uclanlp/wino_bias
收藏Hugging Face2024-01-04 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/uclanlp/wino_bias
下载链接
链接失效反馈官方服务:
资源简介:
WinoBias是一个专注于性别偏见的Winograd-schema数据集,用于共指消解任务。该语料库包含Winograd-schema风格的句子,其中实体通过其职业(如护士、医生、木匠)来指代。数据集包含四个子集:`type1_pro`、`type1_anti`、`type2_pro`和`type2_anti`。`*_pro`子集包含强化性别刻板印象的句子(例如,机械师是男性,护士是女性),而`*_anti`子集包含“反刻板印象”的句子(例如,机械师是女性,护士是男性)。`type1`(*WB-Knowledge*)子集包含需要世界知识来解决共指的句子,而`type2`(*WB-Syntax*)子集仅需要句子中的句法信息来解决共指。
WinoBias是一个专注于性别偏见的Winograd-schema数据集,用于共指消解任务。该语料库包含Winograd-schema风格的句子,其中实体通过其职业(如护士、医生、木匠)来指代。数据集包含四个子集:`type1_pro`、`type1_anti`、`type2_pro`和`type2_anti`。`*_pro`子集包含强化性别刻板印象的句子(例如,机械师是男性,护士是女性),而`*_anti`子集包含“反刻板印象”的句子(例如,机械师是女性,护士是男性)。`type1`(*WB-Knowledge*)子集包含需要世界知识来解决共指的句子,而`type2`(*WB-Syntax*)子集仅需要句子中的句法信息来解决共指。
提供机构:
uclanlp
原始信息汇总
数据集卡片 for Wino_Bias 数据集
数据集描述
数据集概述
WinoBias 是一个专注于性别偏见的 Winograd 模式数据集,用于共指消解。该语料库包含 Winograd 模式风格的句子,其中实体对应于由其职业(如护士、医生、木匠)指代的人。
支持的任务和排行榜
底层任务是共指消解。
语言
英语
数据集结构
数据实例
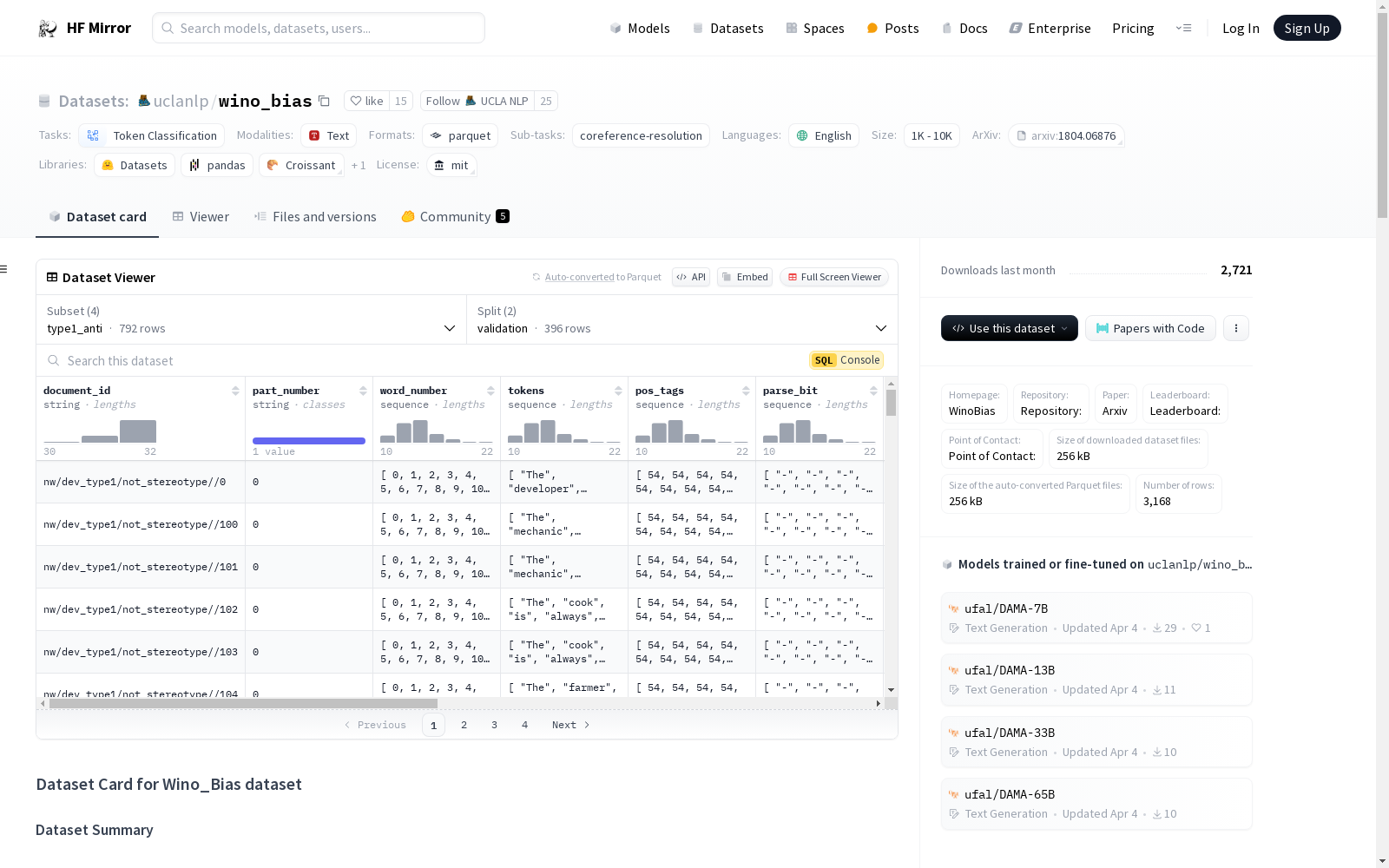
