Malaysian-Emilia
收藏Hugging Face2025-12-06 更新2025-12-07 收录
下载链接:
https://huggingface.co/datasets/malaysia-ai/Malaysian-Emilia
下载链接
链接失效反馈官方服务:
资源简介:
马来西亚Emilia数据集是从两个不同的HuggingFace数据集收集而来,并经过静音修剪和语音转换的排列处理,包括排列过程中的后过滤。该数据集包含参考音频、参考文本、目标音频和目标文本等特征,主要用于语音处理和转换任务。
创建时间:
2025-12-05
原始信息汇总
Malaysian Emilia 数据集概述
数据集基本信息
- 数据集名称: Malaysian Emilia
- 托管地址: https://huggingface.co/datasets/malaysia-ai/Malaysian-Emilia
- 默认配置: default
数据来源
本数据集通过整合以下两个数据集并经过处理得到:
- https://huggingface.co/datasets/mesolitica/Malaysian-Emilia-v2
- https://huggingface.co/datasets/Scicom-intl/Malaysian-Chinese-Emilia
数据处理流程
- 静音修剪: 对音频进行静音修剪处理。
- 语音转换排列: 进行语音转换排列,并在排列过程中包含后置滤波。
数据集结构
特征字段
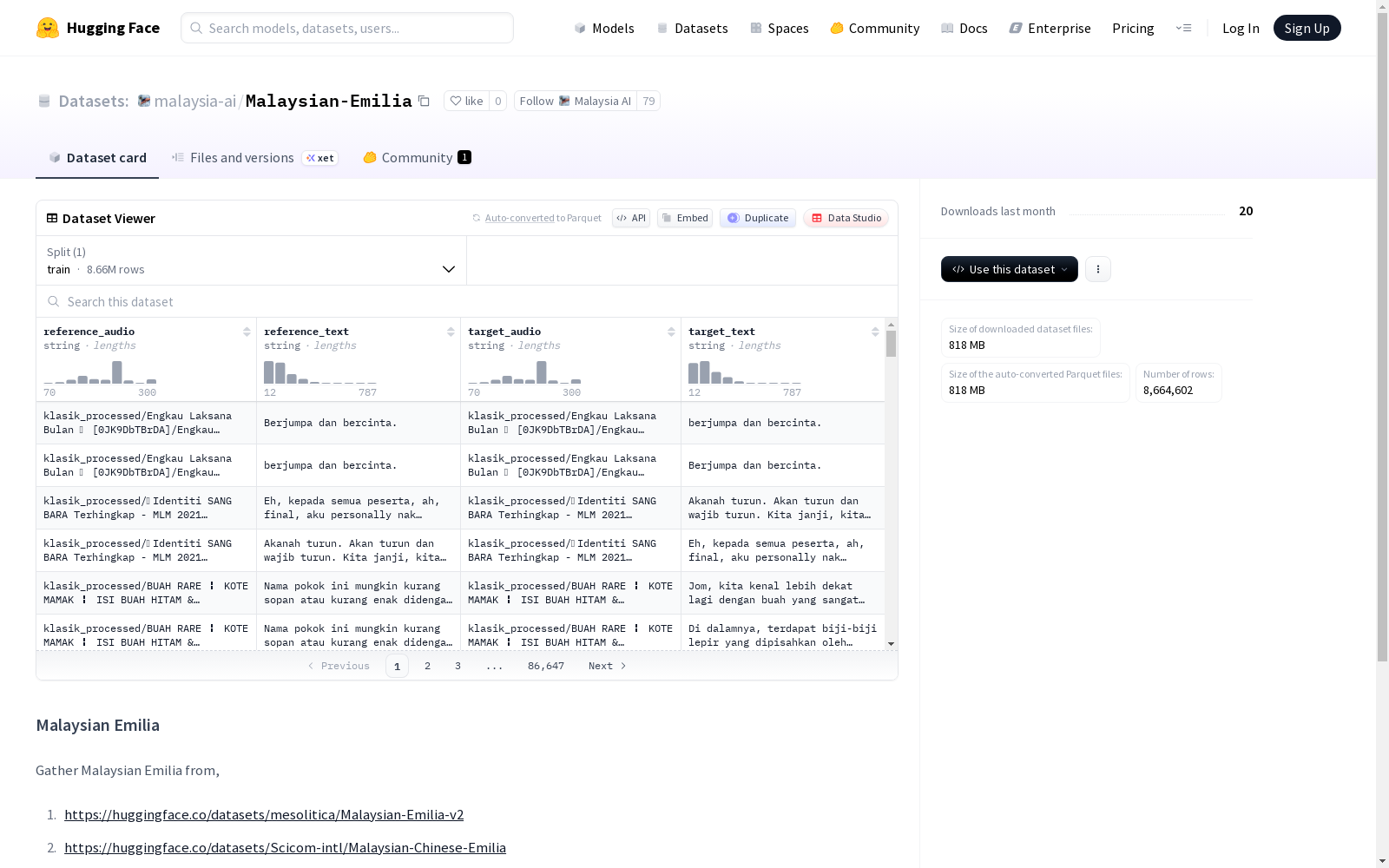
reference_audio: 参考音频,数据类型为字符串。reference_text: 参考文本,数据类型为字符串。target_audio: 目标音频,数据类型为字符串。target_text: 目标文本,数据类型为字符串。
数据划分
- 训练集:
- 样本数量: 8,664,602 条
- 数据大小: 7,285,025,442 字节
下载与存储信息
- 下载大小: 817,749,796 字节
- 数据集大小: 7,285,025,442 字节
搜集汇总
数据集介绍
构建方式
在语音合成与转换领域,数据集的构建质量直接影响模型性能。Malaysian-Emilia数据集通过整合两个公开来源——mesolitica/Malaysian-Emilia-v2与Scicom-intl/Malaysian-Chinese-Emilia,形成了统一的语音语料库。构建过程中,对原始音频进行了静音修剪处理,以消除无声音段带来的噪声干扰;同时实施了语音转换所需的排列操作,并在排列阶段引入了后过滤机制,确保语音片段的自然连贯与高质量对齐,从而为模型训练提供了结构清晰、纯净度高的语音数据基础。
特点
