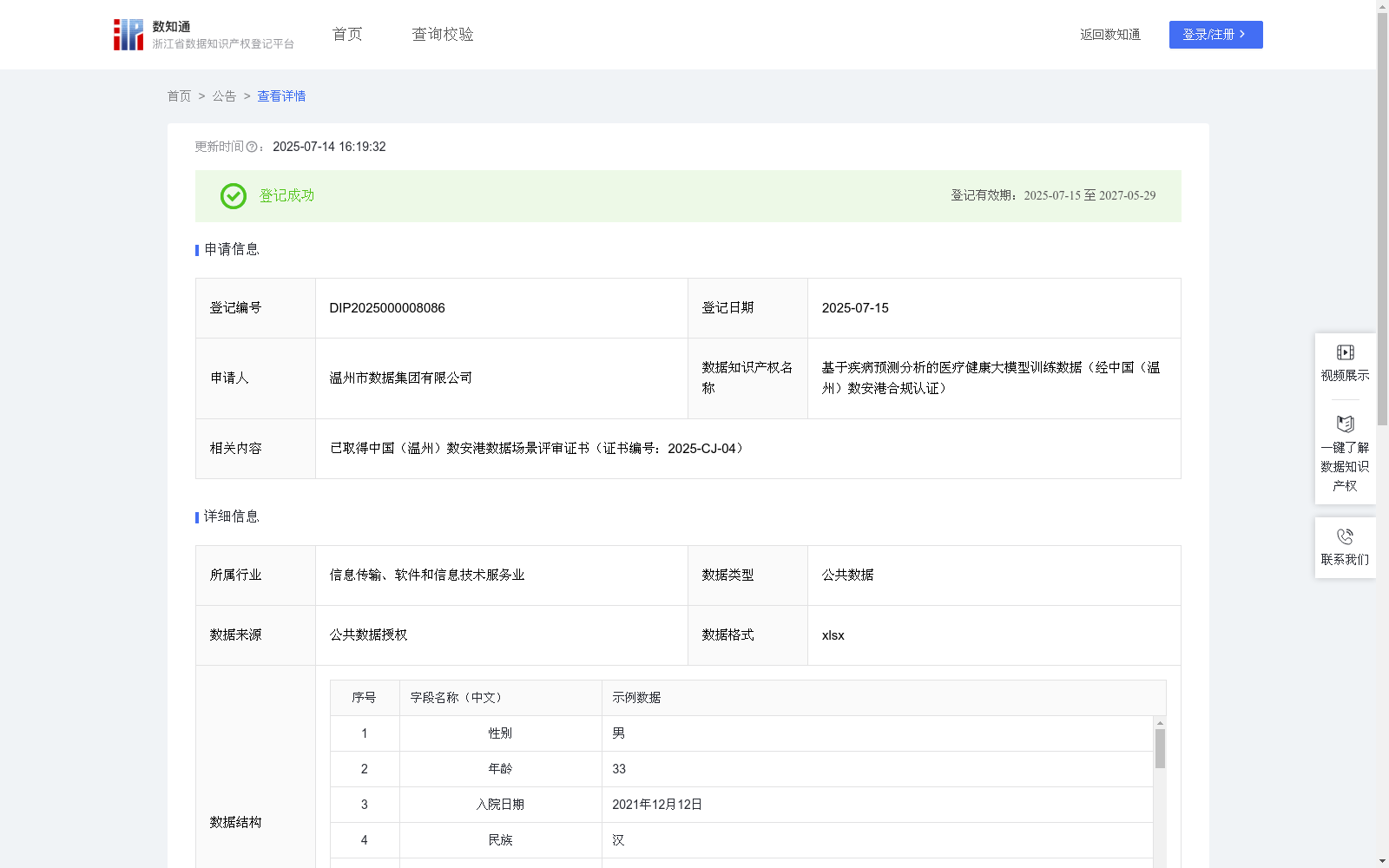
基于疾病预测分析的医疗健康大模型训练数据(经中国(温州)数安港合规认证)
收藏浙江省数据知识产权登记平台2025-07-14 更新2025-07-15 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/148650
下载链接
链接失效反馈官方服务:
资源简介:
高质量公共数据训练集为生成式病历提供了基础支撑,从而推动生成式病历发展,实现自动生成结构化、标准化且遵循医学规范的病历文本,切实提高病历生成的效率与质量,有力推动医疗服务的优化升级,并为医学研究的深入发展提供关键助力。基于以上场景需求,整合相关医疗数据构建形成可供该场景训练使用的公共数据语料库。本项目所使用的数据来源于公共数据授权运营域,具体而言,是医院方上传至该授权域的相关数据内容。面对这些初始时可能较为分散和非结构化的原始数据,运用了先进的算法进行处理。核心方法是对病程内容的不同类型进行数据内容提取:首先,构建一批经过专业标注的提取数据集;然后,利用强大的Transformer模型架构,结合交叉熵损失函数,对这些数据进行微调,从而训练出能够精准识别并提取特定信息的模型。以手术记录为例,会先从文本中标注出关键的手术名称”,以此作为训练样本,微调出一个专门提取手术名称的模型,随后再用这个模型高效地批量处理大量手术记录,自动提取出所需的手术名称。经过这样的精细加工,原本复杂的数据会根据不同的病程类型(如手术记录、出院小结等)转化为结构清晰、格式统一的标准化数据。例如,处理后的手术记录将明确包含术前诊断、手术名称、术中及术后诊断、麻醉方式、手术经过及处理、手术小结等关键要素。这些标准化数据不仅为未来开发智能生成式病历应用提供了坚实的数据基础,支撑其自动生成高质量病历报告,同时也极具价值,可作为宝贵语料用于训练其他大模型。其核心在于,通过海量数据的深度学习,AI模型能够掌握语言规律、理解领域知识,从而显著提升其识别、分类、生成和推理能力。这些数据堪称AI模型的“燃料”,其质量直接决定了模型的性能表现和泛化能力。最终,本项目将输出经过充分训练和优化的AI模型权重文件,这些文件封装了模型学习到的所有能力,可直接应用于实际场景。
High-quality public training datasets provide foundational support for generative medical records, advancing their development by enabling the automatic generation of structured, standardized, clinically compliant medical note texts. This effectively improves the efficiency and quality of medical record generation, strongly promotes the optimization and upgrading of medical services, and provides critical assistance for the in-depth development of medical research.
To meet the requirements of the above scenarios, a public data corpus for training in this context is constructed by integrating relevant medical data. The data used in this project originates from the public data authorized operation domain; specifically, it refers to the relevant data content uploaded to this authorized domain by hospitals.
Facing these initially scattered and unstructured raw data, advanced algorithms are employed for processing. The core method involves extracting data content from different types of medical course records: first, a batch of professionally annotated extraction datasets is constructed; then, the powerful Transformer model architecture, combined with the cross-entropy loss function, is used to fine-tune these data, thereby training a model capable of accurately identifying and extracting specific information.