数据集包含 4 个子集:type1_pro、type1_anti、type2_pro 和 type2_anti。
*_pro子集包含强化性别刻板印象的句子(如机械师是男性,护士是女性),而*_anti数据集包含“反刻板印象”的句子(如机械师是女性,护士是男性)。type1(WB-Knowledge)子集包含需要世界知识来解析共指的句子,而type2(WB-Syntax)子集只需要句子中存在的句法信息来解析它们。
数据字段
document_id:这是文档文件名的变体。part_number:某些文件分为多个部分,编号为 000、001、002 等。word_num:这是该句子中单词的索引。tokens:这是 Treebank 中分词/标记的令牌。pos_tags:这是宾州树库风格的词性。当解析信息缺失时,除有某些意义或命题注释的词性外,所有词性都标记为 XX 标签。动词仅标记为 VERB 标签。parse_bit:这是在解析中第一个开括号之前断开的括号结构,并将 word/part-of-speech 叶子替换为 。完整解析可以通过将星号替换为 "([pos] [word])" 字符串(或叶子)并连接该列的行中的项目来创建。当解析信息缺失时,句子的第一个词标记为 "(TOP",最后一个词标记为 ")",所有中间词标记为 ""。predicate_lemma:对于我们有语义角色信息或词义信息的行,提到谓词词条。所有其他行标记为 "-"。predicate_framenet_id:这是 predicate_lemma 中谓词的 PropBank 框架集 ID。word_sense:这是列 tokens 中单词的词义。speaker:这是可用的说话者或作者名称。ner_tags:这些列标识表示各种命名实体的跨度。对于没有命名实体注释的文档,每行用 "*" 表示。verbal_predicates:对于 predicate_lemma 中提到的谓词,有一列谓词论元结构信息。如果句子中没有标记谓词,则这是单列,所有行标记为 "*"。
数据分割
提供开发和测试分割。
数据集创建
策划理由
WinoBias 数据集于 2018 年引入(参见 论文),其原始任务是 共指消解,该任务旨在识别指代相同实体或人的提及。
源数据
初始数据收集和规范化
[更多信息需要]
源语言生产者是谁?
