有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
WinoBias 是一个专注于性别偏见的 Winograd 模式数据集,用于共指消解。该语料库包含 Winograd 模式风格的句子,其中实体对应于由其职业(如护士、医生、木匠)指代的人。
底层任务是共指消解。
英语
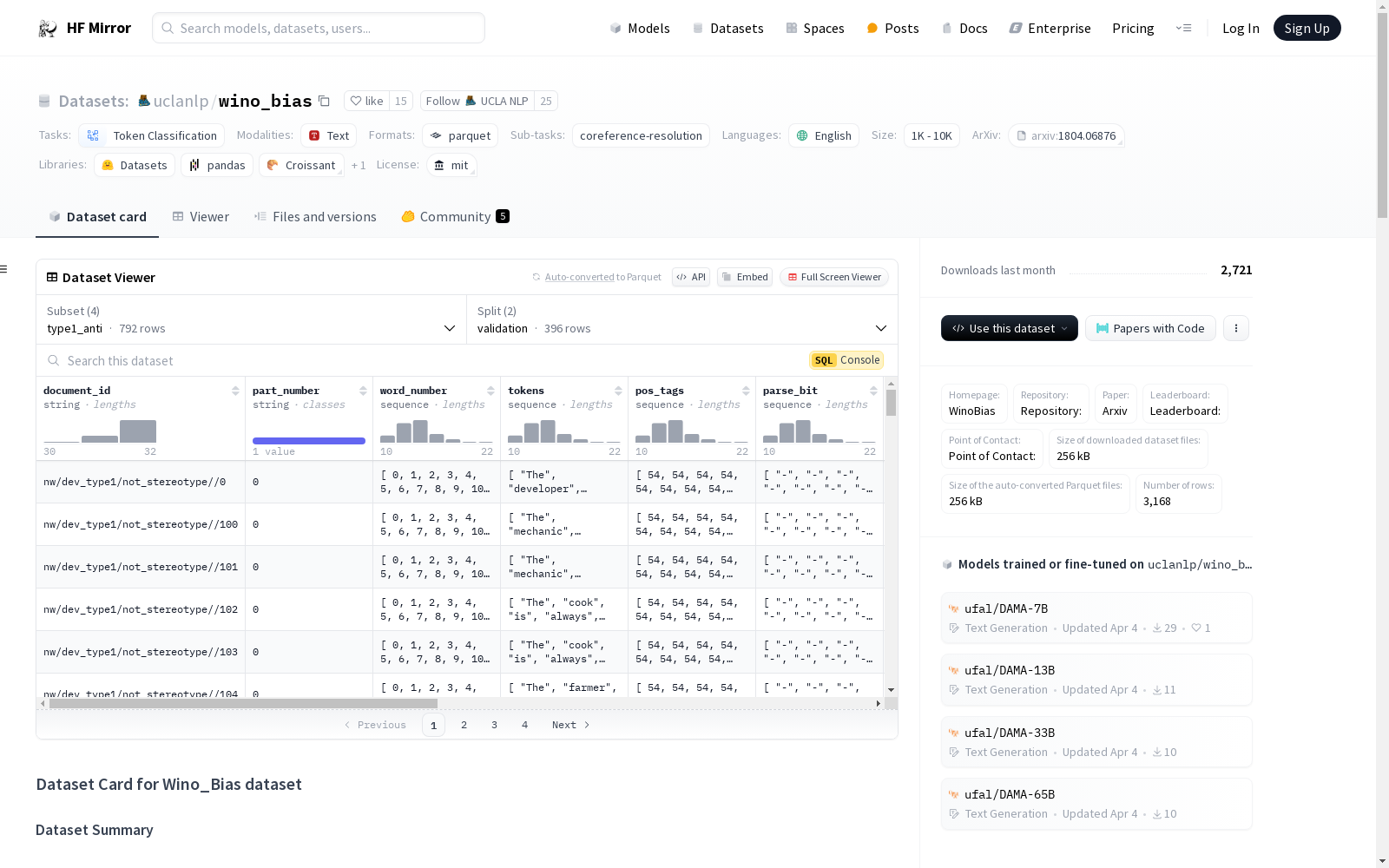
数据集包含 4 个子集:type1_pro、type1_anti、type2_pro 和 type2_anti。
*_pro 子集包含强化性别刻板印象的句子(如机械师是男性,护士是女性),而 *_anti 数据集包含“反刻板印象”的句子(如机械师是女性,护士是男性)。type1(WB-Knowledge)子集包含需要世界知识来解析共指的句子,而 type2(WB-Syntax)子集只需要句子中存在的句法信息来解析它们。document_id:这是文档文件名的变体。part_number:某些文件分为多个部分,编号为 000、001、002 等。word_num:这是该句子中单词的索引。tokens:这是 Treebank 中分词/标记的令牌。pos_tags:这是宾州树库风格的词性。当解析信息缺失时,除有某些意义或命题注释的词性外,所有词性都标记为 XX 标签。动词仅标记为 VERB 标签。parse_bit:这是在解析中第一个开括号之前断开的括号结构,并将 word/part-of-speech 叶子替换为 。完整解析可以通过将星号替换为 "([pos] [word])" 字符串(或叶子)并连接该列的行中的项目来创建。当解析信息缺失时,句子的第一个词标记为 "(TOP",最后一个词标记为 ")",所有中间词标记为 ""。predicate_lemma:对于我们有语义角色信息或词义信息的行,提到谓词词条。所有其他行标记为 "-"。predicate_framenet_id:这是 predicate_lemma 中谓词的 PropBank 框架集 ID。word_sense:这是列 tokens 中单词的词义。speaker:这是可用的说话者或作者名称。ner_tags:这些列标识表示各种命名实体的跨度。对于没有命名实体注释的文档,每行用 "*" 表示。verbal_predicates:对于 predicate_lemma 中提到的谓词,有一列谓词论元结构信息。如果句子中没有标记谓词,则这是单列,所有行标记为 "*"。提供开发和测试分割。
WinoBias 数据集于 2018 年引入(参见 论文),其原始任务是 共指消解,该任务旨在识别指代相同实体或人的提及。
[更多信息需要]
数据集由熟悉 WinoBias 项目的研究人员创建,基于作者提供的两个原型模板,其中实体以合理的方式互动。
[更多信息需要]
熟悉 [WinoBias] 项目的研究人员。
GME Data
关于2021年GameStop股票活动的数据,包括每日合并的GME短期成交量数据、每日失败交付数据、可借股数、期权链数据以及不同时间框架的开盘/最高/最低/收盘/成交量条形图。
github 收录
GAOKAO-Bench
