EmergencyDialogue
收藏Hugging Face2026-05-06 更新2026-05-07 收录
下载链接:
https://huggingface.co/datasets/Areej0/EmergencyDialogue
下载链接
链接失效反馈官方服务:
资源简介:
EmergencyDialogue SFT 数据集是一个用于大型语言模型监督微调(SFT)的对话数据集,采用 ChatML 格式。数据集包含英语和阿拉伯语的对话数据,适用于指令调优、聊天机器人训练、对话建模和对话式 AI 研究。数据集以 JSONL 格式提供,每条记录代表一个对话,包含消息对象列表,每个消息对象有角色(system、user、assistant)和内容字段。该格式兼容 OpenAI ChatML 格式、Hugging Face 对话微调流程以及 transformers、trl 和 llama-factory 等库。数据集规模在 1 万到 10 万条之间。使用示例包括使用 Hugging Face Datasets 加载数据集和使用 Transformers 进行训练。数据集的主要用途包括监督微调、指令跟随模型和基于聊天的应用。需要注意的是,某些领域特定短语可能无法完美映射到英语,且不保证事实准确性。数据集采用 Apache 2.0 许可证发布。
创建时间:
2026-05-04
原始信息汇总
数据集概述
📌 基本信息
- 数据集名称:EmergencyDialogue SFT Dataset
- 语言:英语 / 阿拉伯语
- 许可证:Apache 2.0
- 数据规模:10K 到 100K 条记录
- 任务类别:文本生成、对话系统
- 标签:对话式、ChatML、指令微调、SFT、对话
📂 数据结构
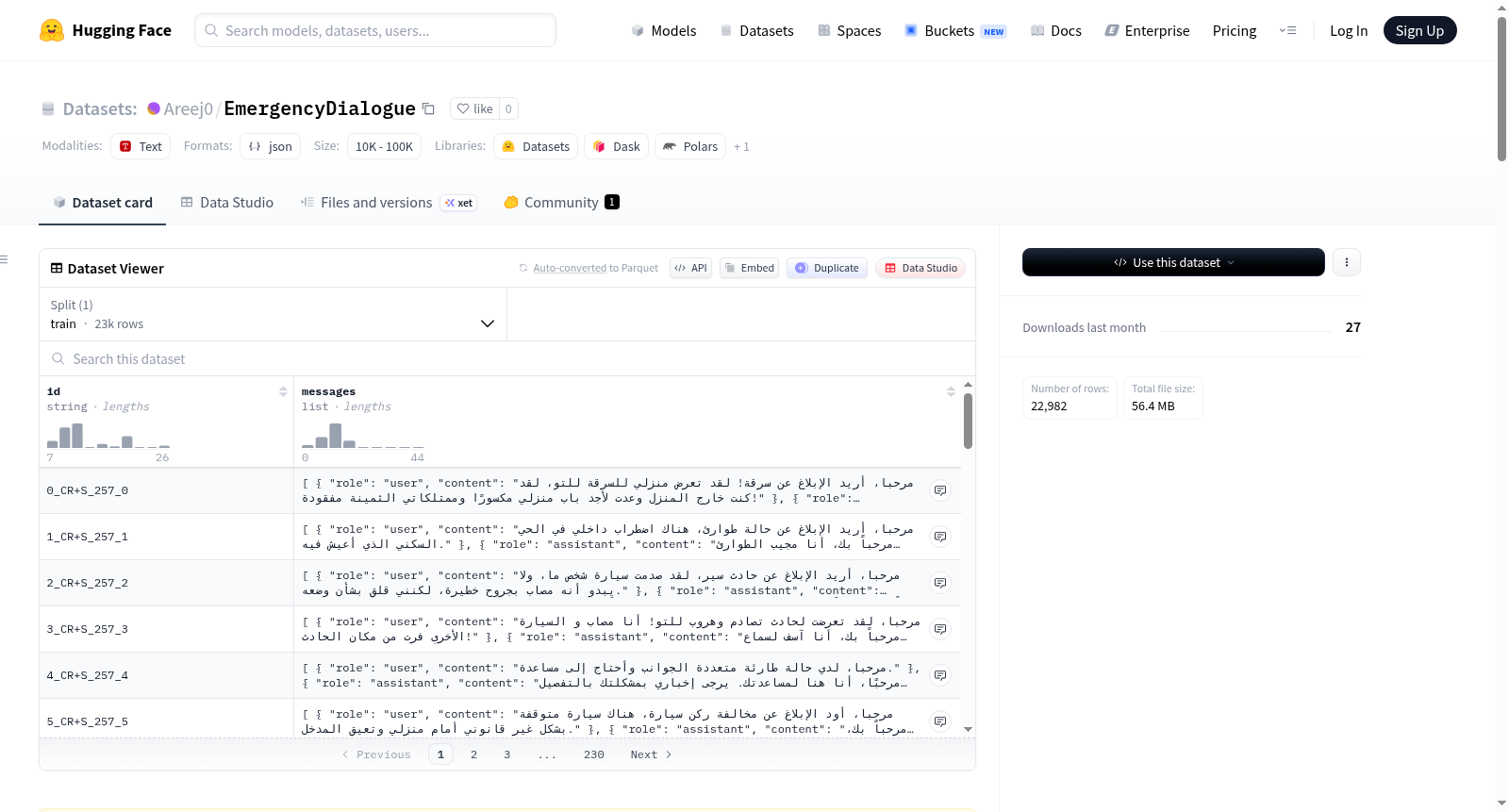
数据集以 JSONL 格式 提供,每一行代表一段对话。每条记录包含:
- messages:消息列表,包含多个消息对象:
- role:角色,可选值为:
system、user、assistant - content:消息文本内容(英语)
- role:角色,可选值为:
数据示例
json { "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello"}, {"role": "assistant", "content": "Hi! How can I help you?"} ] }
🎯 适用场景
- 监督式微调(SFT)
- 指令微调
- 聊天机器人训练
- 对话建模
- 对话式 AI 研究
⚙️ 使用方法
使用 Hugging Face Datasets 加载
python from datasets import load_dataset dataset = load_dataset("YOUR_USERNAME/YOUR_DATASET_NAME") print(dataset["train"][0])
训练示例(Transformers)
python from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("model-name")
def format_chat(example): return tokenizer.apply_chat_template(example["messages"], tokenize=False)
dataset = dataset.map(lambda x: {"text": format_chat(x)})
⚠️ 局限性与说明
- 部分领域特定短语可能无法完美映射为英语
- 不保证事实准确性
🔐 许可证
Apache 2.0 License
🙌 致谢
- EmergencyDialogue 团队
- 数据标注团队
搜集汇总
数据集介绍
构建方式
