使其超越了传统平行语料库,成为一个集成化的语言学习知识库。
使用方法
该数据集主要服务于语言教育技术领域,其使用方法多样且具有针对性。开发者可将其用于训练专注于俄语教学的对话式人工智能助手,使模型能够生成包含发音指导的互动回应。教育科技公司则可整合数据至移动或网络应用程序,用于生成语音练习、语法测验等个性化学习材料。对于研究者而言,数据集为探索跨斯拉夫语言的语音迁移和机器辅助发音教学提供了有价值的资源。在实际部署时,建议将其作为标准语言课程的补充工具,并注意其样本量有限及语音转写可能存在的方言变体,以优化学习效果。
背景与挑战
背景概述
在语言学习与计算语言学交叉领域,针对特定语言对的教育资源开发一直是促进跨文化交流的关键。Russian to Serbian Assistant数据集应运而生,专为塞尔维亚语母语者学习俄语而设计。该数据集由致力于斯拉夫语言教育技术的研究者或机构创建,核心研究问题聚焦于如何利用结构化数据,特别是融合语音转录与语法规则,来辅助塞尔维亚学习者克服俄语发音与理解障碍。其价值在于弥合同属斯拉夫语系的俄语与塞尔维亚语之间的语言学差异,为开发智能化语言学习助手提供了专门化的训练素材,从而在教育技术领域推动了针对小语种对的个性化学习方案发展。
当前挑战
该数据集旨在解决的领域挑战,主要围绕俄语作为外语的教学难题,特别是针对塞尔维亚学习者的发音准确性、语法规则内化以及语境化理解。构建过程中的挑战则体现在多个层面:首先,数据规模有限(不足1000例),制约了模型训练的广度与泛化能力;其次,语音转录需精准适配塞尔维亚语的音系特征,并兼顾方言变体带来的转录一致性难题;此外,语法规则的标注要求深厚的语言学专业知识,以确保解释的准确性与教育有效性;最后,数据集的应用场景高度特定化,可能限制其向其他语言学习者群体的扩展潜力。
常用场景
经典使用场景
在斯拉夫语言学习与跨语言交流的背景下,该数据集为塞尔维亚语母语者学习俄语提供了经典的语言辅助场景。它通过结合俄语原文、塞尔维亚语音标转写及详细发音规则,构建了一个结构化的语言学习框架,特别适用于初学者掌握俄语发音和基础语法。这种设计使得学习者能够直观理解俄语与塞尔维亚语之间的语音对应关系,从而在语言习得过程中降低认知负荷,提升学习效率。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在智能教育助手与跨语言语音处理模型的开发。研究者基于其结构化标注,训练了专注于俄语发音纠正的对话式AI,并扩展了多模态学习框架,整合语音合成与识别技术。同时,该数据集也促进了斯拉夫语系间机器翻译模型的优化,特别是在音系特征迁移方面的探索,为低资源语言处理提供了参考范例。
数据集最近研究
最新研究方向
在斯拉夫语言学习与跨语言技术融合的背景下,俄语至塞尔维亚语助手数据集正推动着多模态语言教育模型的发展。该数据集通过整合语音转录与语法规则注释,为构建具备实时发音纠正功能的智能导师系统提供了关键支持,尤其在低资源语言对的应用中展现出潜力。当前研究聚焦于利用该数据集训练端到端的神经机器翻译模型,以优化塞尔维亚语使用者的俄语习得体验,同时探索其在跨文化对话生成与语音合成领域的适应性,旨在弥合斯拉夫语族间的语言鸿沟,并促进教育公平与语言多样性保护。
以上内容由遇见数据集搜集并总结生成