该数据集的核心特征体现在其规模与结构设计上。它包含了超过866万条训练样本,总数据量约7.3GB,具备充足的语音多样性以支持复杂模型训练。每条样本均包含参考音频、参考文本、目标音频与目标文本四个关键字段,这种配对结构特别适用于语音转换、语音克隆及跨语言语音合成等任务。数据经过静音修剪与后过滤优化,语音片段纯净度高,文本与音频对齐准确,为研究人员提供了可直接用于端到端语音处理模型的高质量、多模态语料资源。
使用方法
在语音技术研究中,该数据集主要应用于语音转换与合成模型的训练与评估。使用者可通过HuggingFace平台直接加载数据集,利用其提供的参考与目标音频-文本对,构建基于深度学习的语音风格迁移或语音生成模型。典型流程包括:加载训练分割数据,提取音频特征与对应文本嵌入,设计编码器-解码器架构进行映射学习。由于数据已预处理,研究者可专注于模型设计与调优,无需额外处理静音或对齐问题,从而加速实验迭代并提升语音合成系统的自然度与鲁棒性。
背景与挑战
背景概述
在语音合成与语音转换技术快速发展的背景下,马来西亚语语音数据资源相对稀缺,制约了相关模型的本土化应用。Malaysian-Emilia数据集由Mesolitica与Scicom-intl等机构合作构建,旨在汇集高质量的马来西亚语语音样本,通过整合多个来源的原始数据并进行精细化处理,如静音修剪与语音转换排列,为语音技术研究提供了关键的多模态语料支持。该数据集聚焦于提升低资源语言的语音合成质量,推动了语音人工智能在多元语言环境中的适应性发展。
当前挑战
该数据集致力于解决马来西亚语语音合成与转换中的低资源挑战,包括语音质量一致性、口音多样性建模以及跨说话人泛化能力等核心问题。在构建过程中,研究人员面临数据采集的复杂性,需从分散来源整合原始音频,并实施静音修剪与后滤波等预处理步骤,以确保语音信号的纯净度与连贯性。此外,语音转换排列的技术实现要求高效的算法设计,以平衡数据增强效果与计算成本,这些挑战共同凸显了低资源语言数据处理的技术瓶颈。
常用场景
经典使用场景
在语音技术领域,马来西亚语语音数据资源相对稀缺,Malaysian-Emilia数据集通过提供大量高质量的马来语和中文语音对,为语音转换研究奠定了重要基础。该数据集最经典的使用场景是训练端到端的语音转换模型,特别是基于深度学习的声码器和特征提取方法,能够实现跨语言或跨说话人的语音风格迁移,为多语言语音合成与识别提供关键支持。
实际应用
在实际应用中,Malaysian-Emilia数据集被广泛用于开发智能语音助手、多语言客服系统和语音翻译工具,特别是在马来西亚及周边地区的商业和教育场景中。它支持个性化语音合成,帮助残障人士通过语音接口进行交流,并促进了本地化语音技术的普及,提升了语音交互的自然度与可访问性。
衍生相关工作
基于Malaysian-Emilia数据集,衍生了一系列经典研究工作,包括端到端语音转换模型的优化、跨语言语音合成系统的开发,以及低资源语言语音识别算法的改进。这些工作不仅推动了语音处理技术的进步,还为多语言语音数据集的构建提供了方法论参考,促进了相关开源工具和社区的发展。
以上内容由遇见数据集搜集并总结生成