EmergencyDialogue数据集以ChatML格式构建,适用于大型语言模型的监督微调。数据以JSONL格式存储,每一行代表一段完整的对话,包含system、user和assistant三种角色的消息对象。这种结构化的对话形式能够清晰地捕捉系统指令、用户查询与模型回应之间的交互关系,为对话系统的训练提供了高度规范化的数据基础。数据覆盖英文与阿拉伯语,体现出对多语种对话场景的关照。
特点
该数据集的核心特色在于其对话格式的标准化与兼容性。采用ChatML格式使得数据能够与OpenAI的对话模板、Hugging Face的微调流程以及transformers、trl、llama-factory等主流工具库无缝对接。每条记录均通过message字段封装角色与内容信息,结构简洁且易于扩展。数据集规模介于一万至十万条之间,兼具丰富性与可控性,适用于指令微调、聊天机器人训练及对话建模等多种研究任务。
使用方法
用户可通过Hugging Face的datasets库直接加载该数据集,使用load_dataset函数即可获取训练集数据。在具体微调过程中,可借助AutoTokenizer的apply_chat_template方法将对话数据格式化为模型可接受的文本序列,从而无缝嵌入基于Transformers的训练流程。方法简洁高效,降低了数据预处理的技术门槛,便于研究者和开发者快速开展监督微调实验。
背景与挑战
背景概述
EmergencyDialogue数据集由EmergencyDialogue团队和Data Annotator团队于近期构建并发布,采用Apache 2.0许可证,主要面向英文和阿拉伯语双语场景。该数据集专注于对话系统的监督微调(SFT),以ChatML格式组织多轮交互数据,旨在提升大语言模型在指令遵循和对话建模方面的能力。在应急响应、多语种客服及低资源语言对话系统的研究背景下,EmergencyDialogue为探索跨语言对话智能提供了关键的训练资源,尤其推动了阿拉伯语对话AI的发展,对多语种自然语言处理领域具有重要影响。
当前挑战
当前该数据集面临的主要挑战包括:1)在领域问题层面,数据集旨在解决应急场景下多语种对话系统的指令遵循与事实准确性难题,但特定领域短语可能无法完美映射到目标语言,影响模型在关键任务中的可靠性;2)构建过程中,数据标注团队需确保双语一致性,避免翻译歧义,同时由于不保证事实正确性,数据质量需严格审查以降低模型幻觉风险;此外,规模限于10K-100K样本,可能不足以覆盖复杂应急对话的多样性,限制了模型的泛化能力。
常用场景
经典使用场景
EmergencyDialogue数据集以对话形式组织,采用ChatML格式,专为监督微调(SFT)场景设计。其经典应用在于训练大语言模型以生成符合指令要求的对话响应。研究人员常将此类数据集用于提升模型在多轮对话中的上下文理解与连贯应答能力,尤其适用于构建多语种(如英语与阿拉伯语)的通用对话助手。该数据集的结构化格式天然适配Transformers、TRL等主流训练框架,使得指令微调过程高效且可复现。
实际应用
实际应用中,EmergencyDialogue数据集可用于快速构建面向客服、教育或紧急咨询的对话机器人。开发者可基于该数据集微调模型,使其掌握特定领域的应答逻辑与礼貌用语,从而部署在智能助手或呼叫中心系统中。其轻量化的结构(10K至100K样本)亦适合资源受限的场景,例如嵌入式设备上的对话系统开发,或在少量样本下实现模型快速适配特定用户群体。
衍生相关工作
该数据集衍生了若干经典工作方向,例如基于ChatML模板的对话生成优化研究、多语种指令微调的数据增强策略探索。受到该数据集启发的相关工作包括:面向低资源语言的对话模型迁移学习、结合监督微调与强化学习的混合对齐方法,以及针对紧急对话场景的专用语料库构建。这些工作进一步拓展了EmergencyDialogue在对话AI领域的学术与工业价值。
以上内容由遇见数据集搜集并总结生成


