openai/graphwalks
收藏Hugging Face2025-04-14 更新2025-05-31 收录
下载链接:
https://hf-mirror.com/datasets/openai/graphwalks
下载链接
链接失效反馈官方服务:
资源简介:
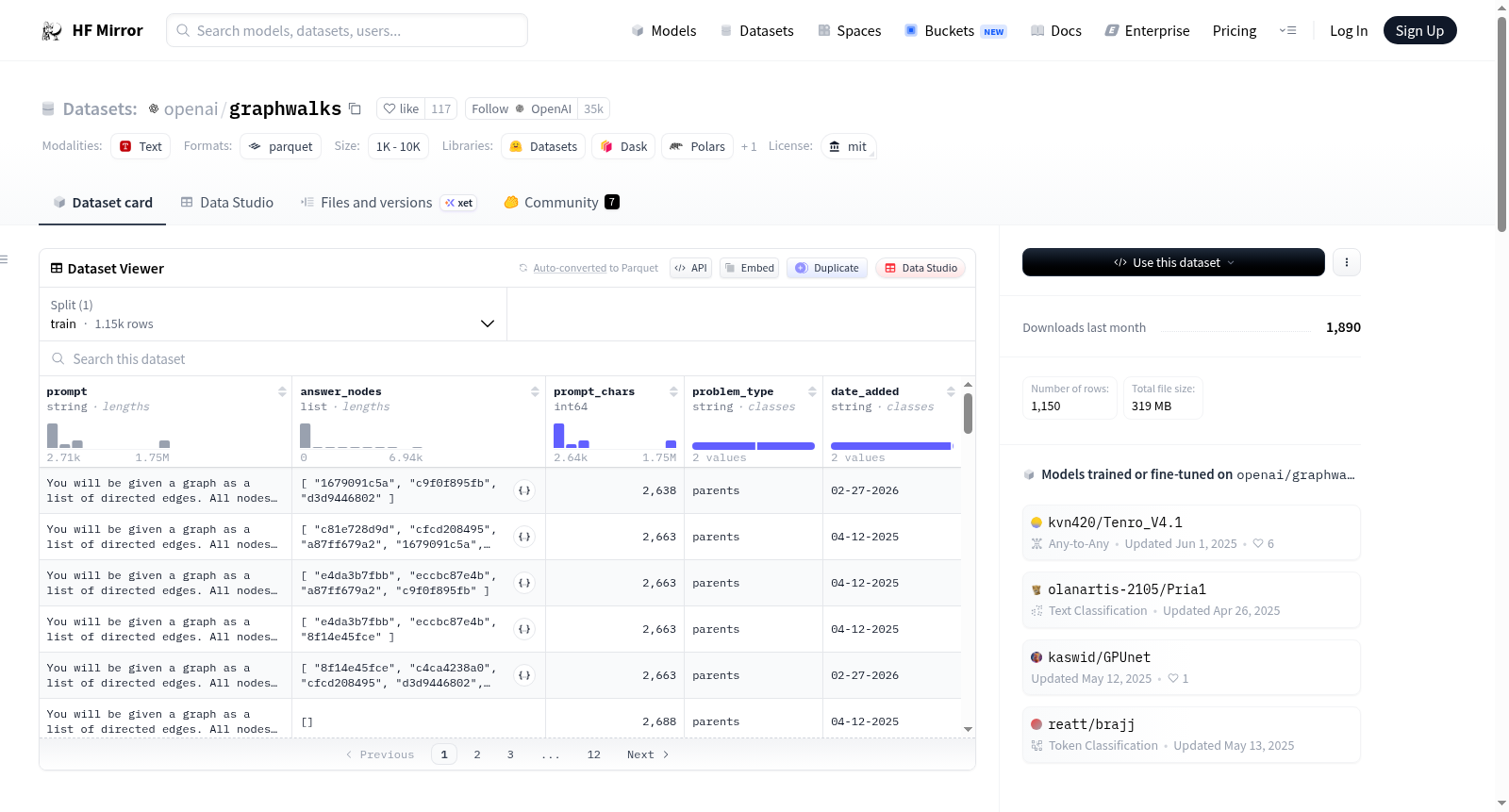
GraphWalks数据集是一个多跳推理的长上下文基准。它提供了一个图的边列表,并要求模型执行如广度优先搜索(BFS)或查找特定节点的父节点等操作。数据集包含四列:提示(包含图的边列表和要执行的操作)、答案(模型应该返回的节点ID列表)、提示字符数以及问题类型(广度优先搜索或查找父节点)。
GraphWalks is a multi-hop reasoning long context benchmark. It provides a graph represented by its edge list and requires the model to perform operations such as breadth-first search (BFS) or finding the parents of a specific node. The dataset consists of four columns: prompt (including the graphs edge list and the operation to be performed), answer (a list of node IDs that the model should respond with), prompt characters, and problem type (either BFS or parents).