数据集由熟悉 WinoBias 项目的研究人员创建,基于作者提供的两个原型模板,其中实体以合理的方式互动。
注释
注释过程
[更多信息需要]
注释者是谁?
熟悉 [WinoBias] 项目的研究人员。
搜集汇总
数据集介绍
构建方式
WinoBias数据集的构建基于Winograd模式,专注于性别偏见的共指消解任务。该数据集由专家生成,包含四个子集:type1_pro、type1_anti、type2_pro和type2_anti。type1子集要求世界知识来解析共指,而type2子集仅依赖句法信息。每个子集包含验证和测试分割,旨在评估模型在处理性别偏见时的表现。
特点
WinoBias数据集的显著特点在于其专注于性别偏见,通过提供强化和反强化性别刻板印象的句子,帮助模型识别和纠正偏见。数据集包含详细的词性标签、命名实体识别标签和共指集群信息,为研究者提供了丰富的语义和句法特征。此外,数据集的多样性和专家生成的高质量注释确保了其在共指消解任务中的实用性和可靠性。
使用方法
使用WinoBias数据集时,研究者可以加载不同的配置文件(如type1_pro、type1_anti等)来访问相应的数据分割。数据集提供了多种特征,包括文档ID、词序号、词性标签、命名实体标签等,这些特征可用于训练和评估共指消解模型。通过分析模型在不同子集上的表现,研究者可以深入理解模型在处理性别偏见时的行为,并开发出更加公正和准确的语言模型。
背景与挑战
背景概述
WinoBias数据集由UCL NLP团队于2018年创建,旨在解决自然语言处理中的性别偏见问题。该数据集专注于共指消解任务,通过提供包含性别偏见的Winograd模式句子,帮助研究人员识别和纠正模型中的性别偏见。主要研究人员包括来自UCL NLP团队的专家,他们通过构建和标注数据集,推动了性别偏见检测与消除的研究进展。WinoBias的引入对自然语言处理领域产生了深远影响,促使研究者更加关注模型在性别平等方面的表现。
当前挑战
WinoBias数据集面临的挑战主要集中在性别偏见的检测与消除上。首先,构建过程中需要精心设计包含性别偏见的句子,确保数据集能够有效揭示模型中的性别偏见。其次,数据集的标注过程需要高度专业化的知识,以确保标注的准确性和一致性。此外,如何利用该数据集训练模型,使其在实际应用中减少性别偏见,也是一个重要的研究课题。这些挑战不仅涉及技术层面,还触及社会伦理和公平性问题。
常用场景
经典使用场景
WinoBias数据集的经典使用场景主要集中在性别偏见检测与消除领域。研究者们利用该数据集评估和改进自然语言处理模型,特别是那些涉及指代消解(coreference resolution)的模型,以识别和纠正模型在性别相关词汇上的偏见。通过对比'type1_pro'和'type1_anti'等不同配置的数据,研究者能够更精确地分析模型在处理性别刻板印象时的表现,从而推动更公平和无偏见的AI系统的发展。
实际应用
在实际应用中,WinoBias数据集被广泛用于开发和测试能够处理性别偏见的自然语言处理工具。例如,在招聘系统、客户服务聊天机器人和内容推荐算法中,使用WinoBias数据集训练的模型能够更公平地处理涉及性别的内容,减少潜在的歧视风险。此外,该数据集还支持在教育和技术培训中,帮助开发者和学生理解并解决AI系统中的性别偏见问题。
衍生相关工作
WinoBias数据集的发布激发了一系列相关研究和工作。例如,研究者们基于该数据集开发了新的偏见检测算法,并提出了多种方法来消除模型中的性别偏见。此外,WinoBias还促进了跨学科的合作,包括心理学和社会学,以更全面地理解和解决AI中的性别偏见问题。这些衍生工作不仅提升了AI技术的公平性,还为未来的研究提供了宝贵的资源和方向。
以上内容由遇见数据集搜集并总结生成