Taking surgical records as an example, key surgical names are first annotated from the texts, which serve as training samples to fine-tune a model dedicated to extracting surgical names. Subsequently, this model is used to efficiently batch-process a large volume of surgical records and automatically extract the required surgical names.
After such meticulous processing, the originally complex data is converted into clearly structured, uniformly formatted standardized data based on different types of medical course records, such as surgical records, discharge summaries, etc. For instance, the processed surgical records will explicitly include key elements such as preoperative diagnosis, surgical name, intraoperative and postoperative diagnosis, anesthesia method, surgical procedure and management, and surgical summary.
These standardized data not only provide a solid data foundation for the future development of intelligent generative medical record applications, supporting their automatic generation of high-quality medical reports, but also hold great value as precious corpora for training other large language models (LLMs). The core lies in that through deep learning on massive data, AI models can master linguistic laws and understand domain knowledge, thereby significantly improving their capabilities in recognition, classification, generation and reasoning.
These data can be regarded as the "fuel" for AI models, whose quality directly determines the model's performance and generalization ability.
Ultimately, this project will output fully trained and optimized AI model weight files, which encapsulate all the capabilities learned by the model and can be directly applied to real-world scenarios.
提供机构:
温州市数据集团有限公司
创建时间:
2025-06-18
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于疾病预测分析的医疗健康大模型训练数据,包含621条结构化病历记录,每月更新。数据经过专业算法处理,支持生成式病历的自动生成,适用于医疗服务和医学研究场景。
以上内容由遇见数据集搜集并总结生成