提供机构:
openai
搜集汇总
数据集介绍
构建方式
GraphWalks数据集由OpenAI构建,旨在评估语言模型在多跳推理与长上下文理解方面的能力。其核心设计围绕图结构数据展开:每个样本包含一个由有向边列表表示的图,并附带一个具体操作指令,如广度优先搜索(BFS)或父节点查询。构建时,数据集通过预定义的生成流程产生图结构和对应的标准答案,确保操作结果精确且可验证。为增强模型泛化性,提示模板采用三样本示例(3-shot)引导,随后呈现目标图与操作描述。数据以列式格式存储,涵盖提示文本、答案节点列表、提示字符数及问题类型等字段,便于后续分析与评测。
特点
该数据集具有鲜明的结构性与挑战性特征。首先,图规模与深度可灵活调节,支持不同长度上下文的测试,如128K及更短版本,从而评估模型在信息密集场景下的表现。其次,问题类型明确划分为BFS与父节点查询两类,聚焦于图论中的基础推理任务,避免语义歧义。此外,数据集在发布后经过严谨的Bug修复,修正了部分父节点样本中根节点被错误包含的问题,并澄清了BFS中重复节点的处理规则,确保评测的公平性与准确性。最终,答案提取与评分采用严格的F1指标,兼顾召回率与精确率,全面反映模型输出质量。
使用方法
使用GraphWalks数据集时,用户需将每个样本的提示字段作为模型输入,该提示包含图边列表、操作描述及示例。模型应生成以“Final Answer:”开头的最后一行,后接节点列表。通过提供的Python代码可提取答案:取响应末行,利用正则表达式匹配列表内容,并处理空列表等边界情况。随后,将预测节点集与标准答案集计算重叠数量,进而得出召回率、精确率及F1分数,以评估模型性能。该流程支持自动化批量评测,适用于对比不同模型在多跳推理任务上的表现。
背景与挑战
背景概述
GraphWalks数据集由OpenAI于2025年4月发布,旨在评估和推动大语言模型在多跳推理与长上下文理解方面的能力。该数据集的核心研究问题聚焦于模型能否基于给定的图结构(以边列表形式呈现)精确执行广度优先搜索(BFS)或节点父节点查找等图操作。不同于传统自然语言推理基准,GraphWalks将图论中的经典算法任务转化为语言模型可处理的文本形式,从而检验模型对结构化信息的长程依赖与逻辑演绎能力。这一设计填补了现有基准在复杂符号推理与长上下文结合领域的空白,对提升语言模型在科学计算、知识图谱推理等应用场景中的可信度具有重要影响。
当前挑战
GraphWalks数据集所面对的挑战具有双重维度。在领域问题层面,它直指语言模型在多跳推理任务中的根本性局限:模型需从无序的边列表中准确提取拓扑关系,并在深度递增的BFS场景中避免因节点重复访问或路径遗漏导致的错误。构建过程中,数据生成面临两大难点:一是确保图结构的多样性,避免因图规模或连通性模式单一而引入偏差;二是设计无歧义的提示模板,如早期版本曾因BFS中“可达节点”的语义模糊性导致模型输出与预期不符,后续通过明确“仅返回指定深度节点”修正了这一缺陷。此外,长上下文下的性能退化问题也是评估的关键挑战。
常用场景
经典使用场景
GraphWalks数据集专为评估大语言模型在多跳推理与长上下文理解方面的能力而设计。其核心任务基于图结构数据,要求模型根据给定的有向边列表,执行广度优先搜索(BFS)或父节点查找等图论操作。这一经典使用场景模拟了现实世界中需要串联多条信息、进行逻辑推演的复杂推理任务,例如在知识图谱中追溯实体间关系、在程序分析中追踪数据流路径等。通过提供3-shot示例与清晰的指令格式,该数据集不仅检验模型对结构化信息的解析能力,更考验其在长文本中维持注意力并准确执行规则的能力。
衍生相关工作
GraphWalks的发布催生了多个方向的研究工作。一方面,研究者基于该数据集开发了专门的推理增强技术,如引入图神经网络作为外部记忆模块,或将链式思维提示与图遍历算法相结合。另一方面,该数据集的bug修复记录(如父节点样本标注错误)促使社区反思评测数据的质量控制流程,推动了更严谨的基准构建方法。此外,OpenAI在GPT-4.1技术报告中引用该数据集作为长上下文能力的验证案例,彰显了其在模型迭代评估中的标杆地位。
数据集最近研究
最新研究方向
GraphWalks数据集聚焦于评估和提升大语言模型在多跳推理与长上下文理解中的能力,通过图结构化的边列表与多步操作任务(如广度优先搜索与父节点查询)来检验模型对复杂拓扑关系的逻辑演绎水平。当前前沿研究正借助该基准探索模型在长序列环境下对结构化信息的保持与精确检索,其设计直指大模型在知识图谱推理、程序合成及多步规划等热点应用中的核心瓶颈。该数据集的发布不仅为衡量模型的长上下文推理稳健性提供了标准化测试,更推动了关于提示工程、答案抽取与评估指标(如F1分数)的精细化讨论,对领域内构建更可靠、更透明的推理系统具有重要的方法论意义。
以上内容由遇见数据集搜集并总结生成