GAOKAO-Bench是由复旦大学计算机科学与技术学院创建的数据集,涵盖了2010至2022年间中国高考的所有科目题目,共计2811题。该数据集包含1781道客观题和1030道主观题,题型多样,包括单选、填空、改错、开放性问题等。数据集通过自动化脚本和人工标注将PDF格式的题目转换为JSON文件,数学公式则转换为LATEX格式。GAOKAO-Bench旨在为大型语言模型提供一个全面且贴近实际应用的评估基准,特别是在解决中国高考相关问题上的表现。
arXiv 收录
中国1km分辨率逐月降水量数据集(1901-2023)
该数据集为中国逐月降水量数据,空间分辨率为0.0083333°(约1km),时间为1901.1-2023.12。数据格式为NETCDF,即.nc格式。该数据集是根据CRU发布的全球0.5°气候数据集以及WorldClim发布的全球高分辨率气候数据集,通过Delta空间降尺度方案在中国降尺度生成的。并且,使用496个独立气象观测点数据进行验证,验证结果可信。本数据集包含的地理空间范围是全国主要陆地(包含港澳台地区),不含南海岛礁等区域。为了便于存储,数据均为int16型存于nc文件中,降水单位为0.1mm。 nc数据可使用ArcMAP软件打开制图; 并可用Matlab软件进行提取处理,Matlab发布了读入与存储nc文件的函数,读取函数为ncread,切换到nc文件存储文件夹,语句表达为:ncread (‘XXX.nc’,‘var’, [i j t],[leni lenj lent]),其中XXX.nc为文件名,为字符串需要’’;var是从XXX.nc中读取的变量名,为字符串需要’’;i、j、t分别为读取数据的起始行、列、时间,leni、lenj、lent i分别为在行、列、时间维度上读取的长度。这样,研究区内任何地区、任何时间段均可用此函数读取。Matlab的help里面有很多关于nc数据的命令,可查看。数据坐标系统建议使用WGS84。
国家青藏高原科学数据中心 收录
CliMedBench
CliMedBench是一个大规模的中文医疗大语言模型评估基准,由华东师范大学等机构创建。该数据集包含33,735个问题,涵盖14个核心临床场景,主要来源于顶级三级医院的真实电子健康记录和考试练习。数据集的创建过程包括专家指导的数据选择和多轮质量控制,确保数据的真实性和可靠性。CliMedBench旨在评估和提升医疗大语言模型在临床决策支持、诊断和治疗建议等方面的能力,解决医疗领域中模型性能评估的不足问题。
arXiv 收录
RAVDESS
情感语音和歌曲 (RAVDESS) 的Ryerson视听数据库包含7,356个文件 (总大小: 24.8 GB)。该数据库包含24位专业演员 (12位女性,12位男性),以中性的北美口音发声两个词汇匹配的陈述。言语包括平静、快乐、悲伤、愤怒、恐惧、惊讶和厌恶的表情,歌曲则包含平静、快乐、悲伤、愤怒和恐惧的情绪。每个表达都是在两个情绪强度水平 (正常,强烈) 下产生的,另外还有一个中性表达。所有条件都有三种模态格式: 纯音频 (16位,48kHz .wav),音频-视频 (720p H.264,AAC 48kHz,.mp4) 和仅视频 (无声音)。注意,Actor_18没有歌曲文件。
OpenDataLab 收录